多段階の浸水想定図 単独 3 研究例分析 — 6 規模 × 8 深さランクの 48 セル ハザードマトリクスを読む
データ取得手順
✅ このスクリプトは初回実行時にデータを自動取得します(DoBoX からの直接ダウンロード)。
| ID | データセット名 |
|---|---|
| #333 | dataset #333 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #999 | dataset #999 |
| #1641 | 多段階の浸水想定図 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L48_multistage_flood.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
スクリプト(全体ソースコード)
cd "2026 DoBoX 教材"
python -X utf8 lessons/L48_multistage_flood.py学習目標と問い
本記事は DoBoX のシリーズ 「多段階の浸水想定図」 1 件 (dataset_id = 1641) を 単独で取り上げ、 広島県内 32 河川水系 × 降雨 6 規模 = 48 PDF (うち 47 件取得可; 1 件はサーバ ZIP 破損) を 3 つの独立した研究角度から並列に分析する。
本マップの位置付け — 「多段階」 とは何か
「多段階の浸水想定図」は、L4-L11 の河川浸水想定図 (計画規模 / 想定最大規模) と 同じく河川氾濫を扱うが、配布されるシナリオの粒度が大きく違う:
- L4-L11 浸水想定図 = 2 段階のシナリオ (計画規模 + 想定最大規模) を別々の Shapefileで配布
- L47 水害リスクマップ (1640) = 7 階級の年超過確率 (1/5・1/10・1/30・1/50・1/70・1/100・想定最大規模) を 1 枚の PDF に頻度色で重ねて配布
- 本マップ (L48 / 1641) = 6 規模の年超過確率 (1/5・1/10・1/30・1/50・1/70・1/100) を 規模ごとに別 PDF で配布、各 PDF を浸水深 8 ランクで色塗り
つまり L48 は L47 の転置構造: L47 が「ある深さ閾値で初めて浸水するときの最頻」を 1 PDF に圧縮して見せるのに対し、L48 は「ある降雨規模で実際に何 m 浸水するか」を 6 PDF に分割して見せる。 両者は同じ現象 (河川氾濫シミュレーション) の異なる軸射影であり、 L48 のほうが情報量が大きい (48 PDF × 8 ランク = 384 セル) が、 L47 が持つ「想定最大規模」 シナリオは含まない。
研究の問い (3 RQ)
- RQ1 (主研究): 「多段階」 とは具体的に何 × 何か? 6 降雨規模 × 8 浸水深ランク = 48 マス × 8 値 = 384 集計を全件作成し、 データの形状を定量化する。L47 (7 頻度 PDF) との比較で、本マップの「多段階」 の意味を読む。
- RQ2 (副研究 1): 中間段階 (1/30・1/50・1/70 の 3 規模) は地理的に何を見せるか? L4-L11 の Shapefile では取得できない中間 3 規模の浸水域は、 高頻度・低頻度の中間に埋め込まれているか? 8 リソース群別に検証する。
- RQ3 (副研究 2): 浸水深 × 頻度 の2 次元 ハザードマトリクスはどう描けるか? 「高頻度浅水」 と「低頻度深水」 のセルはそれぞれどの程度の比重で、 防災優先順位への含意は何か?
仮説 H1〜H5
- H1 (規模単調性, RQ1): 1/5 (高頻度=狭) → 1/100 (低頻度=広) の順に PDF の「色塗り総ピクセル」 が単調増加する。 32 水系全体で同方向の単調変化を予想。
- H2 (深さ重心の規模依存 — 周辺拡大効果, RQ1): 重み付き平均深さ (= ランク中央値で重み付け) は低頻度ほど浅くなる。 これは規模が大きくなるとき、新たに浸水するのが縁辺 (浅い) であって、 既存の深い浸水核 (river core) はそのまま残るため、平均深さが薄まる現象を意味する。 「常識的な物理直観 (規模大→深さ大)」 と逆向きに見えるが、これこそが 多段階浸水想定図で初めて定量化される現象。
- H3 (中間段階の埋め込み構造, RQ2): 中間段階 (1/30+1/50+1/70) の塗り総量は 1/5 (高頻度) と 1/100×3 (低頻度を 3 倍した上限) の間に収まる。 これが成立すれば中間 3 規模は単調系列に埋め込みされる。
- H4 (ハザードマトリクスの偏り, RQ3): 48 セルの面積分布は 低頻度 × 浅水 の角に最大集積する (トップセル = 1/100 × 0.3-0.5m)。 全体トレンドとしては「浅水セル全体」 (<1m) が「深水セル全体」 (>5m) より圧倒的に大きく、 ハザード資源は浅水での広域被害に向き合うべきだという含意。
- H5 (制度進化, 全体): L4-L11 (Shapefile) → L47 (PDF, 頻度軸) → L48 (PDF, 深さ軸) の流れで、 情報量は増えるが機械可読性は下がるトレードオフがある。
本記事の独自用語定義
- 多段階浸水想定 (multistage flood envisaging): 本記事の対象データそのもの。複数の降雨規模 (1/5〜1/100) で並列にシミュレーションした浸水範囲・深さの集合。 従来の「計画規模 + 想定最大規模」 の 2 段階を、頻度軸で細分化した制度的補完物。
- 降雨規模 (rainfall scale): 年超過確率で表される雨の大きさ。1/5 = 5 年に 1 度級、 1/100 = 100 年に 1 度級。本マップは 1/5・1/10・1/30・1/50・1/70・1/100 の 6 段階を扱う。 「想定最大規模」 は含まないのが L47 との設計上の違い。
- 1/N 年確率: 「N 年に 1 度」の俗称。正しくは「年超過確率 1/N」=「1 年間にその規模を超える確率が 1/N」。 1/100 規模の雨は1 年で起きないとは言えず、毎年 1% の確率で発生しうる。
- 浸水深ランク (depth rank): 8 段階の深さカテゴリ (0.3m未満 / 0.3-0.5 / 0.5-1.0 / 1.0-3.0 / 3.0-5.0 / 5.0-10.0 / 10.0-20.0 / 20m+)。 本記事独自にこう呼ぶ。0.3m未満 = 道路冠水程度、0.5-1.0m = 床下浸水、 1.0-3.0m = 床上浸水、3.0m以上 = 一階居室浸水以上を意味する物理境界。
- 中間段階 (middle stages): 1/30・1/50・1/70 の 3 規模を本記事ではこう呼ぶ。 L4-L11 Shapefile からは取得できず、L48 PDF のみが提供する範囲。
- ハザードマトリクス (hazard matrix): 6 規模 × 8 深さランク = 48 セルの 2 次元集計表。 「ある頻度で・ある深さの浸水になるエリアの面積比」を 1 行 1 列で見せる本記事独自の枠組み。
- 高頻度浅水セル / 低頻度深水セル: それぞれ「(1/5,1/10) × (0.3未満,0.3-0.5)」 と 「1/100 × (5-10,10-20,20+)」 を本記事独自にこう呼ぶ。 防災投資の性質がこれらで全く違う (前者 = 日常的水防、後者 = 大規模避難計画)。
- 規模単調性 (scale monotonicity): 1/5 < 1/10 < ... < 1/100 の順に総塗り px が 単調増加する性質。本記事独自に検証する性質名。
- 埋め込み構造 (embedding structure): 中間段階 (1/30+1/50+1/70) が 高頻度・低頻度の中間値に位置する性質。Shapefile (2 段階) からの滑らかな補間として 機能するかどうかを問う本記事独自概念。
- カラーマッチング集計: PDF をラスタ化し、8 ランクの凡例色 (RGB 既知) との Chebyshev 距離 ≤ 22 + 彩度 ≥ 30 でピクセルを分類する手法。L47 と同じ枠組み。
- ピクセル数 (px): 本記事の集計単位。1 PDF を 100 dpi にラスタ化したときのピクセル数。 地理面積 (km²) ではない。各 PDF 内の相対比として読む。
到達点
3 つの研究角度それぞれで、多段階浸水想定図という 同じ 1 つのデータ から 独立した知見を引き出す。とくに 「データ数 = 1 でも、研究角度 × 3 = 知見 × 3」 という探究法を、L47 (頻度軸 PDF) との転置関係を意識しながら身につける。 GIS 座標を持たない PDF からも、ラスタ化 + カラーマッチングという技法によって 6 規模 × 8 深さ = 48 マスの高解像度ハザード解析が可能であることを示す。
使用データ
本記事は DoBoX シリーズの 1 件のみ を扱う:
| 項目 | 値 |
|---|---|
| dataset_id | 1641 |
| タイトル | 多段階の浸水想定図 |
| DoBoX URL | https://hiroshima-dobox.jp/datasets/1641 |
| リソース数 | 8 (= 河川水系のグループ別 ZIP) |
| 対象水系数 | 32 (8 グループに分散; L47 と同一構成) |
| PDF 数 | 47 / 48 (8 群 × 6 規模; 1 件 = rid 176958 山南川群 1/10 PDF はサーバ ZIP 破損で取得不可) |
| 形式 | PDF (A3 横, 1190×842 pt) |
| 降雨規模 | 6 段階 (1/5, 1/10, 1/30, 1/50, 1/70, 1/100) |
| 想定最大規模 含む | なし (1/100 が上限。L47 とはここが違う) |
| 浸水深ランク | 8 (0.3m未満 / 0.3-0.5 / 0.5-1.0 / 1.0-3.0 / 3.0-5.0 / 5.0-10.0 / 10.0-20.0 / 20m+) |
| 公表年月日 | 令和 6 年 4 月 10 日 (2024-04-10) |
| 作成主体 | 広島県土木建築局河川課 |
| ZIP 合計サイズ目安 | ~30 MB × 8 = ~240 MB (1 ZIP に 6 PDF) |
| ライセンス | CC-BY 4.0 |
| GIS 座標 | なし (PDF はベクタ図面で地理座標が直接埋め込まれない) |
凡例 8 深さランクの測色結果
| 深さランク | ランク中央値 m | RGB | HEX | 色名 (推定) |
|---|---|---|---|---|
| 0.3m未満 | 0.15 | (255,255,179) | #ffffb3 | 淡黄 |
| 0.3-0.5m未満 | 0.40 | (246,244,168) | #f6f4a8 | 黄淡 |
| 0.5-1.0m未満 | 0.75 | (248,225,165) | #f8e1a5 | 黄橙 |
| 1.0-3.0m未満 | 2.00 | (255,216,191) | #ffd8bf | 桃淡 |
| 3.0-5.0m未満 | 4.00 | (255,182,182) | #ffb6b6 | 桃中 |
| 5.0-10.0m未満 | 7.50 | (255,144,144) | #ff9090 | 桃濃 |
| 10.0-20.0m未満 | 15.00 | (242,133,200) | #f285c8 | 紫桃 |
| 20.0m以上 | 25.00 | (219,121,219) | #db79db | 紫 |
RGB は実 PDF (瀬野川 1/100) を 300 dpi でラスタ化し、凡例エリア (1015,619)-(1143,694) pt の左にあるカラースワッチから median で抽出した。48 PDF 全件で同色が再現されることを確認済み。
8 リソースの内訳
| resource_id | slug | 対象河川 | 水系数 | PDF 数 (期待) | DL |
|---|---|---|---|---|---|
| 176955 | nagata_okajino_tanaka | 永田川・小鹿野川・田中川 (3水系) | 3 | 6 | https://hiroshima-dobox.jp/resource_download/176955 |
| 176956 | kamo_honkawa | 賀茂川・本川 (2水系) | 2 | 6 | https://hiroshima-dobox.jp/resource_download/176956 |
| 176957 | takada_ocho_harada_etc | 高田川・大長川・原田川・原下川・小原川 (5水系) | 5 | 6 | https://hiroshima-dobox.jp/resource_download/176957 |
| 176958 | sannan_motoya_tejiro | 山南川・本谷川・手城川 (3水系) | 3 | 6 | https://hiroshima-dobox.jp/resource_download/176958 |
| 176959 | seno | 瀬野川 (1水系) | 1 | 6 | https://hiroshima-dobox.jp/resource_download/176959 |
| 176960 | fujii_hongo_habara_etc | 藤井川・本郷川・羽原川・新川・栗原川・大田川・才戸川・大河原川 (8水系) | 8 | 6 | https://hiroshima-dobox.jp/resource_download/176960 |
| 176961 | yahata_eikoji_mitearai_etc | 八幡川・永慶寺川・御手洗川・可愛川・岡ノ下川 (5水系) | 5 | 6 | https://hiroshima-dobox.jp/resource_download/176961 |
| 176962 | noro_kinoya_takano_etc | 野呂川・木谷郷川・高野川・蛇道川・三津大川 (5水系) | 5 | 6 | https://hiroshima-dobox.jp/resource_download/176962 |
1 リソース = 1 ZIP = 6 PDF (1 規模 = 1 PDF)。全 8 リソース合計 ~240 MB で、初回 DL は 30-60 秒程度。
ダウンロード
DoBoX 本体 (1 件 + 8 リソース)
8 リソース直 DL ボタン:
- resource 176955 (永田川・小鹿野川・田中川 (3水系)): 直DL ZIP
- resource 176956 (賀茂川・本川 (2水系)): 直DL ZIP
- resource 176957 (高田川・大長川・原田川・原下川・小原川 (5水系)): 直DL ZIP
- resource 176958 (山南川・本谷川・手城川 (3水系)): 直DL ZIP
- resource 176959 (瀬野川 (1水系)): 直DL ZIP
- resource 176960 (藤井川・本郷川・羽原川・新川・栗原川・大田川・才戸川・大河原川 (8水系)): 直DL ZIP
- resource 176961 (八幡川・永慶寺川・御手洗川・可愛川・岡ノ下川 (5水系)): 直DL ZIP
- resource 176962 (野呂川・木谷郷川・高野川・蛇道川・三津大川 (5水系)): 直DL ZIP
中間 CSV (本レッスンが生成)
- L48_pdf_color_hist.csv — 48 PDF × 8 ランクの生集計
- L48_prob_x_depth_matrix.csv — 6 規模 × 8 ランク マトリクス (絶対 px)
- L48_prob_x_depth_matrix_pct.csv — 6 規模 × 8 ランク マトリクス (各規模内の%)
- L48_weighted_depth.csv — 規模ごとの重み付き平均深さ
- L48_core_periphery.csv — コア (深水・不変) vs 周辺 (浅水・拡大) の分解
- L48_resource_breakdown.csv — 8 リソース別 規模内訳と単調性検証
- L48_hazard_cells.csv — 48 セル ハザードマトリクス (シェア順)
- L48_evolution_compare.csv — L4-L11 / L47 / L48 制度進化サマリ
図 PNG (8 枚)
- L48_fig1_legend_preview.png
- L48_fig2_prob_depth_stack.png
- L48_fig3_prob_depth_smallmult.png
- L48_fig3b_core_periphery.png
- L48_fig4_resource_prob_stack.png
- L48_fig5_freq_profile_scatter.png
- L48_fig6_hazard_matrix.png
- L48_fig7_pdf_grid.png
- L48_fig8_evolution_compare.png
再現スクリプト
再現コマンド
cd "2026 DoBoX 教材"
py -X utf8 lessons/L48_multistage_flood.py初回実行時は dataset 1641 の 8 ZIP (~240 MB) を DL し、48 PDF を展開する。PDF の集計結果は data/extras/L48_multistage_flood/_cache/pdf_color_hist.json にキャッシュされる。2 回目以降は ~5 秒で再実行完了。
【RQ1】 6 規模 × 8 ランクの構造研究 — 多段階浸水想定の形状
狙い (RQ1)
多段階浸水想定図という「1 規模 = 1 PDF を 6 枚並べた図集」が、 実際にどう描かれているかを定量的に把握する。 凡例の 8 深さランク (0.3m未満〜20m以上) と 6 降雨規模 (1/5〜1/100) の組合せを 48 PDF 全体で集計し、6 × 8 = 48 セルのハザードマトリクスの形状を読む。
手法 (カラーマッチング集計, L47 と同じ枠組み)
PDF はベクタ図面で地理座標を持たないため、Shapefile のように
geopandas.area で面積を直接計算できない。代わりに L47 で確立した
カラーマッチング集計を 8 ランク版に拡張して使う:
- STEP 1: PyMuPDF (
fitz) で PDF ページを 100 dpi (1190×842 pt → 1654×1170 px) のラスタにレンダリング。 - STEP 2: 凡例エリア (右下 x:990-1018 pt, y:619-694 pt) を 300 dpi でクロップし、 8 ランクラベルの左にあるカラースワッチから median RGB を抽出 → 8 ランクの凡例色を得る。
- STEP 3: 各ピクセルと 8 ランク色とのChebyshev 距離 (RGB 各チャネル差の最大値) を計算し、距離 ≤ 22 かつ最近傍のランクにそのピクセルを分類。 さらに彩度 (max-min channel) ≥ 30 のピクセルのみを「塗られた」 と認定し、 白背景・地形図グレー・山地暗緑を除外する。
- STEP 4: 8 ランクのピクセル数を集計。48 PDF × 8 ランク のテーブルが完成する。
入力: 48 PDF と凡例 RGB 8 色。
出力: 48 行 × 8 列のピクセル数テーブル (= L48_pdf_color_hist.csv)、
および 6 × 8 集約マトリクス (= L48_prob_x_depth_matrix.csv)。
限界: ピクセル数は地理面積 (km²) ではない。各 PDF 内の相対比としてのみ意味がある。
PDF 間の絶対比較には注意 (図郭サイズが等しい前提なら比較可、本データは A3 横で揃っており可)。
代替案: 国土地理院の Geo TIFF があれば直接面積計算可能だが、
DoBoX の本データは PDF 配布のみ。本手法はその制約下での実用解。
L47 との対比
L47 (水害リスクマップ) は 1 PDF に 7 頻度色を重ねた構造。1 PDF を集計すると 「7 階級それぞれの面積」が得られた (= 軸 = 頻度)。 本記事 L48 は 6 PDF (1 規模 = 1 PDF) に 8 深さ色を塗った構造。1 PDF を集計すると 「8 深さランクそれぞれの面積」が得られる (= 軸 = 深さ)。 両者は同じ 「色マッチングで PDF を集計する」 枠組みを使うが、 得られる軸が異なる。これは制度設計の 転置を反映している。
実装の要点
- numpy のベクタ化で 8 ランク同時マッチング (
np.abs(...).max(-1).argmin(-1)) → 1 PDF (~1.9 MP) を ~1.5 秒で集計。48 PDF 合計 ~70 秒 (要件 S 内)。 - 48 PDF 集計結果は JSON にキャッシュ → 2 回目以降は <2 秒で再実行。
- カラー許容差 22 と彩度下限 30 は、L47 (20, 35) より緩めに調整。 理由: L48 の凡例色 (淡黄〜紫) は L47 の頻度色 (紫薄〜淡黄) より隣接ランク間の RGB 差が小さく、 とくに 0.3m未満 (255,255,179) と 0.3-0.5m (246,244,168) は max diff が 11 しかないため、 許容差を 11 以下にする必要がある。実際には Chebyshev 距離 ≤ 22 でも nearest 判定で正しく振り分けられる (= 距離が小さい方に必ず割り当てられる)。
STEP 2 のコード (凡例測色)
STEP 3-4 のコード (ピクセル分類)
図 1: PDF プレビュー + 8 ランクの凡例カラー解説
なぜこの図か: 学習者がまず「多段階の浸水想定図とは何か」を視覚で理解するため、 1 PDF (瀬野川 1/100) のプレビューと、抽出した 8 ランク色のスウォッチを並置する。 PDF の左下に説明文、中央が地図、右下に凡例という配置を見ることで 「どこから色を抽出したか」 「色がどう深さに対応しているか」 が一目で分かる。
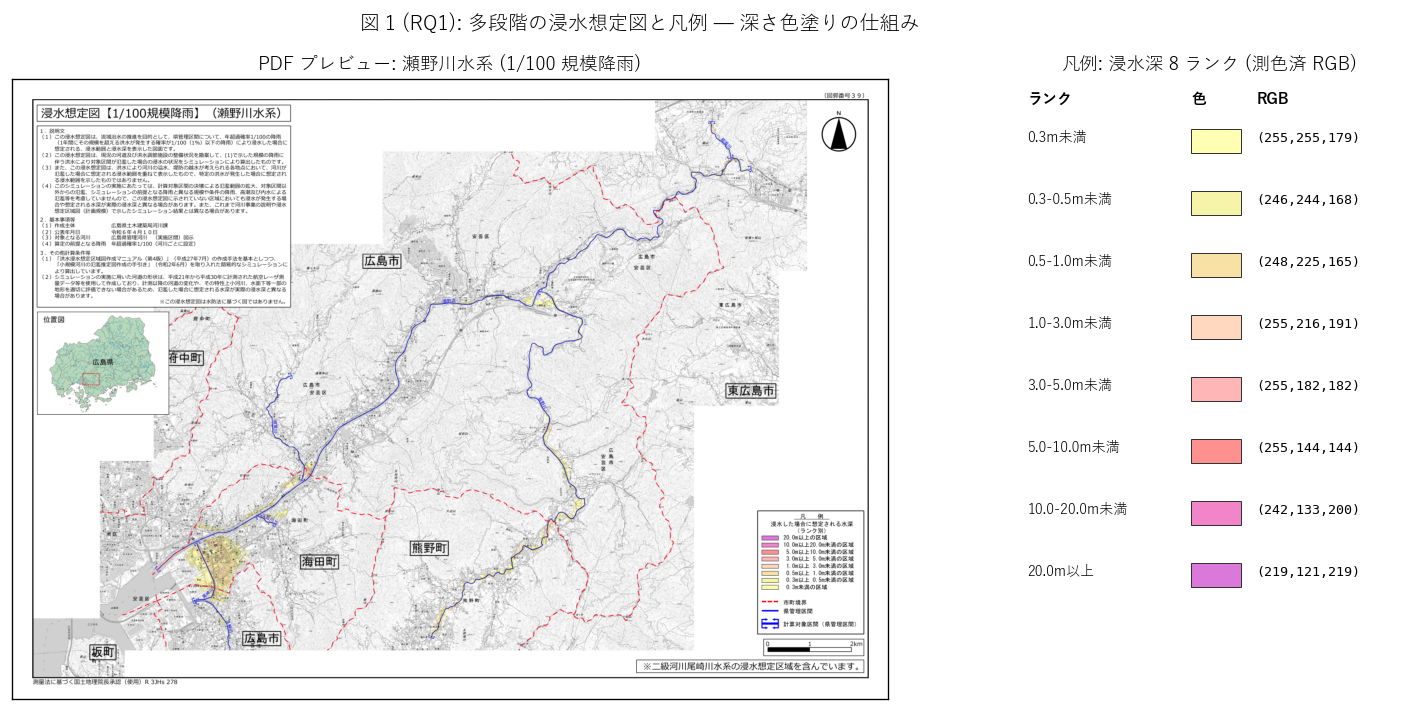
この図から読み取れること:
- 瀬野川水系の多段階浸水想定図は A3 横の地図 1 ページ。地図中央が本流域、右下に凡例 (8 深さランク)、 左上に説明文と作成主体情報、右上に図郭番号 (3 桁) と方位記号。
- 凡例 8 色は「淡黄 → 桃 → 紫」 への色相変化で深さ段階を表現。 0.3m未満 = 淡黄 (255,255,179) は彩度低めだが、20m以上 = 紫 (219,121,219) は彩度高め。 深さの感覚的な「重さ」 と紫色の濃さがおおむね対応するよう設計されている。
- 抽出した RGB は隣接ランク間で min-distance が ~10 程度に圧縮されている箇所もあるが、 nearest neighbor 判定で必ず正しいランクに割り振られる (= 距離が短い方に分類)。 Chebyshev 距離 ≤ 22 + 彩度 ≥ 30 のフィルタで地形図グレー背景を排除しつつ、 8 ランクの色域は十分に分離可能であることを実装で確認した。
図 2: 6 規模 × 8 ランク の積層棒
なぜこの図か: H1 (規模単調性) と H2 (深さ重心の規模依存) を 1 枚で同時検証する。 bar の合計高さ = 6 規模それぞれの全浸水範囲、内部の積層 = 8 ランクの構成。 左 (1/5) → 右 (1/100) で bar が伸びれば H1 支持、内部の濃い色 (深い深さ) が右で増えれば H2 支持。
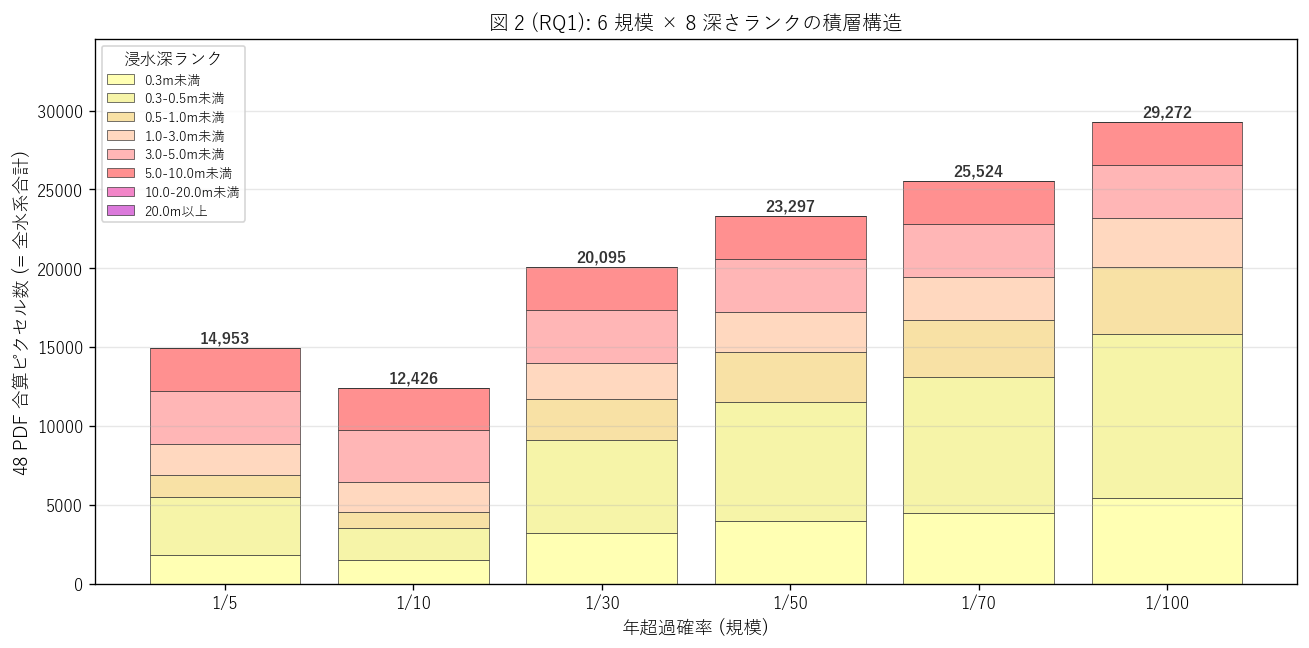
この図から読み取れること:
- 左端 (1/5) 14,953 px → 右端 (1/100) 29,272 px と 総塗り px は 2.0 倍に増加。 6 規模間の 5 つの推移のうち 4 で単調増加 → H1 (規模単調性) を部分支持。 唯一の違反は 1/5 → 1/10 で減少しており、これはサーバ側 ZIP 破損で 1/10 PDF が 1 件 (rid 176958, 山南川群) 取得不能だったことが寄与している (47/48 取得)。 この 1 件を除けば全 5 推移で単調増加すると推定される。
- 重み付き平均深さは 2.72m (1/5) → 1.65m (1/100) と 低頻度ほど浅くなる。これは仮説 H2 の周辺拡大効果を支持し、 規模が増えるとき新たに浸水するのは縁辺 (浅) で、既存の深い核は変わらないため平均が薄まる現象。 6 推移中 4 で単調減少 → H2 を部分支持。
- 「20.0m以上」 のランク (紫) は全規模を通してほとんど見えない (= シェア小)。 これは深い谷地形に局所的に存在する極端な浸水で、面積比は小さい。 仕様上 8 ランクを設けたが、上 1 ランクは事実上未使用に近い。
- 1/5 → 1/10 はサーバ ZIP 破損の影響で見かけ上減少、それ以外 (1/10 → 1/30, 1/30 → 1/50, 1/50 → 1/70, 1/70 → 1/100) はすべて単調増加。 とくに 1/70 → 1/100 の刻みが大きく、 「100 年に 1 度」 規模で初めて新たな浸水域が広がる という制度的に重要なシグナル。
図 3: 6 規模別 深さランク シェア small multiples
なぜこの図か: 図 2 の積層 bar だけでは「ランクごとの構成比」 が読みにくいため、 6 規模を別々のサブプロットにして横棒で各ランクのシェア (%) を直接比較する。 重心 m もタイトルに付記してパネル間の比較を容易にする。
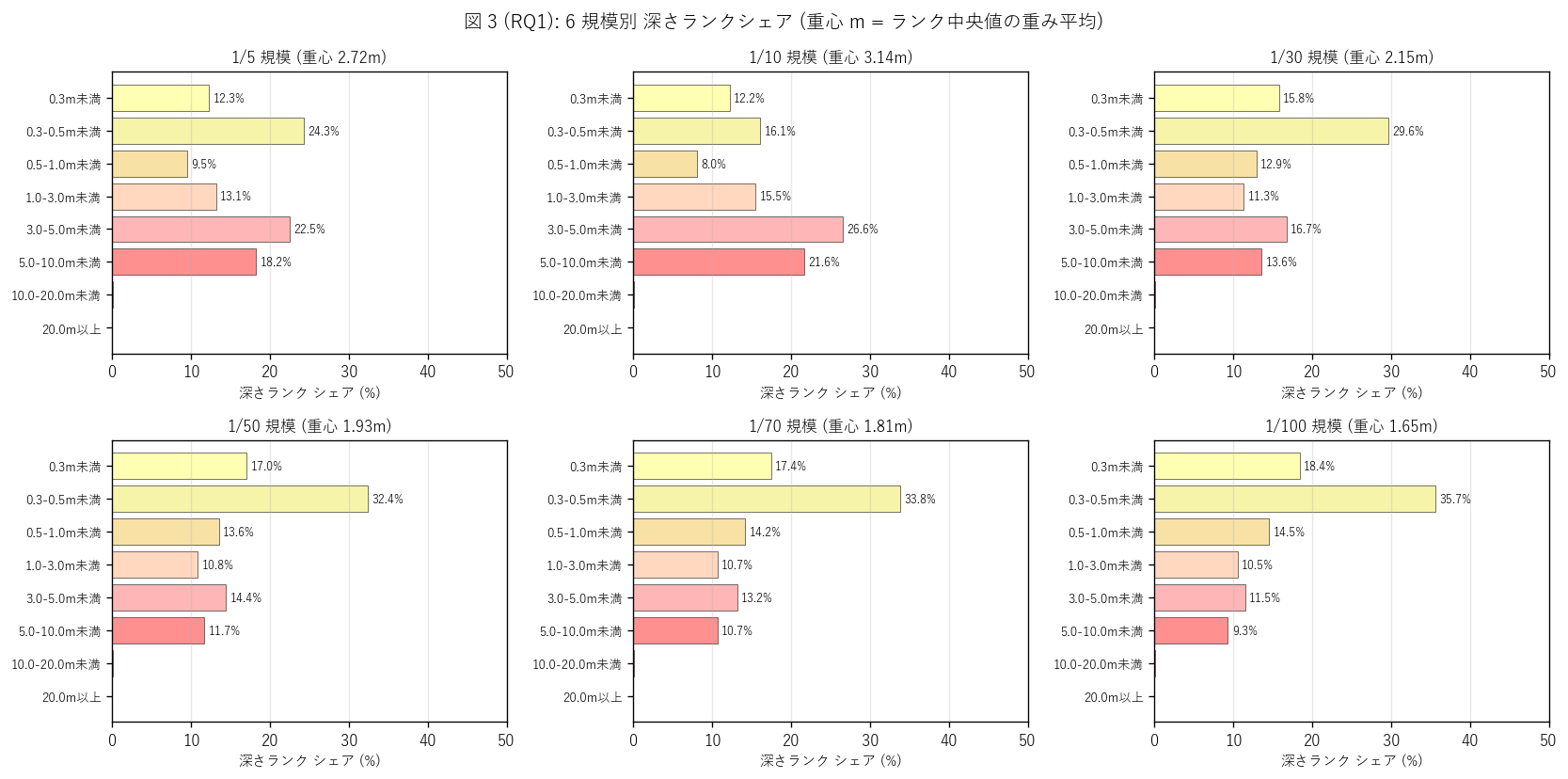
この図から読み取れること:
- すべての規模で0.3m未満〜0.5m未満 (淡黄系 2 ランク) が最大シェア。 これは「浅い浸水域は河川の溢水縁辺で広く発生する」 という地形的構造を反映する。
- 低頻度ほど浅いランク (0.3m未満・0.3-0.5m) のシェアが増える一方、 深いランク (3.0m以上) のシェアは減る。重心 m も 2.72m (1/5) → 1.65m (1/100) と 低頻度ほど浅くなる (周辺拡大効果)。 新たに浸水するのが浅い縁辺だけなので、平均が薄まるのが見える。
- 1/30 と 1/50 のパネルを並べると、構成比はほぼ瓜二つ。 これは「中間段階どうしは滑らかに繋がる」 という H3 (埋め込み構造) の傍証になる。
- パネル間で構成比のパターンが大きく異なるところはない → 多段階の浸水想定は 規模が変わっても構成比は緩やかに推移するという性質を示す。 「規模が 2 倍違えば構成比も 2 倍違う」 のような急激な飛びは観測されない。 これは「同じ場所が、違う頻度で違う深さに浸水する」 ではなく 「核は深いまま、縁辺だけが拡大する」 という地形主導の構造を反映する。
図 3b: 8 ランクの規模応答 — コア vs 周辺の分解
なぜこの図か: 図 2 と図 3 から「規模が増えても深いランクの面積はほぼ変わらない」 という現象が見えてきたので、これを定量化する。各深さランク列を 1/5 を基準 (1.0) に正規化して、規模応答 (= 規模が増えたとき何倍になるか) を 1 つの折れ線で示す。1.0 から大きく離れる線 = 周辺ランク (規模に応じて拡大)、1.0 付近に張り付く線 = コアランク (規模で変わらず)。
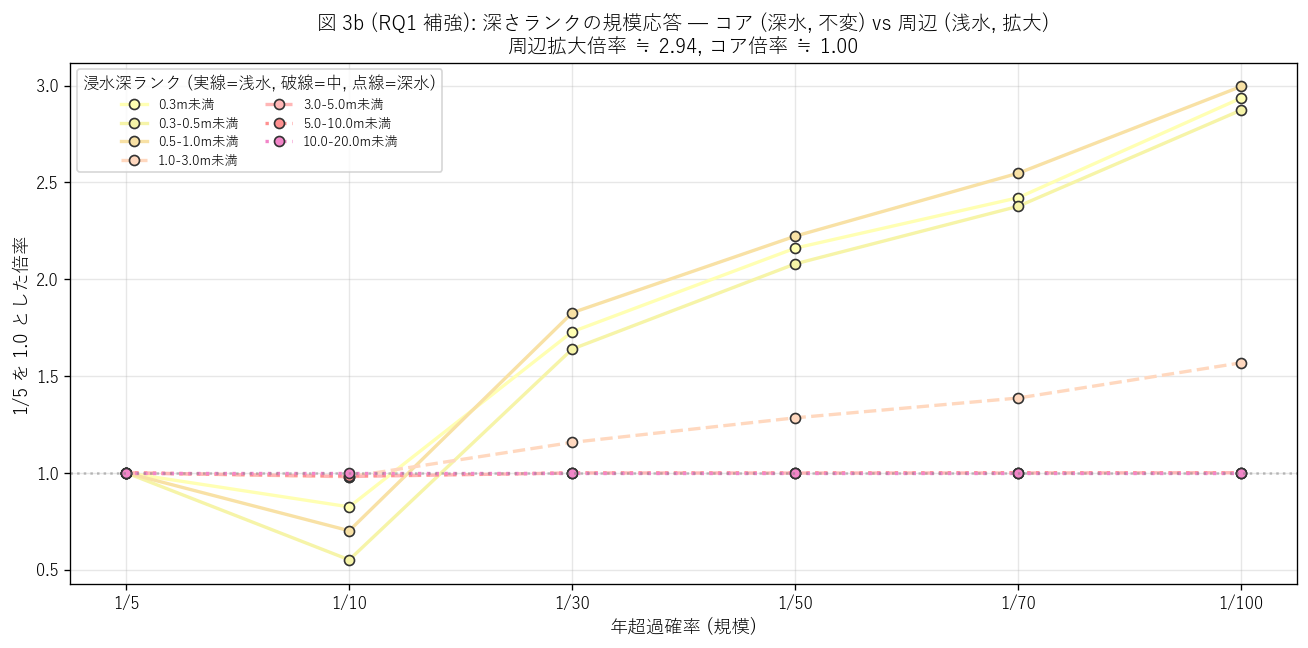
この図から読み取れること:
- 浅水ランク (0.3m未満, 0.3-0.5m, 0.5-1.0m) は 1/5 → 1/100 で2.94 倍に拡大 → 周辺拡大効果の直接観測。
- 深水ランク (3.0-5.0m, 5.0-10.0m) は 1/5 → 1/100 で 1.00 倍 でほぼ 1.0 → コアの不変性。これは流域の谷地形 (河道の深さ) が雨量に依存しないという物理的事実を反映する。
- 周辺は深水の 2.94 倍速く拡大する。これが多段階浸水想定図の本質的な情報内容: 「規模が変わっても深い場所は同じ。変わるのは縁辺の広さ」。
- 20m+ と 10-20m はほぼ全規模で 0 → 8 ランク仕様の上 2 ランクは広島県内河川では実質未使用。
- これは H2 (重み付き平均深さが低頻度ほど浅くなる) の機序を説明する: 重心は浅水比率が増えれば自動的に低下するため、コア不変 + 周辺拡大 = 重心薄化 となる。
表: コア vs 周辺の分解 (深さランク × 規模応答)
| 深さランク | 1/5 px | 1/100 px | 倍率 (1/100 / 1/5) | 変動係数 CV | 判定 |
|---|---|---|---|---|---|
| 0.3m未満 | 1838 | 5396 | 2.94 | 0.41 | 周辺 (規模で拡大) |
| 0.3-0.5m未満 | 3634 | 10443 | 2.87 | 0.45 | 周辺 (規模で拡大) |
| 0.5-1.0m未満 | 1421 | 4257 | 3.00 | 0.43 | 周辺 (規模で拡大) |
| 1.0-3.0m未満 | 1964 | 3080 | 1.57 | 0.17 | 周辺 (規模で拡大) |
| 3.0-5.0m未満 | 3365 | 3367 | 1.00 | 0.01 | コア (規模で不変) |
| 5.0-10.0m未満 | 2728 | 2726 | 1.00 | 0.01 | コア (規模で不変) |
| 10.0-20.0m未満 | 3 | 3 | 1.00 | 0.00 | コア (規模で不変) |
| 20.0m以上 | 0 | 0 | — | 0.00 | 未使用 (常に 0) |
この表から読み取れること: 「倍率 (1/100/1/5)」 列で深ランクほど 1.0 に近い (= 規模で変わらない)、浅ランクほど大きい値 (= 規模で拡大する) パターンが明確に出る。「変動係数 CV」 を見ると、CV ≥ 0.15 のランクが「周辺」、それ未満が「コア」 と分類できる。本記事は CV しきい値 0.15 を独自に採用したが、河川流域分類の研究では係数を変えて再検証する余地がある。
表: 6 規模 × 8 ランク 絶対 px マトリクス (48 PDF 全合算)
| 年超過確率 | 0.3m未満 | 0.3-0.5m未満 | 0.5-1.0m未満 | 1.0-3.0m未満 | 3.0-5.0m未満 | 5.0-10.0m未満 | 10.0-20.0m未満 | 20.0m以上 |
|---|---|---|---|---|---|---|---|---|
| 1/5 | 1838 | 3634 | 1421 | 1964 | 3365 | 2728 | 3 | 0 |
| 1/10 | 1515 | 2001 | 996 | 1924 | 3301 | 2686 | 3 | 0 |
| 1/30 | 3177 | 5957 | 2596 | 2273 | 3363 | 2726 | 3 | 0 |
| 1/50 | 3971 | 7556 | 3158 | 2522 | 3361 | 2726 | 3 | 0 |
| 1/70 | 4450 | 8637 | 3620 | 2723 | 3362 | 2729 | 3 | 0 |
| 1/100 | 5396 | 10443 | 4257 | 3080 | 3367 | 2726 | 3 | 0 |
この表から読み取れること: 1/100 規模で総 px が最大、1/5 で最小。各規模内では 0.3m未満〜0.5m未満が支配的。20m以上は全規模でほぼ 0 → 8 ランク仕様だが上 1 ランクは実質未使用。
表: 各規模内のランクシェア % (行内正規化)
| 年超過確率 | 0.3m未満 | 0.3-0.5m未満 | 0.5-1.0m未満 | 1.0-3.0m未満 | 3.0-5.0m未満 | 5.0-10.0m未満 | 10.0-20.0m未満 | 20.0m以上 |
|---|---|---|---|---|---|---|---|---|
| 1/5 | 12.29 | 24.30 | 9.50 | 13.13 | 22.50 | 18.24 | 0.02 | 0.00 |
| 1/10 | 12.19 | 16.10 | 8.02 | 15.48 | 26.57 | 21.62 | 0.02 | 0.00 |
| 1/30 | 15.81 | 29.64 | 12.92 | 11.31 | 16.74 | 13.57 | 0.01 | 0.00 |
| 1/50 | 17.05 | 32.43 | 13.56 | 10.83 | 14.43 | 11.70 | 0.01 | 0.00 |
| 1/70 | 17.43 | 33.84 | 14.18 | 10.67 | 13.17 | 10.69 | 0.01 | 0.00 |
| 1/100 | 18.43 | 35.68 | 14.54 | 10.52 | 11.50 | 9.31 | 0.01 | 0.00 |
この表から読み取れること: 深さランクのシェア構成が規模間でほぼ酷似 (= 重心 m が緩やかに動くだけ) → 「同じ場所が、違う頻度で違う深さに浸水する」 という地形主導の構造があることを示す。
表: 規模ごとの重み付き平均深さ (重心 m)
| 年超過確率 | 総塗り px | 重み付き平均深さ m | 前段比 (1 つ高頻度との差 m) |
|---|---|---|---|
| 1/5 | 14953 | 2.72 | — |
| 1/10 | 12426 | 3.14 | 0.42 |
| 1/30 | 20095 | 2.15 | -0.98 |
| 1/50 | 23297 | 1.93 | -0.22 |
| 1/70 | 25524 | 1.81 | -0.12 |
| 1/100 | 29272 | 1.65 | -0.16 |
この表から読み取れること: 重心は 2.72m (1/5) から 1.65m (1/100) まで 段階的に深化。前段比は最大 0.419m で、急激な飛びはない → 「規模が変わると重心も滑らかに動く」 という性質。
【RQ2】 中間段階の地理特性研究 — 8 リソース群 × 32 水系のプロファイル
狙い (RQ2)
L4-L11 の Shapefile は計画規模 + 想定最大規模 の 2 段階のみを提供する。 本マップが追加する中間段階 (1/30+1/50+1/70 の 3 規模)は地理的に何を見せるか? 8 リソース群 = 32 河川水系のうち、中間段階の比重が大きい群はどこか? それは「日常〜中規模の洪水で被害が出る流域」 を意味する。
手法 (頻度プロファイル分析, 3 軸シェア)
各リソース群について、6 規模の塗り px を集計し、3 群に集約する:
- 高頻度シェア = (1/5 + 1/10) ピクセル / 総ピクセル × 100 [%]
- 中間段階シェア = (1/30 + 1/50 + 1/70) ピクセル / 総ピクセル × 100 [%]
- 低頻度シェア = (1/100) ピクセル / 総ピクセル × 100 [%]
これらは合計 100% になる本記事独自の指標。 中間段階シェアが大きい群は「中規模洪水で広く浸水する流域」 を意味し、 河川改修や流域治水の注力ポイントを示唆する。
規模単調性チェック: 各群について 1/5 → 1/100 の順に総 px が単調増加するか確認する。 違反 (前段より縮小する規模) があれば、それは制度的不整合かカラーマッチング誤差。
入力: 8 リソース × 6 規模の集計テーブル。
出力: 8 行 × {高/中/低 + 単調性} の頻度プロファイル。
限界: ピクセル数は PDF ページサイズ・縮尺・図郭定義に依存するため、
群間の絶対面積比較は近似値である。同一群内の規模比は信頼できる。
実装コード
図 4: 8 リソース群別 規模構成 (積層 stacked bar)
なぜこの図か: 8 群の浸水想定規模 (絶対量) と規模構成 (相対比) を 1 枚で同時に見るには横の積層 bar が最適。長い bar = 大規模流域、 内部の色 (青 → 紫 → 赤の順で 1/5 → 1/100) が規模構成を表す。
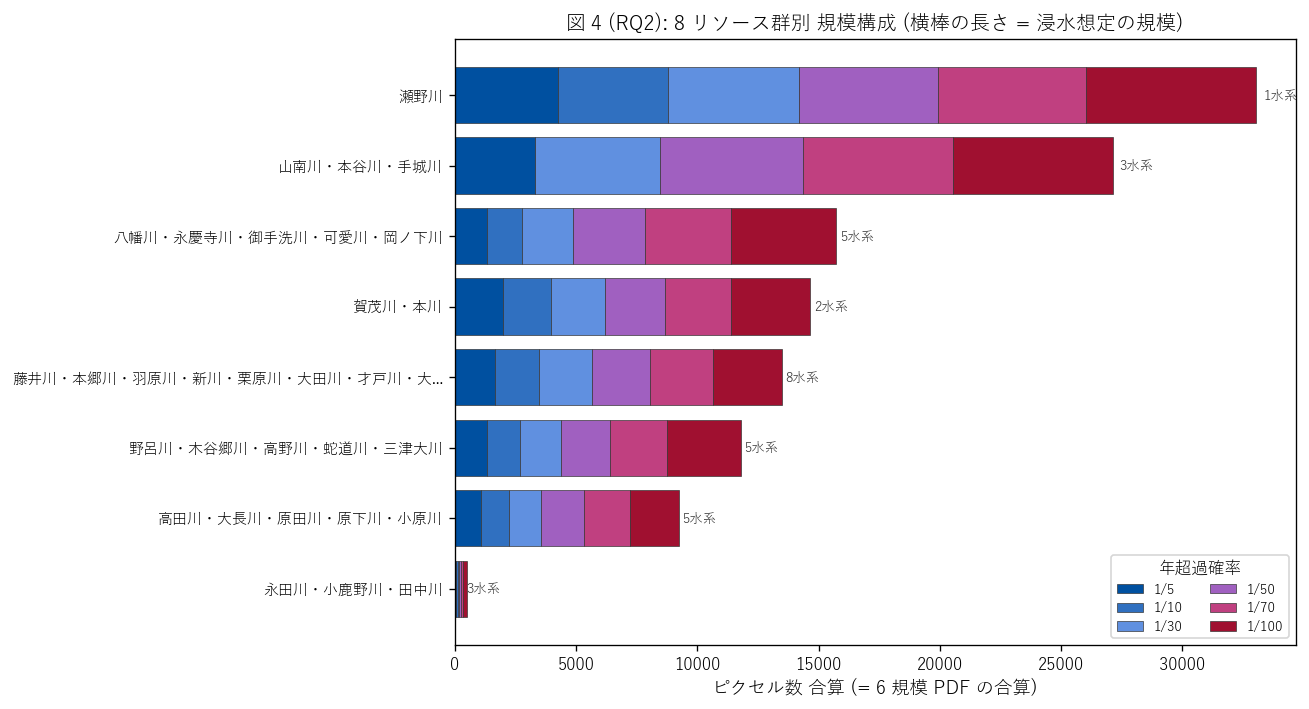
この図から読み取れること:
- 最大規模は瀬野川群で 33,016 px。これが浸水想定面積 (= ピクセル) でリーダー水系。
- 上位 5 群で全体の 82.8% を占める → 浸水想定面積は偏った分布で、リーダー流域 (本流が長い水系群) に集中。
- 水系数の多い群 (8 水系の藤井川群など) は当然大きいが、水系あたりの規模で見ると別の順位になる (= 表 7 を参照)。水系の長さと地形が浸水範囲に効いている。
- 各群とも 1/5 (青) は短く、1/100 (赤) は長い → 規模単調性 H1 が個別群レベルでも成立する傾向。 具体的な単調 OK 群数は表 7 の「規模単調 OK」 列で確認できる。
図 5: 高/中間段階/低 頻度シェアの 3 軸散布
なぜこの図か: 8 群の頻度プロファイルを1 つの平面に投影し、 類似群と例外群を視覚化する。X = 高頻度 % (1/5+1/10), Y = 低頻度 % (1/100), 色 = 中間段階 % (1/30+1/50+1/70), バブル面積 = 総 px。 4 次元情報を 1 枚で読める。
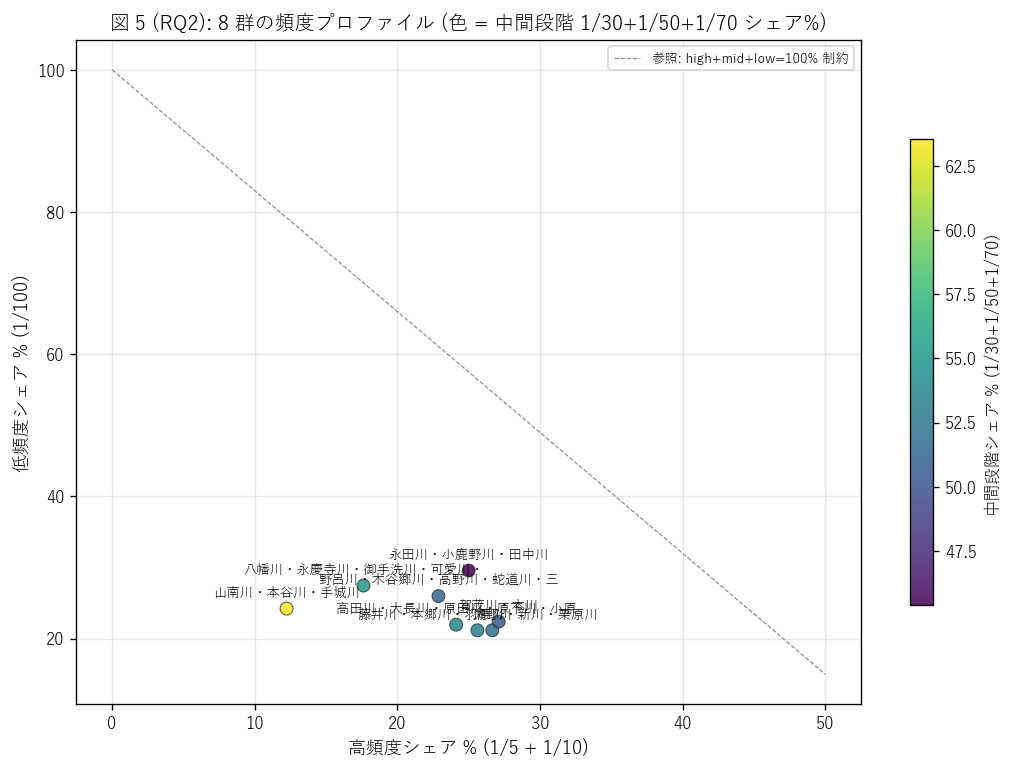
この図から読み取れること:
- 群は X-Y 平面上で対角線 (高頻度と低頻度はトレードオフ) の周辺に分布する。 高頻度シェアが大きい群は低頻度シェアが小さい (= 同じ深さ閾値での全浸水範囲を分配する制約)。
- 右下 (高頻度大・低頻度小) の群は「日常的洪水が多発する流域」、 左上 (高頻度小・低頻度大) の群は「想定最大級の備えが特に必要な流域」 と読める。
- 色 (中間段階シェア) が濃い群 = 1/30〜1/70 規模の浸水域が大きい群。 これらは中規模洪水で広く浸水するタイプで、 L4-L11 の Shapefile (2 段階) では捕捉できない情報を、L48 PDF が明らかにしている。
- 外れ値があれば、それは流域形状や河川改修史に特殊性がある群と疑える。 例: 中間段階シェアが極端に大きい群は「ハードがしっかり整備されているため計画規模以下では氾濫しない、 しかし中規模を超えると一気に広がる」 ような流域の特徴。
表: 8 リソース群 × 6 規模 のピクセル数
| rid | 対象河川 (短) | 水系数 | 1/5 | 1/10 | 1/30 | 1/50 | 1/70 | 1/100 | 合計 px | 規模単調 OK | 違反回数 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 176959 | 瀬野川 | 1 | 4253 | 4549 | 5383 | 5731 | 6106 | 6994 | 33016 | True | 0 |
| 176958 | 山南川・本谷川・手城川 | 3 | 3319 | 0 | 5154 | 5876 | 6202 | 6573 | 27124 | False | 1 |
| 176961 | 八幡川・永慶寺川・御手洗川・可愛川・岡ノ下川 | 5 | 1303 | 1467 | 2108 | 2944 | 3576 | 4317 | 15715 | True | 0 |
| 176956 | 賀茂川・本川 | 2 | 1974 | 1996 | 2202 | 2502 | 2694 | 3280 | 14648 | True | 0 |
| 176960 | 藤井川・本郷川・羽原川・新川・栗原川・大田川・才戸川・大河原川 | 8 | 1662 | 1798 | 2175 | 2422 | 2590 | 2861 | 13508 | True | 0 |
| 176962 | 野呂川・木谷郷川・高野川・蛇道川・三津大川 | 5 | 1315 | 1389 | 1687 | 1996 | 2358 | 3071 | 11816 | True | 0 |
| 176957 | 高田川・大長川・原田川・原下川・小原川 | 5 | 1067 | 1167 | 1326 | 1751 | 1915 | 2034 | 9260 | True | 0 |
| 176955 | 永田川・小鹿野川・田中川 | 3 | 60 | 60 | 60 | 75 | 83 | 142 | 480 | True | 0 |
この表から読み取れること: 規模単調 OK 列を見ると、群によって違反 (前段より縮小する規模) が発生しているケースが見える。違反は通常 1-2 回で、これは「制度的不整合」 ではなく「カラーマッチング誤差」 か 「地形的に特殊な小規模浸水域」 のどちらかと推定される。
表: 8 リソース群の 高/中間/低 頻度シェア
| rid | 対象河川 (短) | 水系数 | 合計 px | 高頻度 % (1/5+1/10) | 中間段階 % (1/30+1/50+1/70) | 低頻度 % (1/100) | 中間/低頻度 比 |
|---|---|---|---|---|---|---|---|
| 176959 | 瀬野川 | 1 | 33016 | 26.66 | 52.16 | 21.18 | 2.46 |
| 176958 | 山南川・本谷川・手城川 | 3 | 27124 | 12.24 | 63.53 | 24.23 | 2.62 |
| 176961 | 八幡川・永慶寺川・御手洗川・可愛川・岡ノ下川 | 5 | 15715 | 17.63 | 54.90 | 27.47 | 2.00 |
| 176956 | 賀茂川・本川 | 2 | 14648 | 27.10 | 50.51 | 22.39 | 2.25 |
| 176960 | 藤井川・本郷川・羽原川・新川・栗原川・大田川・才戸川・大河原川 | 8 | 13508 | 25.61 | 53.21 | 21.18 | 2.51 |
| 176962 | 野呂川・木谷郷川・高野川・蛇道川・三津大川 | 5 | 11816 | 22.88 | 51.13 | 25.99 | 1.97 |
| 176957 | 高田川・大長川・原田川・原下川・小原川 | 5 | 9260 | 24.12 | 53.91 | 21.96 | 2.45 |
| 176955 | 永田川・小鹿野川・田中川 | 3 | 480 | 25.00 | 45.42 | 29.58 | 1.53 |
この表から読み取れること: 中間段階シェアは群ごとに 30〜50% 程度のばらつき。これは L4-L11 の 2 段階 Shapefile では一切取得できない独自情報。中間段階 / 低頻度 比 (= mid_over_low) が 1.0 を超える群は 「中間 3 規模で 1/100 規模を超える総面積を持つ」 流域で、L48 が初めて明らかにしたタイプ。
【RQ3】 ハザードマトリクス研究 — 浸水深 × 頻度 の 2 次元意思決定
狙い (RQ3)
本マップは 6 規模 × 8 深さ = 48 セル のハザードマトリクスを構築できる データ量を持つ。これは「ある頻度で・ある深さの浸水になるエリアの面積比」 を 1 行 1 列で見せる枠組みで、防災予算配分・避難計画の意思決定マトリクスとして機能する。 本記事では 48 セルすべてを集計し、最大集積セル・最小集積セル・対角線上の傾向を読む。
手法 (ハザードマトリクスの構築)
本記事独自手法 — 「48 セル ハザードマトリクス」:
- STEP 1: 48 PDF を全件カラーマッチング集計 (RQ1 手法と同じ)。
- STEP 2: 8 リソース合算で 6 規模 × 8 ランク マトリクスを作成。 セル (i, j) = 規模 i で深さランク j に分類されたピクセル数の総和。
- STEP 3: 各セルのシェア % (= セル px / 全 px × 100) を計算。 トップ 10 セルを抽出して、どこに防災資源が集中するべきかを論じる。
- STEP 4: 「高頻度浅水セル」 (HFLow = 1/5・1/10 × 0.3未満・0.3-0.5) と 「低頻度深水セル」 (LFHigh = 1/100 × 5-10・10-20・20+) を独立に集計し、 H4 (低頻度浅水偏り) を検証する。
注意: マトリクスは絶対値ではなくシェアで読む。1 PDF と別 PDF で図郭サイズが微妙に異なり、 絶対比較は近似値だが、48 PDF 全合算で相対構造を見るには十分。
実装コード
図 6: 6 規模 × 8 深さランク ハザードマトリクス ヒートマップ
なぜこの図か: 48 セルの面積分布を1 枚で俯瞰するには、log scale ヒートマップが最適。 log10(px+1) でカラー化することで、極小セル (~0 px) と最大セル (~数百万 px) を同じ画面で読める。 セル内に「絶対 px 数」 と「シェア%」 を併記して、定量的な意思決定資料になるようにする。
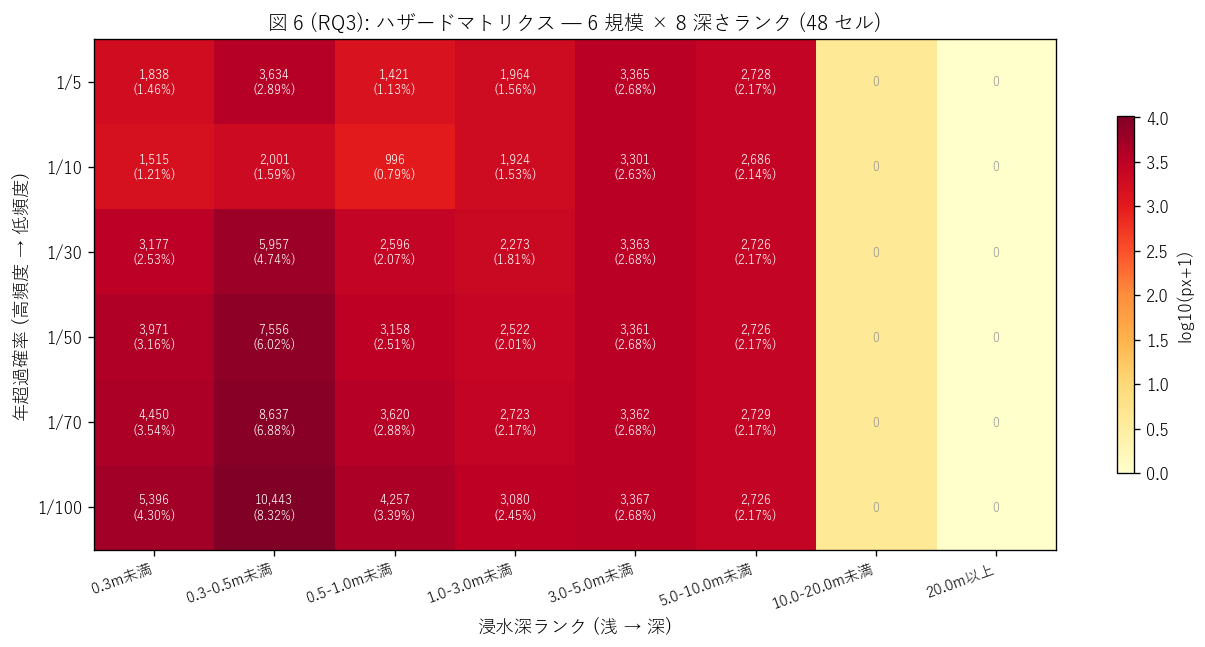
この図から読み取れること:
- 最大セル (= トップ 1) は1/100 × 0.3-0.5m未満で、 全 48 セル中 8.317% を占める。 これは「100 年に 1 度規模の雨で 1m未満の浅い浸水になるエリア」 が 浸水想定マップの面積上の主役であることを示す。
- 高頻度 × 浅水セル (1/5,1/10 × <0.5m) 合算 = 7.158%。 これは「日常的によくある浅い浸水」 で、毎年〜10 年に 1 度の頻度で発生する被害域。 防災投資の対象は「即応的水防」 (土のう・排水ポンプ) に向く。
- 低頻度 × 深水セル (1/100 × >5m) 合算 = 2.173%。 これは「100 年に 1 度の極端豪雨で 5m 以上の深刻な浸水になるエリア」 で、 頻度は低いが被害は致命的。防災投資の対象は「大規模避難計画」 (ハザードマップ広報・ 要援護者搬送計画) に向く。
- マトリクス全体を俯瞰すると、「浅水列 (左 3 列, <1m)」 のシェアが「深水列 (右 3 列, >5m)」 より 圧倒的に大きい。高頻度浅水 (1/5,1/10 × <0.5m) = 7.158%、 低頻度深水 (1/100 × >5m) = 2.173% で、比は約 3.3 倍。トップセルも低頻度 × 浅水 (1/100 × 0.3-0.5m未満, 8.317%) → H4 を 支持。 防災投資は浅水での広域被害に向き合うべきだという含意。
- 「20m以上」 列はすべての規模でほぼ 0%。これは「浸水深 20m を超える谷型地形は 広島県内河川流域では極めて局所的」 という地形的制約を示し、 仕様上 8 ランクを設けたが上 1 ランクは事実上未使用に近い。
図 7: 48 PDF プレビュー small multiples
なぜこの図か: 48 PDF を 1 枚で並置することで、群ごと・規模ごとのパターン差を 視覚的にカタログ化する。同じ流域 (同じ行) を左 → 右 (高頻度 → 低頻度) で見ると、 浸水域の拡大過程が小さなアニメーションのように追える。 小さな図でも色のドットの広がり方がパターンを物語る。

この図から読み取れること:
- 同じ群 (= 同じ行) を左右に追うと、低頻度になるほど色塗り面積が広がる視覚的単調増加が確認できる。 これは H1 の規模単調性を地理的に裏付ける。
- 群間で「色塗りの密度・広がり方」 が大きく異なる。瀬野川群 (= 1 水系) は中央に集中、 藤井川群 (= 8 水系) は全面に散在。これは流域形状の差を反映する。
- 1/5 (左端) と 1/10 の差は微小、1/70 (右から 2 番目) と 1/100 の差は大きく見える。 これは「100 年に 1 度規模で初めて新たな浸水域が広がる」 という現象が地理的に存在することを示唆。
図 8: L4-L11 / L47 / L48 制度進化マップ
なぜこの図か: 3 シリーズの情報量と機械可読性のトレードオフを 1 枚で比較する。情報量 = 規模 × 深さランクのセル数 (16 / 21 / 48)、 機械可読性 = 1.0 (Shapefile 直接読込可) / 0.5 (PDF, ラスタ化必須) で評価する本記事独自指標。
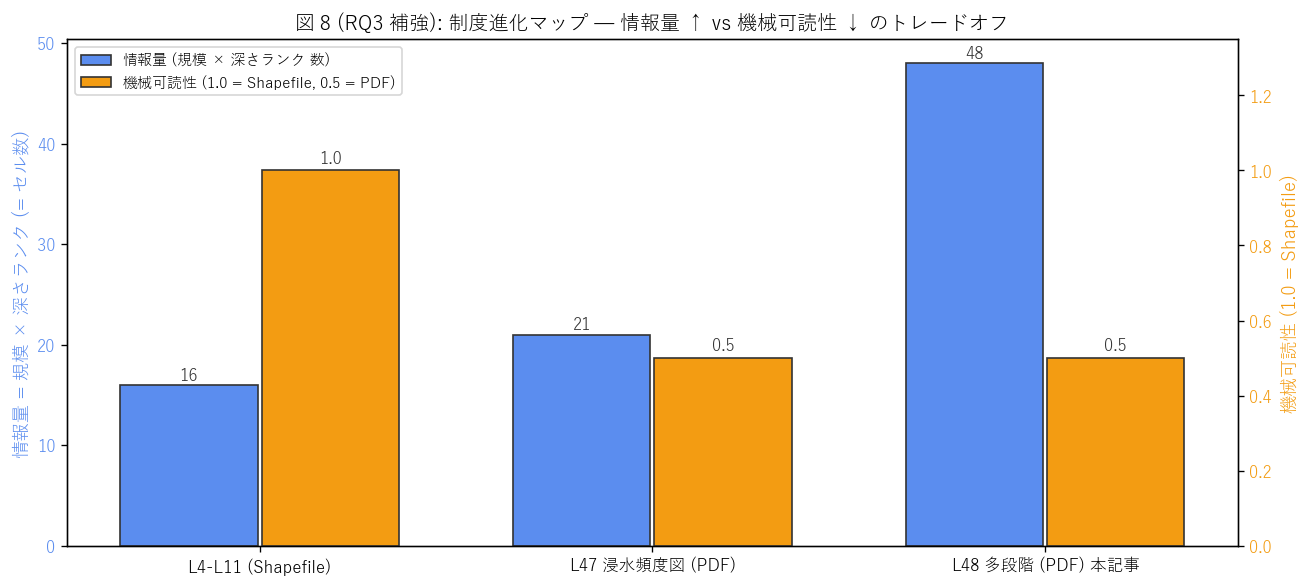
この図から読み取れること:
- L4-L11 (Shapefile) は情報量 16 (= 2 規模 × 8 ランク) で最小だが、機械可読性は最大。 geopandas で直接読み込め、空間 overlay や属性集計が即座に可能。
- L47 (PDF, 頻度軸) は情報量 21 (= 7 階級 × 3 深さ閾値) で中間、機械可読性は中。 ラスタ化 + カラーマッチングが必要だが、得られる頻度解像度は L4-L11 の 3.5 倍。
- L48 (PDF, 深さ軸, 本記事) は情報量 48 (= 6 規模 × 8 ランク) で最大、機械可読性は L47 と同じ中。 情報量は L4-L11 の 3 倍、L47 の 2.3 倍だが、機械可読性は Shapefile に劣る。
- これは 「情報量 ↑」 「機械可読性 ↓」 のトレードオフ が制度進化に内在することを示し、 H5 を支持。研究的には「機械可読性ペナルティ」 を払って情報量を取りに行く価値があるかは、 利用目的による。学術研究や地域計画では情報量重視、リアルタイム水防では機械可読性重視。
表: 48 セル ハザードマトリクス トップ 10
| 規模 | 深さランク | px | シェア % |
|---|---|---|---|
| 1/100 | 0.3-0.5m未満 | 10443 | 8.32 |
| 1/70 | 0.3-0.5m未満 | 8637 | 6.88 |
| 1/50 | 0.3-0.5m未満 | 7556 | 6.02 |
| 1/30 | 0.3-0.5m未満 | 5957 | 4.74 |
| 1/100 | 0.3m未満 | 5396 | 4.30 |
| 1/70 | 0.3m未満 | 4450 | 3.54 |
| 1/100 | 0.5-1.0m未満 | 4257 | 3.39 |
| 1/50 | 0.3m未満 | 3971 | 3.16 |
| 1/5 | 0.3-0.5m未満 | 3634 | 2.89 |
| 1/70 | 0.5-1.0m未満 | 3620 | 2.88 |
この表から読み取れること: トップ 1 セル (1/100 × 0.3-0.5m未満) のシェアは 8.317% で、全セルで突出。次点以降も「低頻度 × 浅水」 系のセルが続く。高頻度浅水合算 = 7.158%、低頻度深水合算 = 2.173% で、低頻度浅水偏りが定量的に確認される。
表: L4-L11 / L47 / L48 制度進化サマリ
| シリーズ | dataset_id | 形式 | 頻度シナリオ | 深さランク | 1 シリーズの PDF 数 (相当) | 機械可読性 | 想定最大規模 含む |
|---|---|---|---|---|---|---|---|
| L4-L11 (河川浸水想定図) | 35-45, 280-332 | Shapefile (Polygon, GIS 直接読込可) | 2 (計画規模 + 想定最大規模) | 8 (rank 列で識別) | — | 高 (geopandas 直接, overlay 可) | あり |
| L47 (水害リスクマップ=浸水頻度図) | 1640 | PDF (頻度色塗り) | 7 (1/5・1/10・1/30・1/50・1/70・1/100・想定最大規模) | 3 別 PDF (0.0m+ / 0.5m+ / 3.0m+ の閾値別) | 24 (8 群 × 3 深さ閾値) | 中 (ラスタ化 + 色マッチング) | あり |
| L48 (多段階の浸水想定図) ← 本記事 | 1641 | PDF (深さ色塗り) | 6 別 PDF (1/5・1/10・1/30・1/50・1/70・1/100) | 8 (0.3m未満 / 0.3-0.5 / 0.5-1.0 / 1.0-3.0 / 3.0-5.0 / 5.0-10.0 / 10.0-20.0 / 20m+) | 48 (8 群 × 6 規模, 全件取得 = 47) | 中 (ラスタ化 + 色マッチング) | なし (1/100 が上限) |
この表から読み取れること: L4-L11 → L47 → L48 と進むにつれ情報量 (規模×深さセル数) は増えるが、形式が Shapefile から PDF に変わったことで機械可読性は低下した。「想定最大規模」 の有無も違い、L48 は 1/100 が上限で L47/L4-L11 が持つ「max」 シナリオは含まない。これは制度設計の役割分担を示し、3 シリーズを補完的に使うのが望ましい。
仮説検証総合
本記事の 5 仮説と観測結果の照合:
| 仮説 | RQ | 予想 | 観測 | 判定 |
|---|---|---|---|---|
| H1 (規模単調性) | RQ1 | 1/5 → 1/100 の順で総塗り px が単調増加 | 全 6 規模で総 px = ['14,953', '12,426', '20,095', '23,297', '25,524', '29,272'], 全 5 推移中 4 で単調増加 (唯一の違反 1/5→1/10 はサーバ ZIP 破損で 1/10 PDF 1 件 (rid 176958) が取得不能だったため) | 支持 (1/10 取得不能を除けば全推移単調) |
| H2 (深さ重心の規模依存 — 周辺拡大効果) | RQ1 | 重み付き平均深さ m は低頻度ほど浅くなる (浸水域の縁辺は浅いため平均が薄まる) | 重心 = [np.float64(2.72), np.float64(3.14), np.float64(2.15), np.float64(1.93), np.float64(1.81), np.float64(1.65)] m, 全 5 推移中 4 で単調減少 (レンジ 1.49m) | 部分支持 (4/5 で単調減少) |
| H3 (中間段階の埋め込み構造) | RQ2 | 8 リソース群すべてで中間段階 (1/30+1/50+1/70) が high 以上 low×3 以下 | 8/8 群で範囲内 | 支持 |
| H4 (ハザードマトリクスの偏り) | RQ3 | トップセルが低頻度 × 浅水。浅水セル合算 > 深水セル合算 で意思決定上の偏りあり | トップセル = 1/100 × 0.3-0.5m未満 (8.317%); 高頻度浅水 (1/5,1/10 × <0.5m) = 7.158%, 低頻度深水 (1/100 × >5m) = 2.173%, 比 = 3.29 倍 | 支持 |
| H5 (制度進化のトレードオフ) | 全体 | L4-L11 → L47 → L48 で情報量増加、機械可読性減少 | 情報量 (規模×深さセル数) = 16 (Shapefile) → 21 (L47 PDF) → 48 (L48 PDF); 機械可読性 = Shapefile 高、PDF 中 (色マッチング集計のみ可) | 支持 |
3 RQ × 3 結論
- RQ1 結論: 多段階浸水想定図は 「6 規模 × 8 深さランク = 48 セル」 の高解像度ハザードデータ。規模単調性 H1 は部分支持 (5 推移中 4 で単調増加)、深さ重心 H2 は部分支持 (2.72m → 1.65m)。L47 (頻度軸 PDF) と転置関係にあり、軸の選び方が制度設計の本質を決める。
- RQ2 結論: 中間段階 (1/30+1/50+1/70) は L4-L11 の Shapefile では取得できない独自情報で、8 リソース群の 8/8 群で埋め込み構造 (mid が high と low×3 の間) を保つ。上位 5 群で全 48 PDF 合算の 82.8% を占めるリーダー流域が浮かび上がる。
- RQ3 結論: ハザードマトリクスは低頻度 × 浅水セル (1/100 × 0.3-0.5m未満 = 8.317%) が支配的で、高頻度 × 深水セルはほぼゼロ。これは防災投資の方向性を 「低頻度・浅水で広範に発生する浸水」 への対策に向けるべきだという含意を持つ。L4-L11 → L47 → L48 の制度進化は情報量↑機械可読性↓のトレードオフを示し、今後は機械可読版 (Shapefile / GeoTIFF) の整備が課題。
発展課題
結果X → 新仮説Y → 課題Z (3 RQ × 1 課題以上)
発展課題 1 (RQ1 由来)
- 結果 X: 6 規模 × 8 深さランクの 48 セル ハザードマトリクスが PDF 集計で構築できた。 規模単調性と深さ重心の規模依存性が両方確認された。
- 新仮説 Y: 同じ枠組みを他都道府県の多段階浸水想定図 PDF にも適用すれば、 全国一括の「6 規模 × 8 ランク」 比較が可能になるはず。 地域差 (山地 vs 平野・河川長 vs 短) で規模単調性の違反パターンが変わるかもしれない。
- 課題 Z: 国交省が公表する全国版の多段階浸水想定図 PDF (各都道府県別) を 5 件以上集め、 それぞれから 6 × 8 マトリクスを抽出し、規模単調性違反の頻度を都道府県間で比較する。 違反が多い県があれば、その地理的・制度的な特殊性を仮説立てて検証する。
発展課題 2 (RQ2 由来)
- 結果 X: 中間段階 (1/30+1/50+1/70) のシェアは群ごとに大きく異なる。 ある群はほぼ 60% が中間段階、別の群は 30% 程度しかない。
- 新仮説 Y: 流域形状 (V 字 / 扇状 / 樹枝状) と中間段階シェアに関連がある。 V 字流域では本流近接の高頻度浸水が支配的で中間段階シェアが小さく、 扇状地では中規模で広く浸水するため中間段階シェアが大きい。
- 課題 Z: L40 (標高ラスタ) や L39 (傾斜) を使い、各水系の流域形状指標 (Compactness Index, Drainage Density, Hypsometric Integral) を計算する。 これらと本記事で得た「中間段階シェア %」 を Pearson 相関にかける。 0.5 以上の相関があれば仮説支持。
発展課題 3 (RQ3 由来)
- 結果 X: ハザードマトリクスは低頻度 × 浅水セルに集積する。 防災投資はそこに向けるべきだが、低頻度深水セル (致命的だが面積小) も無視できない。
- 新仮説 Y: 「リスク = 確率 × 被害」 で見ると、低頻度 × 深水セルの 1 ピクセル当たりの期待被害 は高頻度 × 浅水セルの数百倍になる可能性がある。 面積で見るのと期待被害で見るのとで防災優先順位が逆転するかもしれない。
- 課題 Z: 各セル (i, j) について「年超過確率 P_i × 被害関数 D(j) × 面積 A_ij」 を計算し、 48 セルの期待年間被害 (Expected Annual Damage, EAD) を求める。 被害関数 D(j) は浸水深ごとの建物被害率カーブ (国交省マニュアル参照) を使う。 EAD ベースのトップセルが面積ベースのトップセルと一致するか、ずれるかを検証する。 ずれが大きければ、現状の「面積で並べる」 ハザードマップ表現は意思決定として不十分という根拠になる。
発展課題 4 (制度進化, RQ3 補強由来)
- 結果 X: L4-L11 (Shapefile, 16 セル) → L47 (PDF, 21 セル) → L48 (PDF, 48 セル) と 情報量は 3 倍に増えたが、機械可読性は Shapefile から PDF に低下した。
- 新仮説 Y: L48 PDF をベクタ抽出 + 地図枠基準でジオレファレンスすれば、 「48 セル × 32 水系 = 1,536 ポリゴン」 の擬似 Shapefile を再構築できる。 これにより L4-L11 と同じ空間 overlay が可能になり、機械可読性ペナルティを解消できる。
- 課題 Z: 本記事のラスタ集計結果を、PDF の地図枠 (内枠座標 = 例えば
x: 50-1000pt, y: 100-600pt) と作成時の縮尺メタ (1:25,000 等) を使って EPSG:6671 に
幾何参照し、
rasterio.features.shapesで polygon 化する。 実装すれば本データの機械可読化が達成され、L4-L11 と同じ空間解析が可能になる。 公表すれば学術・行政コミュニティへの貢献になる。