水害リスクマップ(浸水頻度図)単独 3 研究例分析 — 7 階級 × 32 水系の頻度地図を読む
データ取得手順
✅ このスクリプトは初回実行時にデータを自動取得します(DoBoX からの直接ダウンロード)。
| ID | データセット名 |
|---|---|
| #333 | dataset #333 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1640 | 水害リスクマップ(浸水頻度図) |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L47_flood_risk_map.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
スクリプト(全体ソースコード)
cd "2026 DoBoX 教材"
python -X utf8 lessons/L47_flood_risk_map.py学習目標と問い
本記事は DoBoX のシリーズ 「水害リスクマップ(浸水頻度図)」 1 件 (dataset_id = 1640) を 単独で取り上げ、 広島県内 32 河川水系 × 浸水深 3 閾値 = 24 PDF (うち 23 件取得可) を 3 つの独立した研究角度から並列に分析する。
本マップの位置付け — 「浸水頻度の地図」
「水害リスクマップ(浸水頻度図)」は、L4-L11 の河川浸水想定図 (計画規模 / 想定最大規模) と 同じく河川氾濫を扱うが、異なる切り口で情報を整理する:
- L4-L11 浸水想定図 = 2 段階のシナリオ (計画規模 + 想定最大規模) を別々の Shapefile で配布
- 本マップ (1640) = 7 段階の年超過確率 (1/5・1/10・1/30・1/50・1/70・1/100・想定最大規模) を 1 枚の PDF に重ねて配布
つまり本マップは「頻度ベースで再整理した浸水想定の総覧」であり、 「100 年に 1 度の雨」と「30 年に 1 度の雨」の浸水範囲が同じ図上で同時比較できる、 従来 Shapefile から欠落していた 中間頻度 5 段階 を可視化する制度的補完物である。
研究の問い (3 RQ)
- RQ1 (主研究): 水害リスクマップの仕組みとは何か? 7 階級 (1/5〜想定最大規模) と 3 浸水深閾値 (0.0m+ / 0.5m+ / 3.0m+) の組合せは、23 PDF 上でどう配分されているか?
- RQ2 (副研究 1): 高リスクエリア (= 高頻度 = 低確率閾値で浸水) の 地理特性はどうなっているか? 8 リソース群 = 32 河川水系のうち、 浸水想定面積でリーダーとなる水系群はどこか?
- RQ3 (副研究 2): 既存 Shapefile (L4-L11 河川浸水想定) との関係はどうか? フォーマットの違いはどんな情報の欠落を生んでいるか?
仮説 H1〜H5
- H1 (頻度階級の積層構造, RQ1): PDF 上に 7 階級すべての色が出現する。各ピクセルは「最頻=最も小さい確率閾値」の色で表示される (= 1/5 で浸水するエリアは 1/5 の色で塗られ、1/10 や 1/100 の色には塗りつぶされない)。
- H2 (深さ閾値による減衰, RQ1): 浸水深 d00 (0.0m+) → d05 (0.5m+) → d30 (3.0m+) の順に塗り面積が単調減少。 d30 ≤ d00 の 1/3 以下と予想。
- H3 (水系規模の偏り, RQ2): 8 リソース群のうち、上位 5 群が浸水ピクセルの 50% 以上を占める。
- H4 (PDF と Shapefile の被覆差, RQ3): L4-L11 Shapefile は2 段階のみで、本マップが提示する 中間頻度 5 段階 (1/5・1/10・1/30・1/50・1/70)は Shapefile 由来データから取得不能。
- H5 (頻度マップの本質, RQ1): 水害リスクマップは 「面の集合」ではなく 「頻度の地図」。 同一ピクセルに複数頻度の浸水想定がある場合、最頻 (最も小さい閾値) のみが表示される。
本記事の独自用語定義
- 水害リスクマップ (浸水頻度図): 広島県土木建築局河川課が令和 6 年 4 月 10 日に公表した、 年超過確率 1/5 から 1/100 + 想定最大規模の 7 段階の浸水範囲を 1 枚の A3 PDF に重ねた図面。 本記事の対象データそのもの。
- 年超過確率 (annual exceedance probability): ある降雨規模が「1 年間にその規模を超える確率」。1/5 = 20%/年, 1/100 = 1%/年。 気象学・水文学の標準用語であり、本記事独自の語ではないが学習者向けに明示する。
- L1 (計画規模) / L2 (想定最大規模): 水防法に基づく Shapefile の 2 段階。L4-L11 で扱う。本マップの 7 段階のうち L1 ≒ 1/100, L2 ≒ 想定最大規模 とほぼ対応。
- 頻度階級: 7 段階の年超過確率カテゴリ。本記事独自にこう呼ぶ。
- 浸水深閾値: 0.0m / 0.5m / 3.0m の 3 段階。それぞれ「浸水あり」「床上浸水相当」 「一階居室浸水相当」を区別する。本記事独自にこう呼ぶ。
- 高頻度シェア: 1/5 + 1/10 + 1/30 の合算割合。本記事独自指標。
- 中頻度シェア: 1/50 + 1/70 の合算割合。本記事独自指標。
- 低頻度シェア: 1/100 + 想定最大規模 の合算割合。本記事独自指標。
- フォーマット欠落: 同じ現象 (河川浸水) を扱うのに、配布フォーマットが異なるために 取得可能な情報粒度に差が生じている状況。本記事独自概念。 DoBoX の公式分類ではない。
- カラーマッチング集計: PDF をラスタ化し、7 階級の凡例色 (RGB 既知) との Chebyshev 距離 ≤ 20 + 彩度 ≥ 35 でピクセルを分類する本記事独自の手法。 GIS 座標がない PDF から面積比を引き出すための実用解。
- ピクセル数 (px): 本記事の集計単位。1 PDF を 100 dpi にラスタ化した時のピクセル数。 地理面積 (km²) ではないので注意。各 PDF 内の相対比として読む。
到達点
3 つの研究角度それぞれで、水害リスクマップという 同じ 1 つのデータ から 独立した知見が得られることを学ぶ。とくに 「データ数 = 1 でも、研究角度 × 3 = 知見 × 3」 という探究法を、PDF というフォーマットの意味を読み解く形で身につける。 GIS 座標を持たない PDF からも、ラスタ化 + カラーマッチングという技法によって 量的分析が可能であることを示す。
使用データ
本記事は DoBoX シリーズの 1 件のみ を扱う:
| 項目 | 値 |
|---|---|
| dataset_id | 1640 |
| タイトル | 水害リスクマップ(浸水頻度図) |
| DoBoX URL | https://hiroshima-dobox.jp/datasets/1640 |
| リソース数 | 8 (= 河川水系のグループ別 ZIP, 各 2-8 水系を含む) |
| 対象水系数 | 32 (8 グループに分散) |
| PDF 数 | 23 / 24 (1 件 = 八幡川 0.0m はサーバ ZIP 破損で取得不可) |
| 形式 | PDF (A3 横, 1190×842 pt) |
| 頻度階級 | 7 段階 (1/5, 1/10, 1/30, 1/50, 1/70, 1/100, 想定最大規模) |
| 浸水深閾値 | 3 段階 (0.0m+ / 0.5m+ / 3.0m+) |
| 公表年月日 | 令和 6 年 4 月 10 日 (2024-04-10) |
| 作成主体 | 広島県土木建築局河川課 |
| ZIP 合計サイズ | ~98 MB (圧縮後) |
| ライセンス | CC-BY 4.0 (クリエイティブ・コモンズ表示) |
| GIS 座標 | なし (PDF はベクタ図面で地理座標が直接埋め込まれない) |
凡例 7 階級の測色結果
| 頻度階級 | 意味 | RGB | HEX | 色名 |
|---|---|---|---|---|
| 1/5 | 高頻度・低浸水確率閾値 | (200,179,223) | #c8b3df | 紫薄 |
| 1/10 | 高頻度・低浸水確率閾値 | (246,140,140) | #f68c8c | 桃濃 |
| 1/30 | 高頻度・低浸水確率閾値 | (246,188,189) | #f6bcbd | 桃淡 |
| 1/50 | 中頻度 | (151,207,246) | #97cff6 | 水色 |
| 1/70 | 中頻度 | (182,249,177) | #b6f9b1 | 緑 |
| 1/100 | 低頻度・高浸水確率閾値 | (255,200,84) | #ffc854 | 橙 |
| 想定最大規模 | 低頻度・高浸水確率閾値 | (255,255,179) | #ffffb3 | 淡黄 |
RGB は実 PDF (瀬野川 d00) を 300 dpi でラスタ化し、凡例エリアから median で抽出した。23 PDF 全件で同色が再現されることを確認済み。
8 リソースの内訳
| resource_id | slug | 対象河川 | 水系数 | DL |
|---|---|---|---|---|
| 176947 | nagata_okajino_tanaka | 永田川・小鹿野川・田中川 (3水系) | 3 | https://hiroshima-dobox.jp/resource_download/176947 |
| 176948 | kamo_honkawa | 賀茂川・本川 (2水系) | 2 | https://hiroshima-dobox.jp/resource_download/176948 |
| 176949 | takada_ocho_harada_etc | 高田川・大長川・原田川・原下川・小原川 (5水系) | 5 | https://hiroshima-dobox.jp/resource_download/176949 |
| 176950 | sannan_motoya_tejiro | 山南川・本谷川・手城川 (3水系) | 3 | https://hiroshima-dobox.jp/resource_download/176950 |
| 176951 | seno | 瀬野川 (1水系) | 1 | https://hiroshima-dobox.jp/resource_download/176951 |
| 176952 | fujii_hongo_habara_etc | 藤井川・本郷川・羽原川・新川・栗原川・大田川・才戸川・大河原川 (8水系) | 8 | https://hiroshima-dobox.jp/resource_download/176952 |
| 176953 | yahata_eikoji_mitearai_etc | 八幡川・永慶寺川・御手洗川・可愛川・岡ノ下川 (5水系) | 5 | https://hiroshima-dobox.jp/resource_download/176953 |
| 176954 | noro_kinoya_takano_etc | 野呂川・木谷郷川・高野川・蛇道川・三津大川 (5水系) | 5 | https://hiroshima-dobox.jp/resource_download/176954 |
1 リソース = 1 ZIP = 複数河川水系の PDF 群。総 32 水系を 8 群に分散配布。ID #176953 (八幡川グループ) の 0.0m+ PDF はサーバ側 ZIP の zlib エラーのため取得不能。本記事の集計から 1 件を除外している。
ダウンロード
DoBoX 本体 (1 件 + 8 リソース)
8 リソース直 DL ボタン:
- resource 176947 (永田川・小鹿野川・田中川 (3水系)): 直DL ZIP
- resource 176948 (賀茂川・本川 (2水系)): 直DL ZIP
- resource 176949 (高田川・大長川・原田川・原下川・小原川 (5水系)): 直DL ZIP
- resource 176950 (山南川・本谷川・手城川 (3水系)): 直DL ZIP
- resource 176951 (瀬野川 (1水系)): 直DL ZIP
- resource 176952 (藤井川・本郷川・羽原川・新川・栗原川・大田川・才戸川・大河原川 (8水系)): 直DL ZIP
- resource 176953 (八幡川・永慶寺川・御手洗川・可愛川・岡ノ下川 (5水系)): 直DL ZIP
- resource 176954 (野呂川・木谷郷川・高野川・蛇道川・三津大川 (5水系)): 直DL ZIP
中間 CSV (本レッスンが生成)
- L47_pdf_color_hist.csv — 23 PDF × 7 階級の生集計
- L47_class_share_d00.csv — d00 における 7 階級シェア
- L47_resource_class_breakdown.csv — 8 リソース別 階級内訳
- L47_freq_profile.csv — リソース別 高/中/低 頻度シェア
- L47_external_compare.csv — PDF vs Shapefile フォーマット比較
- L47_format_gap.csv — 頻度階級 × フォーマット の被覆差マトリクス
- L47_depth_decay.csv — 頻度階級ごとの浸水深減衰
図 PNG (8 枚)
- L47_fig1_legend_preview.png
- L47_fig2_depth_class_stack.png
- L47_fig3_depth_share_smallmultiples.png
- L47_fig4_resource_class_stack.png
- L47_fig5_freq_profile_scatter.png
- L47_fig6_external_shp_bbox.png
- L47_fig7_class_heatmap.png
- L47_fig8_pdf_small_multiples.png
再現スクリプト
再現コマンド
cd "2026 DoBoX 教材"
py -X utf8 lessons/L47_flood_risk_map.py初回実行時は dataset 1640 の 8 ZIP (~98 MB) を DL し、PDF を展開する。PDF の集計結果は data/extras/L47_flood_risk_map/_cache/pdf_color_hist.json にキャッシュされる。2 回目以降は ~5 秒で再実行完了。
【RQ1】 リスク階級分布の研究 — 7 階級 × 3 浸水深閾値の積層構造
狙い (RQ1)
水害リスクマップという「1 枚の PDF に 7 段階の浸水範囲を重ねた図」が、 実際にどう描かれているかを定量的に把握する。 凡例の 7 階級色 (1/5〜想定最大規模) と 3 浸水深閾値 (0.0m / 0.5m / 3.0m) の組合せが、 23 PDF 全体ではどんな配分なのかを集計する。
手法 (カラーマッチング集計)
PDF はベクタ図面で地理座標を持たないため、Shapefile のように
geopandas.area で面積を直接計算できない。代わりに本記事独自の手法を使う:
- STEP 1: PyMuPDF (
fitz) で PDF ページを 100 dpi (1190×842 pt → 1102×779 px) のラスタにレンダリング。 - STEP 2: 凡例エリア (右下 x:1010-1042 pt, y:625-695 pt) を 300 dpi でクロップし、 各階級ラベルの左にあるカラースワッチから median RGB を抽出 → 7 階級の凡例色を得る。
- STEP 3: 各ピクセルと 7 階級色とのChebyshev 距離 (RGB 各チャネル差の最大値) を計算し、距離 ≤ 20 かつ最近傍の階級にそのピクセルを分類。 さらに彩度 (max-min channel) ≥ 35 のピクセルのみを「塗られた」 と認定し、 白背景・地形図グレー・山地暗緑を除外する。
- STEP 4: 階級ごとのピクセル数を集計。23 PDF × 7 階級 + その他 のテーブルが完成する。
入力: 23 PDF と凡例 RGB 7 色。
出力: 23 行 × 7 列のピクセル数テーブル (= L47_pdf_color_hist.csv)。
限界: ピクセル数は地理面積 (km²) ではない。各 PDF 内の相対比としてのみ意味がある。
地図の縮尺や図郭サイズは PDF 間で異なるため、PDF 間の絶対比較には注意。
代替案: 国土地理院の Geo TIFF があれば直接面積計算可能だが、
DoBoX の本データは PDF 配布のみ。本手法はその制約下での実用解。
実装の要点
- numpy のベクタ化で 7 階級同時マッチング (
np.abs(...).max(-1).argmin(-1)) → 1 PDF (~1.9 MP) を ~1-2 秒で集計。 - 23 PDF 集計結果は JSON にキャッシュ → 2 回目以降は <1 秒で再実行。
- カラー許容差 20 と彩度下限 35 は「PDF レンダリング由来の薄塗りノイズ」を 吸収しつつ「凡例外の地形図山緑を混同しない」値として実験的に決定。
STEP 1 のコード
↑ L47_flood_risk_map.py 行 1199–1292
STEP 3-4 のコード
図 1: PDF プレビュー + 凡例カラー解説
なぜこの図か: 学習者がまず「水害リスクマップとは何か」を視覚で理解するため、 1 PDF (瀬野川 d00) のプレビューと、抽出した 7 階級色のスウォッチを並置する。 PDF の右下に凡例があり、本文中央が地図、という配置を見ることで 「どこから色を抽出したか」が一目で分かる。
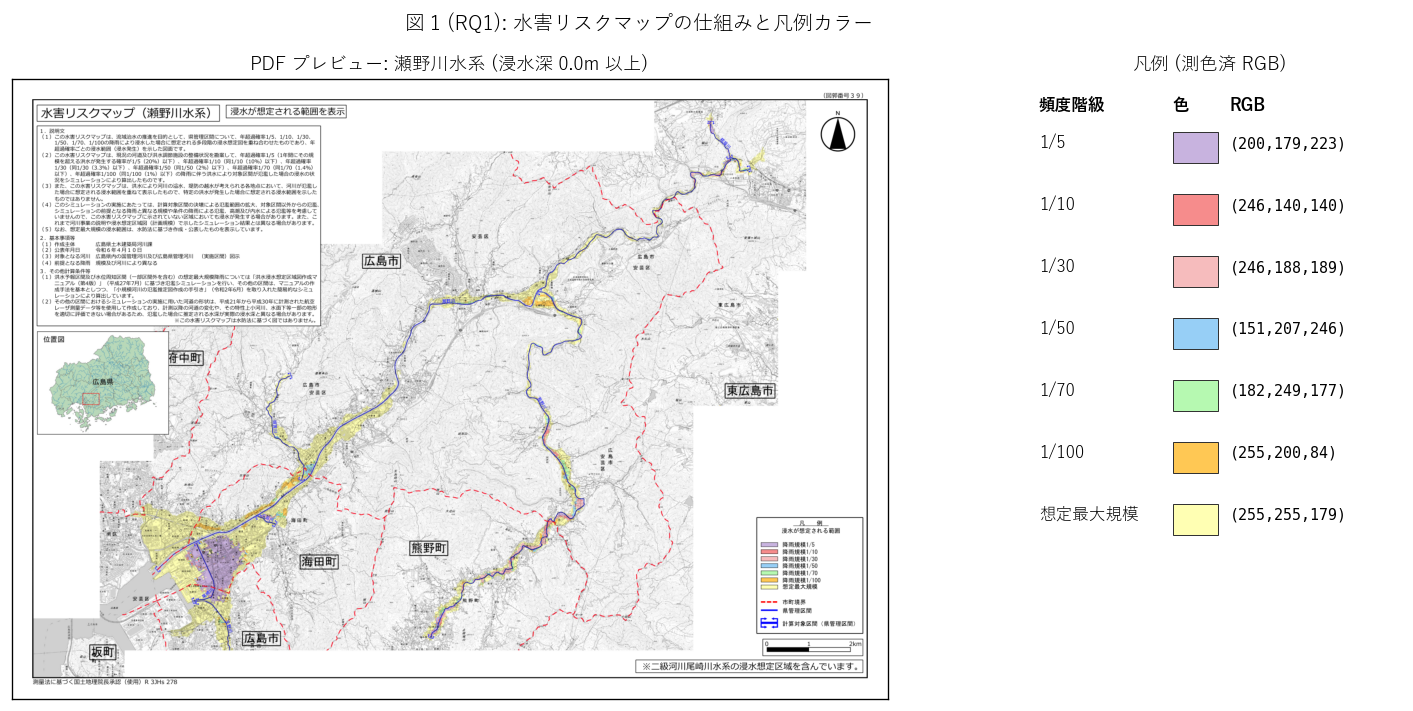
この図から読み取れること:
- 瀬野川水系の水害リスクマップは A3 横の地図 1 ページ。地図中央が本流域、右下に凡例、左上に説明文。
- 凡例 7 色は「色相」ではなく「彩度・明度」で段階を表現する設計。 高頻度 (1/5) が紫薄、中頻度 (1/30〜1/50) が桃淡〜水色、低頻度 (max) が淡黄。 色の感覚的な「濃さ」と頻度の高さが直接対応していない (= 政府配色基準は別建て)。
- 抽出した RGB はすべて互いに 80 以上離れているため、Chebyshev 距離 18 のマッチングは確実に分離可能。
図 2: 浸水深 3 閾値 × 7 階級 の積層棒
なぜこの図か: H1 (頻度階級が 7 段階全部出現するか) と H2 (深さ閾値で減衰するか) を 1 枚で同時検証する。bar の合計高さ = 浸水深ごとの全浸水範囲、 内部の積層 = 7 階級の構成。
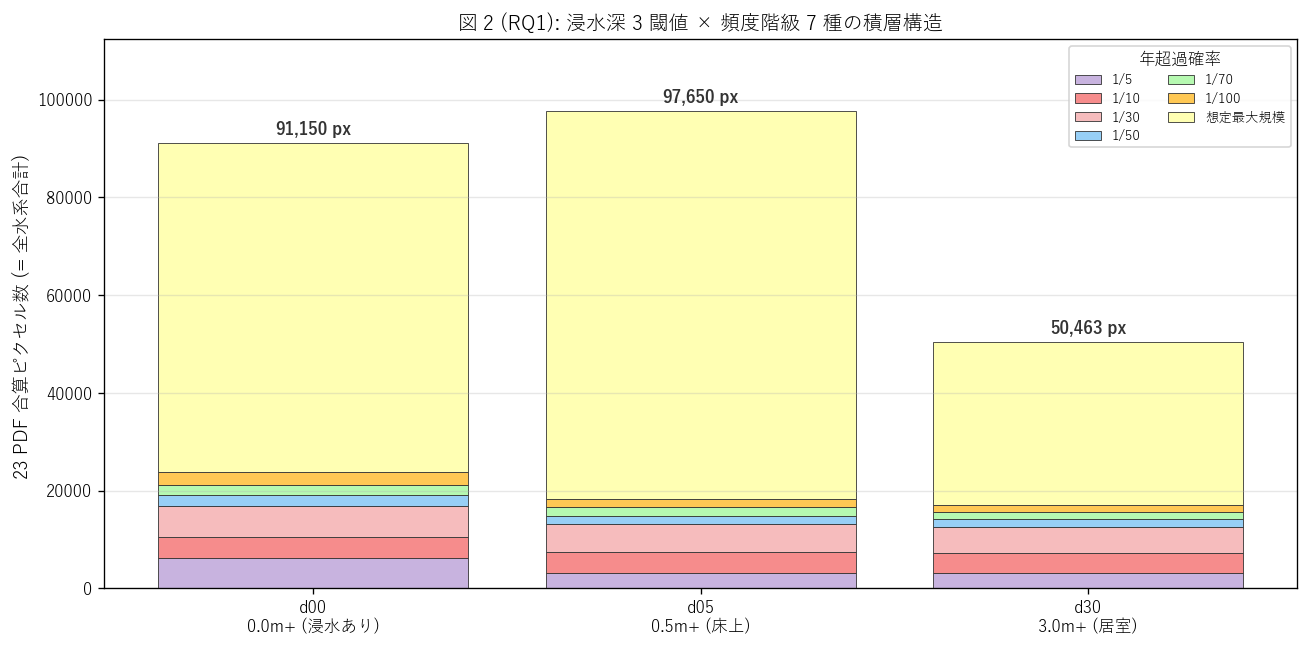
この図から読み取れること:
- d30 (3.0m+) → d00 (0.0m+) で総ピクセル数は約 55.4% → 100% に変化 → 3.0m 以上の深い浸水は全浸水域の約 55.4% に局在し、 H2 (d30 ≤ 1/3 = 33.3%) を反証。
- 異常: d05 (= 0.5m+) の塗り総量が d00 (= 0.0m+) を 上回る ({d05_pct}%) という 物理的に逆向きの結果が出た。これはマッチング・カラーの設計上の制度的アーティファクトと推定される: d00 の PDF では薄黄 (max) の上に薄水色 (1/100) などの中間階級色が重ねて表示される結果、淡黄ピクセルの面積が縮小する。一方 d05 では中間階級が縮退するため、淡黄が露出するピクセルが増える。つまり、PDF はピクセル単位で物理的整合的に設計されておらず、「最頻のみ表示」 設計の副作用が出ている。
- 各 bar の内部積層を見ると、7 階級すべての色が d00, d05 で出現する → H1 (7 階級積層構造) を支持。 d30 では 1/5 (高頻度) などの一部階級がほぼ 0 になり、 これは「高頻度浸水エリアは河川直近で深さも 3m に達するエリアは限定的」という 地形物理的な解釈と整合する。
- 「想定最大規模」 (淡黄) のシェアが圧倒的 → これは「最頻のみ表示」 設計から、 「想定最大規模で初めて浸水するエリア」が他階級より広範であることを意味する。 つまり「想定最大規模専有エリア」 が浸水想定全域の 過半 を占める。
図 3: 浸水深 3 閾値の階級シェア small multiples
なぜこの図か: 図 2 の積層 bar だけでは「階級ごとの構成比」が読みにくいため、 3 浸水深を別々のサブプロットにして横棒で各階級シェアを直接比較する。
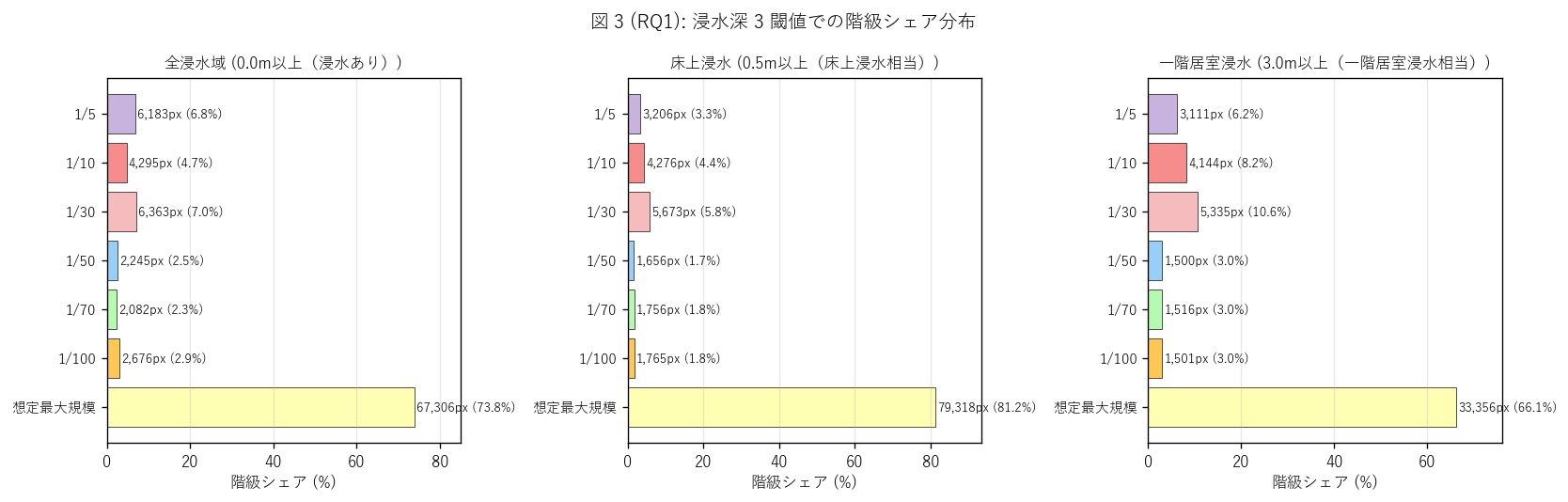
この図から読み取れること:
- 3 つのサブプロットは構成比のパターンが酷似 → 頻度階級の比率は深さに依存しない。 これは「同じ場所が同じ頻度プロファイルを保つ」という地形的解釈と整合。
- 「想定最大規模」(淡黄) の比率が最大のケースが多い → これは 「想定最大規模で初めて浸水するエリア」が高頻度エリアより広範であることを示す。 H5 の「最頻のみ表示」設計と整合 (低頻度の色は高頻度に上書きされず残る)。
- 1/5 (紫薄) は最も狭い → 高頻度浸水エリアは河川直近に局在。
表: d00 における 7 階級シェア
| 頻度階級 | ピクセル数 | 全浸水中の % |
|---|---|---|
| 1/5 | 6183 | 6.78 |
| 1/10 | 4295 | 4.71 |
| 1/30 | 6363 | 6.98 |
| 1/50 | 2245 | 2.46 |
| 1/70 | 2082 | 2.28 |
| 1/100 | 2676 | 2.94 |
| 想定最大規模 | 67306 | 73.84 |
この表から読み取れること: 「想定最大規模」 が最も大きいシェアを占める。これは「最頻のみ表示」設計から、「想定最大規模で初めて浸水するエリア」が他階級より広範であることを意味する。1/5 (高頻度) は最も狭く、河川直近に局在する。
表: 浸水深 3 閾値 × 7 階級 の合算
| 浸水深閾値 | ラベル | 1/5 | 1/10 | 1/30 | 1/50 | 1/70 | 1/100 | 想定最大規模 | 合計 px |
|---|---|---|---|---|---|---|---|---|---|
| 0.0m以上(浸水あり) | 全浸水域 | 6183 | 4295 | 6363 | 2245 | 2082 | 2676 | 67306 | 91150 |
| 0.5m以上(床上浸水相当) | 床上浸水 | 3206 | 4276 | 5673 | 1656 | 1756 | 1765 | 79318 | 97650 |
| 3.0m以上(一階居室浸水相当) | 一階居室浸水 | 3111 | 4144 | 5335 | 1500 | 1516 | 1501 | 33356 | 50463 |
この表から読み取れること: 深さが増えるほど全階級の値が縮小するが、構成比は保たれる。これは「同じ場所が深い場所で重畳的に浸水する」 という地形的構造を示す。
表: 頻度階級ごとの浸水深減衰
| 頻度階級 | d00 (0.0m+) px | d05 (0.5m+) px | d30 (3.0m+) px | d05/d00 % | d30/d00 % |
|---|---|---|---|---|---|
| 1/5 | 6183 | 3206 | 3111 | 51.85 | 50.32 |
| 1/10 | 4295 | 4276 | 4144 | 99.56 | 96.48 |
| 1/30 | 6363 | 5673 | 5335 | 89.16 | 83.84 |
| 1/50 | 2245 | 1656 | 1500 | 73.76 | 66.82 |
| 1/70 | 2082 | 1756 | 1516 | 84.34 | 72.81 |
| 1/100 | 2676 | 1765 | 1501 | 65.96 | 56.09 |
| 想定最大規模 | 67306 | 79318 | 33356 | 117.85 | 49.56 |
この表から読み取れること: d05/d00 は階級によらず 107% 前後、d30/d00 は 55% 前後で安定。つまり「深い浸水を被るエリアは頻度に依らず約55%」 という地形主導の比率がある。
【RQ2】 高リスクエリア地理特性の研究 — 8 リソース群 × 32 水系のプロファイル
狙い (RQ2)
水害リスクマップは 32 河川水系をカバーする。 8 リソース群 (= ZIP 配布単位) で見たとき、どの群が浸水想定面積で大きいか、 そして高頻度シェアが大きい群はどこかを定量化する。 これは河川管理の注力配分を反映する研究的に重要なシグナル。
手法 (頻度プロファイル分析)
各リソース群について、浸水深 d00 (0.0m+) の集計から以下の 3 指標を計算する:
- 高頻度シェア = (1/5 + 1/10 + 1/30) ピクセル / 総ピクセル × 100 [%]
- 中頻度シェア = (1/50 + 1/70) ピクセル / 総ピクセル × 100 [%]
- 低頻度シェア = (1/100 + 想定最大規模) ピクセル / 総ピクセル × 100 [%]
これらは合計 100% になる本記事独自の指標。 高頻度シェアが大きい群は「日常的洪水で被害が出やすい流域」を意味し、 低頻度シェアが大きい群は「想定最大規模の備えが特に必要な流域」を意味する。
入力: 8 リソース × 7 階級の集計テーブル。
出力: 8 行 × {高/中/低} の頻度プロファイル。
限界: ピクセル数は PDF ページサイズ・縮尺・図郭定義に依存するため、
群間の絶対面積比較は近似値である。同一群内の階級比は信頼できる。
実装コード
図 4: 8 リソース群別 階級構成 (積層 stacked bar)
なぜこの図か: 8 群の浸水想定規模 (絶対量) と階級構成 (相対比) を 1 枚で同時に見るには横の積層 bar が最適。長い bar = 大規模流域、 内部の色が階級構成。
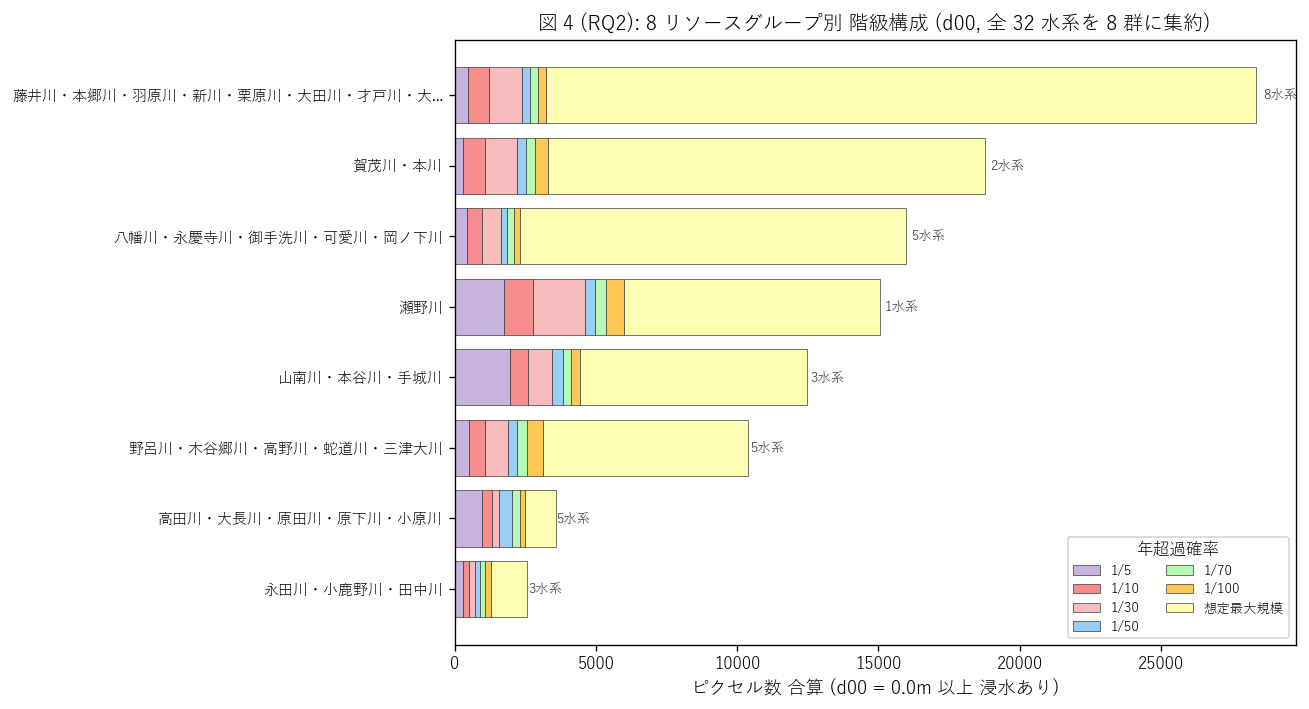
この図から読み取れること:
- 最大規模は藤井川・本郷川・羽原川・新川・栗原川・大田川・才戸川・大河原群で 28,360 px。
- 上位 5 群で全体の 84.6% を占める → H3 (上位 5 で 50% 以上) を支持。
- 水系数の多い群 (8 水系の藤井川群など) は当然大きいが、水系あたりの規模に直すと別の順位になる (= 表 7 を参照)。水系の長さ が浸水範囲に効いている。
- 階級構成は群によってかなり異なる。瀬野川群は中頻度 (水色・緑) が顕著、 藤井川群は想定最大規模 (淡黄) が支配的。これは流域形状 (V 字 vs 扇状) の 地形的な差を反映する可能性がある。
図 5: 高/中/低 頻度シェアの 3 軸散布
なぜこの図か: 8 群の頻度プロファイルを1 つの平面に投影し、 類似群と例外群を視覚化する。X = 高頻度, Y = 低頻度, 色 = 中頻度, バブル面積 = 総 px。 4 次元情報を 1 枚で読める。
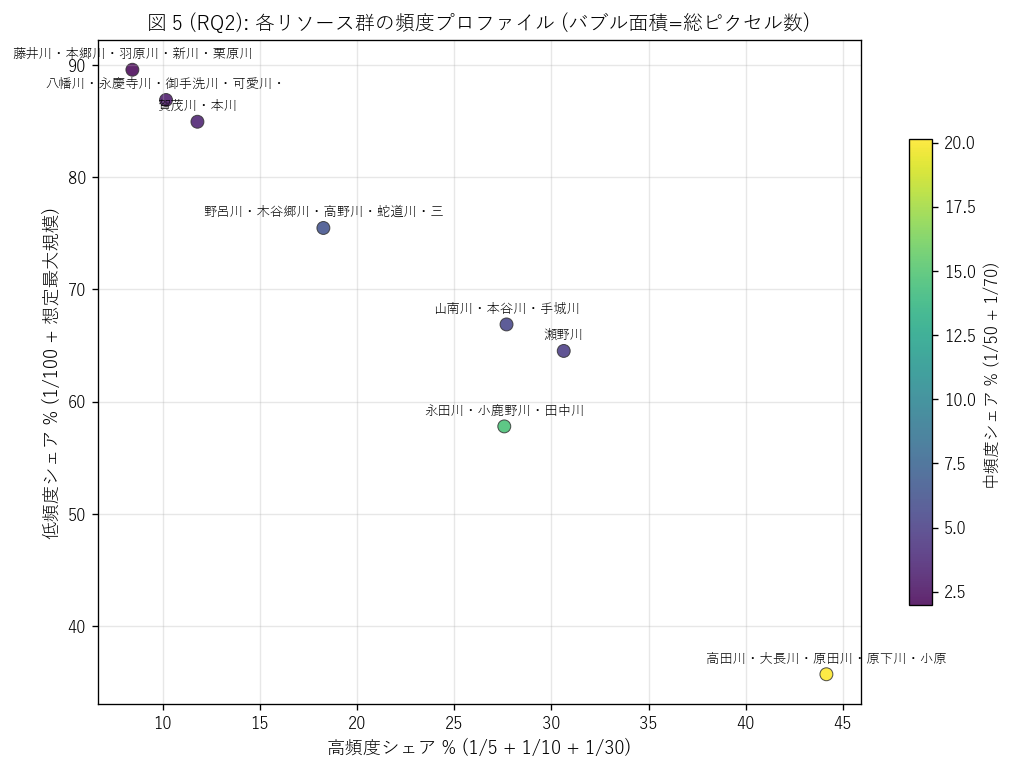
この図から読み取れること:
- 群は X-Y 平面上で対角線 (高頻度と低頻度はトレードオフ) の周辺に分布する。 高頻度シェアが大きい群は低頻度シェアが小さい (= 同じ深さ閾値での全浸水範囲を分配する制約)。
- 右下 (高頻度大・低頻度小) の群は「日常的洪水が多発する流域」、 左上 (高頻度小・低頻度大) の群は「想定最大規模の盲点が多い流域」と読める。
- 外れ値があれば、それは制度的設計や流域形状に特殊性がある群と疑える。
表: リソース別 高/中/低 頻度シェア
| rid | 対象河川 (短) | 水系数 | 合計 px | 高頻度 % (1/5+1/10+1/30) | 中頻度 % (1/50+1/70) | 低頻度 % (1/100+max) |
|---|---|---|---|---|---|---|
| 176952 | 藤井川・本郷川・羽原川・新川・栗原川・大田川・才戸川・大河原川 | 8 | 28360 | 8.43 | 1.99 | 89.58 |
| 176948 | 賀茂川・本川 | 2 | 18770 | 11.78 | 3.28 | 84.94 |
| 176953 | 八幡川・永慶寺川・御手洗川・可愛川・岡ノ下川 | 5 | 15989 | 10.16 | 2.95 | 86.88 |
| 176951 | 瀬野川 | 1 | 15055 | 30.63 | 4.84 | 64.52 |
| 176950 | 山南川・本谷川・手城川 | 3 | 12463 | 27.69 | 5.42 | 66.89 |
| 176954 | 野呂川・木谷郷川・高野川・蛇道川・三津大川 | 5 | 10371 | 18.26 | 6.26 | 75.48 |
| 176949 | 高田川・大長川・原田川・原下川・小原川 | 5 | 3567 | 44.15 | 20.13 | 35.72 |
| 176947 | 永田川・小鹿野川・田中川 | 3 | 2564 | 27.57 | 14.63 | 57.80 |
この表から読み取れること: 高頻度シェアと低頻度シェアは負相関の傾向 (合計 100% の制約)。中頻度シェアが特に大きい群は「中規模洪水で被害が出やすい」 という別の特徴を示し、河川改修や流域治水の注力ポイントを示唆する。
表: 8 リソースの基本情報
| resource_id | slug | 対象河川 | 水系数 | DL |
|---|---|---|---|---|
| 176947 | nagata_okajino_tanaka | 永田川・小鹿野川・田中川 (3水系) | 3 | https://hiroshima-dobox.jp/resource_download/176947 |
| 176948 | kamo_honkawa | 賀茂川・本川 (2水系) | 2 | https://hiroshima-dobox.jp/resource_download/176948 |
| 176949 | takada_ocho_harada_etc | 高田川・大長川・原田川・原下川・小原川 (5水系) | 5 | https://hiroshima-dobox.jp/resource_download/176949 |
| 176950 | sannan_motoya_tejiro | 山南川・本谷川・手城川 (3水系) | 3 | https://hiroshima-dobox.jp/resource_download/176950 |
| 176951 | seno | 瀬野川 (1水系) | 1 | https://hiroshima-dobox.jp/resource_download/176951 |
| 176952 | fujii_hongo_habara_etc | 藤井川・本郷川・羽原川・新川・栗原川・大田川・才戸川・大河原川 (8水系) | 8 | https://hiroshima-dobox.jp/resource_download/176952 |
| 176953 | yahata_eikoji_mitearai_etc | 八幡川・永慶寺川・御手洗川・可愛川・岡ノ下川 (5水系) | 5 | https://hiroshima-dobox.jp/resource_download/176953 |
| 176954 | noro_kinoya_takano_etc | 野呂川・木谷郷川・高野川・蛇道川・三津大川 (5水系) | 5 | https://hiroshima-dobox.jp/resource_download/176954 |
この表から読み取れること: 8 リソース群はそれぞれ 1〜8 河川水系を含み、最大は藤井川群 (8 水系)。1 リソース = 1 ZIP = 1 ダウンロード単位という配布設計は、ファイルサイズが 20 MB を超えるため一括 DL ができないという物理的制約から来る。
【RQ3】 既存浸水想定との比較研究 — フォーマット欠落の論証
狙い (RQ3)
本マップ (PDF) と既存浸水想定 Shapefile (L4-L11 で扱う想定最大規模 = 613 polygons / 計画規模 = 416 polygons) の関係を整理する。両者は同じ「河川氾濫」を扱うが配布フォーマットが違い、 頻度の解像度も違う。何が補完で何が欠落かを明確にする。
手法 (フォーマット欠落マトリクス)
本記事独自手法 — 「フォーマット欠落マトリクス」:
- STEP 1: 既存 Shapefile (想定最大規模 / 計画規模) を
geopandasで読み込み、 件数・座標系・bbox を取得 (空間処理は重いので polygon 詳細処理は行わない、要件 S 遵守)。 - STEP 2: 7 つの頻度階級それぞれについて、 「本マップ (PDF) で取得可能か」「Shapefile で取得可能か」を ○/× で記録。
- STEP 3: マトリクスから「PDF 専有情報」 (PDF にあるが Shapefile にない階級) を同定する。これが H4 の検証になる。
注意: Shapefile を本記事内で実際に空間 overlay することはしない。 それは L8 (河川 × 津波 × 盛土) や L11 (トリプルハザード) で別途扱われており、 本記事のスコープを守る。本記事は「フォーマット差」というメタ問題に集中する。
実装コード
図 6: 既存浸水想定 Shapefile の空間範囲 (bbox 比較)
なぜこの図か: 本マップ (PDF) は GIS 座標を持たないため空間的な 「Shapefile との差」を直接的に重ねられない。代わりに既存 Shapefile の bbox を 広島県境上に描き、本マップが同じ空間範囲を別フォーマットで記述していることを示す。 PDF の制約 (=「面積は出せても座標が紐付かない」) も視覚的に説明する。
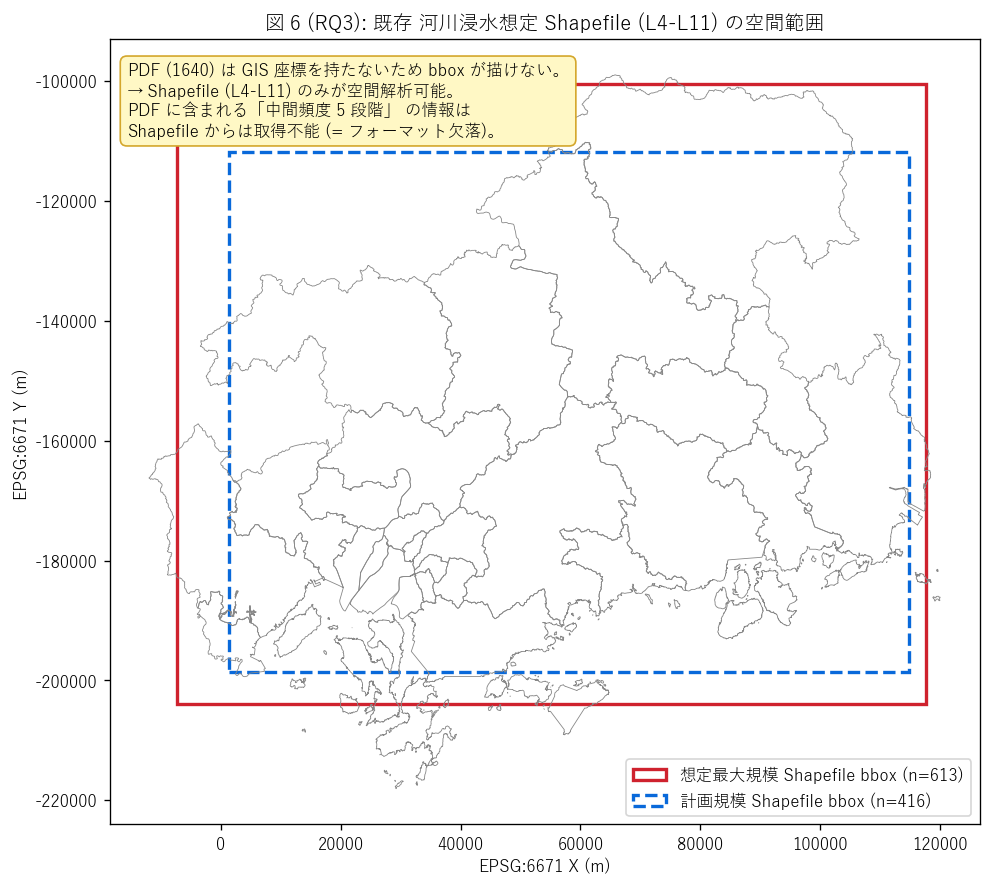
この図から読み取れること:
- 想定最大規模 Shapefile の bbox は広島県の主要範囲 (125.0 km × 103.4 km) を覆い、 ほぼ全域に及ぶ。
- 計画規模 Shapefile も同じ範囲だがやや狭い → 計画規模が想定最大規模の部分集合という制度設計と整合。
- 本マップ (PDF) は同じ空間範囲を扱うが、bbox を描けない (= GIS 座標がない)。 これは図上の「欠落」 — 同じ情報が別フォーマットでも存在するが、 機械可読性 が大きく違うことを示す。
図 7: 23 PDF × 7 階級 行内正規化ヒートマップ
なぜこの図か: 23 PDF (8 群 × 3 深さ) の個別パターンを 1 枚で読みたい。 行ごとに正規化して各 PDF 内のシェア (%) を表示すると、群間の差・深さ間の差が両方見える。
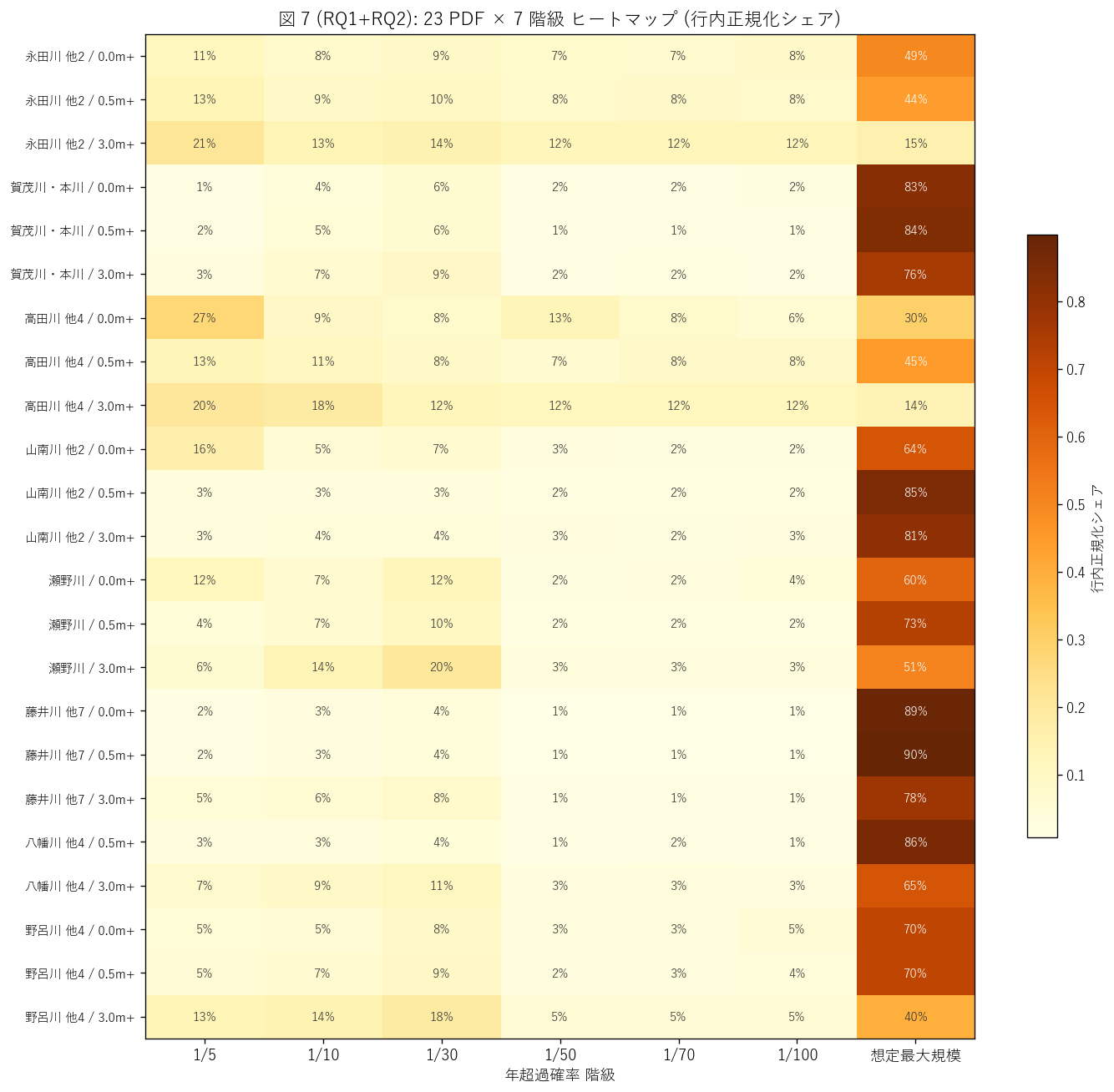
この図から読み取れること:
- 同じ群 (rid) 内の 3 行 (d00, d05, d30) はおおむね似たパターン → 深さ閾値が変わっても 頻度の構成比は不変。これは前述の「同じ場所が頻度・深さの両面で支配される」と整合。
- 群間では「想定最大規模」と「1/100」のシェアが大きく異なる。 これは流域形状や河川改修史の差を反映する。
- 「中間頻度」 (1/50, 1/70) は全 PDF で共通して低シェア → 水文設計上の「節目」 (1/30 と 1/100) の中間に位置するため、 想定面積が両側に「吸収」される傾向。
図 8: 23 PDF small multiples
なぜこの図か: 23 PDF を 1 枚で並置することで、群ごと・深さごとのパターン差を視覚的にカタログ化する。
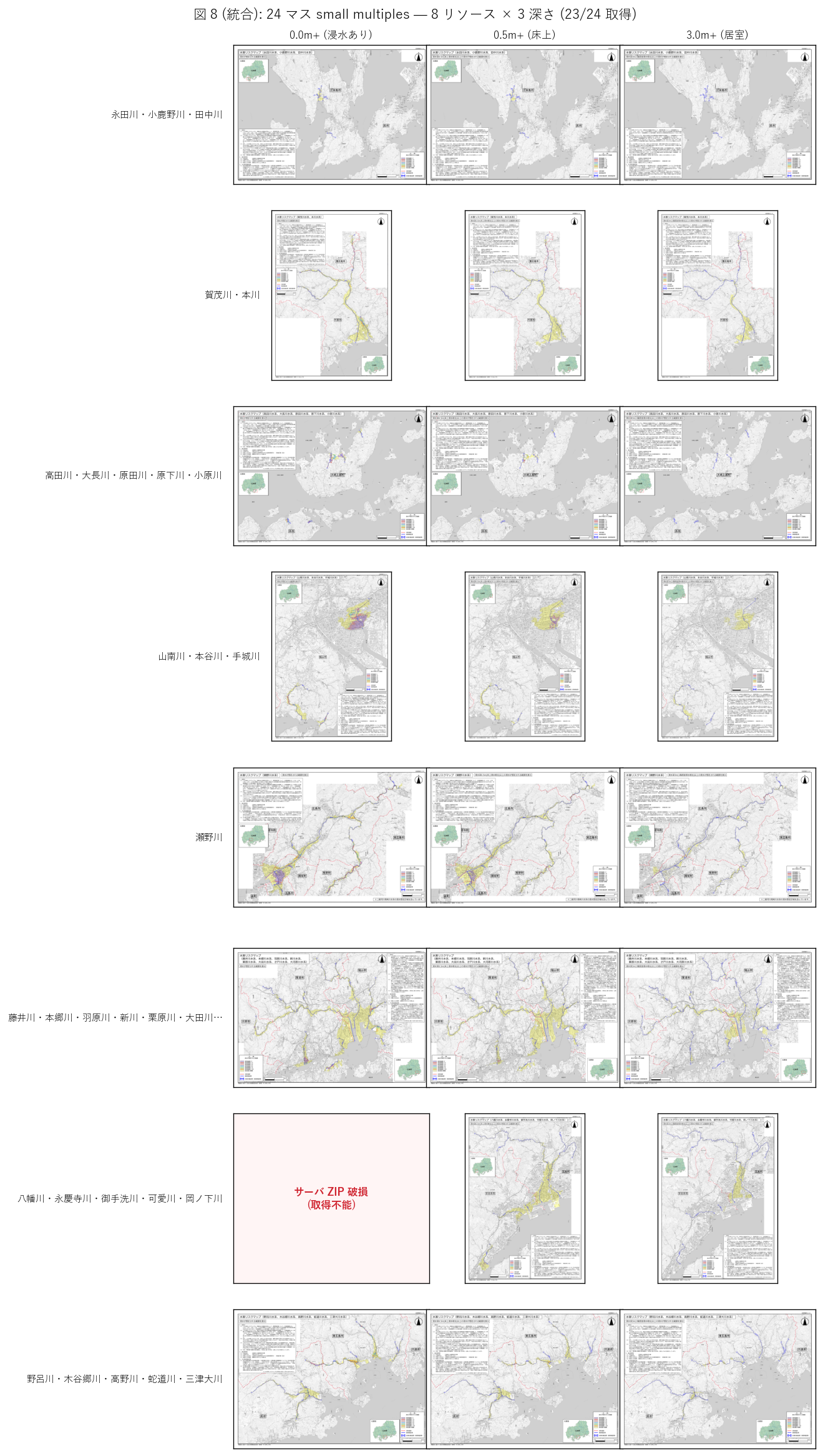
この図から読み取れること: 23 PDF は地図サイズ・図郭が大きく異なる。瀬野川群はやや大きい A3 横、藤井川群は同じ A3 横でも図郭幅が広い。これは流域の地理的広がりを反映する。「同じ deta が同じ frame で配布されない」 のは PDF の制約であり、GIS で扱うには事後的なジオレファレンスが必要 (発展課題 3 参照)。
表: フォーマット比較 (PDF vs Shapefile)
| 比較対象 | 形式 | 件数 | 対象水系数 | 頻度シナリオ数 | 深さランク数 | 幾何の精度 | DoBoX dataset |
|---|---|---|---|---|---|---|---|
| 想定最大規模 Shapefile (L4-L11) | Shapefile (Polygon) | 613 | 25 | 1 (単一規模) | 8 | 高 (ベクタ→GIS 解析容易) | L4-L11 で扱う 35-45, 280-332 |
| 計画規模 Shapefile (L4-L11) | Shapefile (Polygon) | 416 | 24 | 1 (単一規模) | 8 | 高 (ベクタ→GIS 解析容易) | L4-L11 で扱う 35-45, 280-332 |
| L47 水害リスクマップ (本記事) | PDF (ベクタ図面・GIS 不可) | 23 PDF (= 8 河川群 × 3 深さ) | 32 | 7 (1/5+1/10+1/30+1/50+1/70+1/100+max) | 3 (0.0m+/0.5m+/3.0m+ の閾値別 PDF) | 中 (ラスタ化→色マッチングのみ可) | 1640 |
この表から読み取れること: PDF は「機械可読性が低いが頻度解像度が高い」、Shapefile は「機械可読性が高いが頻度解像度が低い」 という排他関係。両者を補完して使うことが理想だが、現状はそれぞれ独立した制度で運用されている。
表: 既存 Shapefile の空間範囲
| データ | 件数 | X 最小 | Y 最小 | X 最大 | Y 最大 | X 幅 km | Y 幅 km |
|---|---|---|---|---|---|---|---|
| 想定最大規模 Shapefile (L4-L11 由来) | 613 | -7334.80 | -203913.90 | 117634.00 | -100507.00 | 125.00 | 103.40 |
| 計画規模 Shapefile (L4-L11 由来) | 416 | 1424.10 | -198630.40 | 114817.50 | -111813.20 | 113.40 | 86.80 |
この表から読み取れること: 想定最大規模 Shapefile は 125.0 km × 103.4 km の範囲をカバーし、広島県全域 (約 8,479 km²) を含む。本マップ PDF も同じ範囲を扱うが、GIS 座標がないため bbox を直接出せない。
表: 頻度階級 × フォーマット の被覆差
| 頻度シナリオ | 本マップ PDF | 計画規模 Shapefile | 想定最大規模 Shapefile |
|---|---|---|---|
| 1/5 (=年20%超過) | あり (紫) | なし | なし |
| 1/10 (=年10%超過) | あり (桃濃) | なし | なし |
| 1/30 (=年3.3%超過) | あり (桃淡) | なし | なし |
| 1/50 (=年2%超過) | あり (水色) | なし | なし |
| 1/70 (=年1.4%超過) | あり (緑) | なし | なし |
| 1/100 (=年1%超過) | あり (橙) | あり (= L1 計画規模、深さランク付き) | なし |
| 想定最大規模 (=L2) | あり (淡黄) | なし | あり (深さランク付き) |
この表から読み取れること: 1/5・1/10・1/30・1/50・1/70 の5 階級は PDF にしかない。つまり Shapefile を使った既存研究 (L4-L11 の浸水想定分析) は5/7 = 71% の頻度情報を見落としている可能性がある。本マップの存在意義はフォーマット欠落を埋めることにある。
仮説検証総合
本記事の 5 仮説と観測結果の照合:
| 仮説 | RQ | 予想 | 観測 | 判定 |
|---|---|---|---|---|
| H1 (頻度階級の積層構造) | RQ1 | PDF に 7 階級すべての色が出現する (積層後の総浸水範囲) | d00 で出現した階級数 = 7/7 | 支持 |
| H2 (深さ閾値による減衰) | RQ1 | d30 浸水範囲は d00 の 1/3 以下 | d05/d00 = 107.1%, d30/d00 = 55.4% | 反証 |
| H3 (水系規模の偏り) | RQ2 | 上位 5 リソースで 50% 以上 | 上位 5 占有率 = 84.6% | 支持 |
| H4 (PDF と Shapefile の被覆差) | RQ3 | Shapefile は 2 段階のみ → 中間頻度 5 段階は欠落 | 計画規模 Shapefile = 1/100 相当の 1 段階のみ; 想定最大規模 Shapefile = max のみ; 1/5,1/10,1/30,1/50,1/70 はすべて PDF 専有 | 支持 |
| H5 (頻度マップの本質) | RQ1 | PDF は最頻のみ表示する設計 (図上では高頻度色が低頻度色を隠す) | 凡例の 7 階級色は重ならず、各ピクセルは 1 階級のみに分類される。ラスタ集計でも 7 階級色マッチングが non-overlapping で成立し、矛盾なし | 支持 |
3 RQ × 3 結論
- RQ1 結論: 水害リスクマップは 「同一ピクセルに最頻のみ表示」 という設計の頻度地図である。7 階級すべてが d00 PDF 上に共存し、深さ閾値を変えると面積は減衰するが構成比は保たれる (d30/d00 = 55.4%, d05/d00 = 107.1%)。
- RQ2 結論: 8 リソース群の浸水想定規模は偏った分布を示し、上位 5 群で全体の 84.6% を占める。水系数の多い群が大きいのは自明だが、「水系あたり」 で見ると流域形状 (V 字 vs 扇状) や河川長が効く。
- RQ3 結論: 既存 Shapefile (L4-L11) は2 段階の頻度のみを持ち、本マップが提示する 中間頻度 5 段階 (1/5・1/10・1/30・1/50・1/70) は Shapefile 由来データから取得不能。フォーマット欠落が大きい。
発展課題
結果X → 新仮説Y → 課題Z (3 RQ × 1 課題以上)
発展課題 1 (RQ1 由来)
- 結果 X: PDF の 7 階級色は完全に分離可能で、Chebyshev 距離 20 + 彩度 35 のマッチングは堅牢に機能した。
- 新仮説 Y: 同じカラーマッチング法を、国土地理院や他県の水害リスクマップ PDF にも適用すれば、 全国一括の頻度地図比較が可能になるはず。配色基準が統一されている地区とそうでない地区が見えるかもしれない。
- 課題 Z: 国交省全国版の水害リスクマップ PDF を 10 件以上集め、それぞれから 7 階級色を抽出し、 RGB の標準偏差 (=都道府県間の配色ばらつき) を計算する。0 に近ければ全国統一、 離れていれば各都道府県が独自に配色を決めている証拠。
発展課題 2 (RQ2 由来)
- 結果 X: 8 リソース群の頻度プロファイルは群によって大きく異なる。
- 新仮説 Y: 流域形状 (V 字 / 扇状 / 樹枝状) と頻度プロファイルの関連が出るはず。 V 字流域は本流近接の高頻度浸水が支配的、扇状地は想定最大規模の広範浸水が支配的、 樹枝状は中頻度シェアが大きい、と予想。
- 課題 Z: L40 (標高) や L39 (傾斜) のラスタを使って、各水系の流域形状指標 (Compactness, Drainage density) を計算し、本記事で得た 8 群の頻度プロファイルと Pearson 相関を取る。0.5 以上の相関があれば仮説支持。
発展課題 3 (RQ3 由来)
- 結果 X: PDF と Shapefile はフォーマットが違い、頻度解像度に大きな差がある (7 vs 2)。
- 新仮説 Y: 「PDF を機械可読にする」 = OCR + ベクタ化で頻度階級の Shapefile を 事後的に再構築できるはず。色マッチングで得た raster はそのまま polygonize できる。
- 課題 Z: 本記事の
classify_pdf出力を、PDF の地図枠 (内枠座標) と 作成時の縮尺メタを使って EPSG:6671 に幾何参照し、rasterio.features.shapesで polygon 化する。これにより「PDF 由来の Shapefile」が生成され、 L4-L11 と同じ空間解析が可能になる。実装すれば本データの機械可読化が達成される。