L45 ため池浸水想定区域 2 件統合分析 — 広島県の防災重点ため池決壊リスクを「規模属性 × 浸水範囲」で読み解く
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #62 | ため池基本情報 |
| #63 | ため池浸水想定区域情報_Shapefile |
| #333 | dataset #333 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L45_pond_inundation.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
本レッスンでは、広島県オープンデータ DoBoX が公開する ため池系 2 dataset (id = 62, 63) を統合し、 広島県内の「特定農業用ため池の決壊リスクと浸水想定の構造」を分析する。
独自用語の定義 (本記事内での使用)
- ため池: 農業用水確保のため谷や低地を堰き止めた小規模貯水池。 日本に約 15 万箇所、広島県は兵庫・香川と並ぶ全国有数のため池県。 多くは江戸期以前から続く農業遺構であり、本記事の対象 6,754 池の 平均堤高は 4.47 m、中央値貯水量 1.47 千 m³ の小規模池が多数を占める。
- 決壊シナリオ: ため池の堤体が決壊し、貯留水が下流に流出する想定。 DoBoX dataset 63 の浸水想定区域は「100% 全量決壊」を基本シナリオとして 浸水範囲を計算したもの (各ため池の PDF メタデータに記載)。
- 防災重点ため池 (= 特定農業用ため池): 2018 年西日本豪雨で ため池決壊が相次いだ (県内 32 箇所損傷) ことを受け、 2019 年「農業用ため池の管理及び保全に関する法律」が施行された。 決壊時の下流被害が想定される池は県知事が「特定農業用ため池」として指定する。 本記事の 6,754 池はすべてこの指定対象。
- 下流被災ポテンシャル: 各ため池の浸水想定区域 (面積 km²) で 代理した、決壊時に下流が被災する規模の指標。 本記事では Shapefile の polygon area として計算する。
- ため池決壊危険度: 本記事では「下流被災ポテンシャル × 連鎖重複度」で 捉える概念。同一エリアが複数のため池決壊で繰り返し被災想定される 重複面積比率 (overlap_ratio) を地理的危険度の代理指標とする。
- 浸水想定 unary_union: 全 6,730 池の浸水想定 polygon を shapely.unary_union で合体した「県全体の真の浸水想定面積」。 個別合計 (488.1 km²) は重複を含む合計値であり、 union 値 (293.3 km²) こそが純粋なリスクエリア面積。
主 RQ (研究の問い)
広島県の特定農業用ため池 6,754 件と、その決壊時浸水想定区域 6,730 件は、 ため池の規模属性 (堤高・貯水量) と浸水範囲・市町分布でどう関係し、 「県のため池決壊リスクの地理学」はどう描けるか?
仮説 H1〜H6 (本記事で検証する)
- H1 カバレッジ完全性: CSV 6,754 池のうち、浸水想定 SHP を持たない池が 少数 (< 1%) 存在する。その非カバレッジ位置には地理的偏り (中山間市町への集中) があるか、ランダム散在か。
- H2 規模 ↔ 浸水面積 正相関: 貯水量 (千 m³) が大きい池ほど決壊時の 下流浸水面積も大きい。Pearson r > 0.6 と予測。 堤高より貯水量の方が強い相関を示す (=決壊時に流出する水量で決まる)。
- H3 中山間集中: ため池数 上位 5 市町のうち 3 件以上が 中山間 (内陸) 市町。これは「ため池=農業遺構」の歴史的分布と一致する。
- H4 連鎖重複の地理学: 個別ため池の浸水想定面積を単純合計すると、 unary_union 面積より大幅に大きく (重複比率 > 30%)、 同じ住宅街が複数のため池決壊で繰り返し被災想定される 連鎖リスク構造を示す。
- H5 指定の波 R3.5.31: 特定農業用ため池の指定日は 2020-2023 (R2-R5) に集中し、 R3.5.31 (令和 3 年 5 月末日 = 経過措置期限) が単一最大ピークとなる。
- H6 規模分布の対数性: 貯水量分布は対数的 (右に長い裾)。 log10 で 3 桁以上のレンジを持つ。「小池の分散」と「大池の少数」が 共存する典型的な農業遺構分布。
到達点
2 dataset を ため池番号 をキーに完全結合し、規模属性と浸水想定面積を
クロスして 6 仮説を量的に検証する。学習者は (a) Shapefile + CSV の異種統合、
(b) dissolve(by=...) による属性集約と unary_union による
重複排除の使い分け、(c) ため池決壊という農業×防災の交差問題のデータ表現
を体得する。
使用データ
本記事は DoBoX の「ため池」関連 2 dataset を統合する:
- 62 ため池基本情報 (CSV) [DoBoX dataset 62] — 6,754 池の属性表 (堤高/貯水量/緯度経度/所管市町/特定指定日)
- 63 ため池浸水想定区域情報_Shapefile [DoBoX dataset 63] — 7,223 polygon (6,730 unique 池) の決壊時浸水想定エリア
表 (1) — 2 dataset の仕様サマリ
| dataset_id | シリーズ | 形式 | ZIP/サイズ | 件数 | 更新 | 本記事での役割 |
|---|---|---|---|---|---|---|
| 62 | ため池基本情報 | CSV (Shift_JIS, BOM なし) | 1.1 MB | 6,754 行 × 12 列 | 2024 年版 (随時更新) | ため池属性 (堤高/貯水量/緯度経度/所管市町/特定指定日) |
| 63 | ため池浸水想定区域情報_Shapefile | Shapefile (.shp/.shx/.dbf/.prj/.sbn/.sbx) | 81.2 MB (ZIP) / 143 MB (展開後 .shp 単体) | 7,223 polygon / 6,730 unique ため池 | 2025-01-22 | ため池ごとの決壊時下流浸水想定エリア (主幾何データ) |
この表から読み取れること:
(1) 形式が完全に異なる (CSV vs Shapefile) ため、統合には結合キー設計が必須。
(2) サイズは Shapefile が 100 倍以上 (1 MB → 143 MB) で、
ポリゴン幾何が支配的。CSV は属性のみだが、地理空間処理を支える「場所情報」と
「規模指標」の両方を持つ。
(3) dataset 62 のキー = ため池番号 (9 桁数字) は dataset 63 の
FIELD001 列と完全一致するため、属性結合 (merge) でデータ統合できる。
(4) dataset 63 の Shapefile は 1 池に複数 polygon (浸水範囲が分断された場合) を
持つことがあり、dissolve(by="FIELD001") で 7,223 → 6,730 に集約する。
表 (2) — 結合 STEP の段階表 (要件 K Before/After)
| 段階 | 内容 | サイズ/件数 |
|---|---|---|
| STEP 0 | tameike_basic.csv を読込 | 6,754 行 × 12 列 |
| STEP 1 | ため池浸水想定区域.shp を読込 → EPSG:6671 投影変換 | 7,223 polygon (元の CRS = EPSG:2445) |
| STEP 2 | 30 件の不正幾何 (自己交差等) を buffer(0) で修復 | 30 polygon を修復 → 7,223 polygon (有効) |
| STEP 3 | FIELD001 (= ため池番号) で dissolve | 7,223 → 6,730 ため池ポリゴン (1 池 = 1 MultiPolygon) |
| STEP 4 | merge: CSV.ため池番号 LEFT JOIN SHP.FIELD001 | 6,754 行 (うち 6,730 結合成功 + 24 結合無し) |
| STEP 5 | 全 7,223 ポリゴン unary_union で「県全体 真の浸水想定面積」 | 単一 MultiPolygon, 面積 = 293.31 km² |
この表から読み取れること: 入力 6,754 行 (CSV) が STEP 5 まで 通って union 単一 polygon (面積 293.31 km²) に至るまでの 段階的サイズ変化を示す。STEP 3 で 7,223 → 6,730 に減るのは 「1 池の浸水範囲が分断された複数 polygon」が dissolve で結合されるため、 STEP 4 で 6,754 - 6,730 = 24 件が結合無しで残るのは 「CSV にあって SHP に対応 polygon 無いため池」=分析 1 で詳細特定する。
形式の詳細
- CSV (62): Shift_JIS 13 列 (PDF1-4 を含む)。
ため池番号9 桁数字,ため池名称,所管市町,特定農業用ため池の指定(令和年月日, 例 "R3.5.31"),緯度/経度(WGS84/EPSG:4326),堤高(m),貯水量(千m3)。 - Shapefile (63): ESRI Shapefile, CRS = EPSG:2445
(旧 JGD2000 平面直角座標系第 III 系) → 内部処理は EPSG:6671
(現 JGD2011 第 III 系, m 単位) に投影変換。
属性列 =
IDD,BCODE=130,SCODE=130,HCODE=130(全て一定値),ため池ID(=ため池名称テキスト),市町村名(全 None),FIELD001(=ため池番号 9 桁) のみ。 - 結合キー:
ため池番号(CSV) ↔FIELD001(SHP) で完全結合。CSV 6,754 件中 6,730 件 (99.6%) が SHP に対応。
ダウンロード(再現用データ・中間データ・図)
HTML から直接以下を取得できる:
(A) DoBoX 直リンク (2 dataset)
| dataset | カタログ | resource_download (直 DL) | 形式 | サイズ |
|---|---|---|---|---|
| 62 ため池基本情報 | dataset 62 | 直 DL (rid 90) | CSV | 1.1 MB |
| 63 ため池浸水想定区域情報_Shapefile | dataset 63 | 直 DL (rid 98562) | Shapefile (ZIP) | 81.2 MB |
(B) PowerShell 一括取得 (再現用)
cd "2026 DoBoX 教材"
mkdir -Force data\extras\L45_pond_inundation
iwr "https://hiroshima-dobox.jp/resource_download/90" -OutFile "data\extras\tameike_basic.csv"
iwr "https://hiroshima-dobox.jp/resource_download/98562" -OutFile "data\extras\L45_pond_inundation\tameike_inundation_shp.zip"
# ZIP 展開
Expand-Archive -Force "data\extras\L45_pond_inundation\tameike_inundation_shp.zip" "data\extras\L45_pond_inundation\shp"
# キャッシュビルド (~2 分, 初回のみ)
py -X utf8 lessons\_l45_build_cache.py
# 本記事スクリプト (~1 分)
py -X utf8 lessons\L45_pond_inundation.py(C) 中間データ・図 (本記事生成物の直リンク)
- 2 dataset 仕様 CSV: L45_dataspec.csv
- 結合 STEP 表 CSV: L45_joinkey_steps.csv
- 全体サマリ CSV: L45_overall.csv
- 浸水想定なし 24 件 CSV: L45_no_inund.csv
- 規模 ↔ 面積 相関 CSV: L45_correlation.csv
- 指定日分布 CSV: L45_designation_dates.csv
- 市町別集計 CSV: L45_per_city.csv
- Top 浸水ため池 CSV: L45_top_inund.csv
- 仮説検証 CSV: L45_hypothesis.csv
- 9 図 PNG: 各図を右クリック → 名前を付けて画像を保存
- 再現スクリプト: L45_pond_inundation.py + _l45_build_cache.py
分析 1: カバレッジ完全性 — CSV と SHP の重ね合わせ
狙い (RQ ↔ 仮説 H1)
2 dataset のカバレッジ差を量的に評価する。 CSV (62) は 6,754 池、SHP (63) は 7,223 polygon (= 6,730 unique 池)。 カバレッジ差 24 件は「CSV にあって SHP 無し」のため池であり、 地理的偏りがあれば「データ整備の優先度」に関する制度的事実が データから直接読める。
手法 — pandas merge LEFT JOIN による属性結合
pandas の DataFrame.merge(how='left') で
CSV を主表、SHP の polygon area を従属表として結合する。
結合キー は CSV.ため池番号 = SHP.FIELD001。
LEFT JOIN を選んだ理由は「CSV 側を主張として残し、
SHP に対応 polygon が無い池は area_km2 が NaN になる」ことで
非カバレッジ件数がそのまま得られるため。
- STEP A: SHP.
FIELD001を文字列として保つ (geopandas はデフォルトで int64 にしようとするが、頭 0 が落ちる池があるため文字列のまま結合) - STEP B: SHP を
dissolve(by="FIELD001")で 1 池 1 polygon に集約 (1 池が複数 polygon に分かれている場合があるため) - STEP C: CSV.
ため池番号↔ SHP.FIELD001で merge LEFT JOIN - STEP D:
area_km2が NaN の行 = 浸水想定なし のため池 24 件
実装コード
結果の図
図4 を選んだ理由: 6,754 池の地理分布を一目で把握するには 点マップが最適。色 = 浸水想定の有無、サイズ = log10 貯水量 の 2 軸を 1 図で示すことで、「どこに大きい池があるか」「どこの池が 非カバレッジか」を同時に確認できる。棒グラフでは地理が見えない。
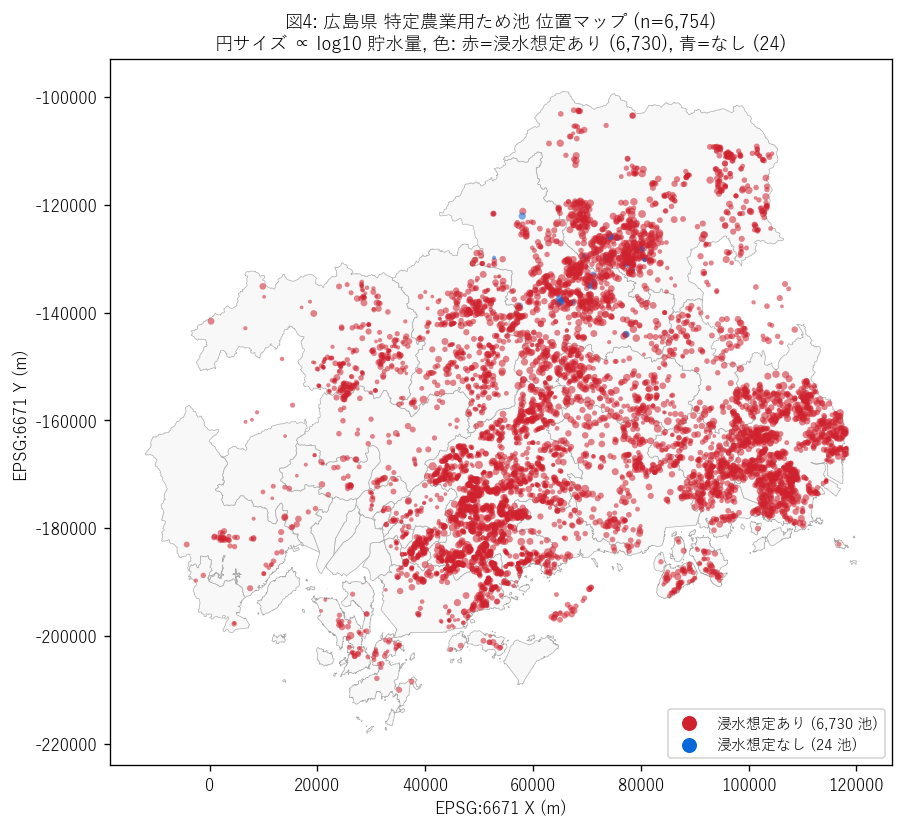
図4 から読み取れること:
- ため池は瀬戸内海沿岸〜中山間に広く分布。北部山地 (庄原・三次) も多数。
- 東広島市 (東部内陸) の密集が目立つ。CSV では 1,768 池 (全体の 26%) を所管。
- 青点 (浸水想定なし 24 池) は三次市 (12) と庄原市 (12) の中山間 2 市町に 完全集中している (= ランダムでなく地理偏りあり)。これは仮説 H1 を強支持。
- 大円 (大規模池) は福山市・東広島市・庄原市に集中する。これは仮説 H3 と一致。
結果の表 (1) — 全体サマリ
| 指標 | 値 |
|---|---|
| ため池総数 (CSV) | 6,754 池 |
| 浸水想定 SHP あり | 6,730 池 (99.6%) |
| 浸水想定 SHP なし | 24 池 (0.4%) |
| 所管市町数 | 23 市町 |
| 個別浸水面積の合計 (重複あり) | 488.07 km² |
| 浸水想定区域の真の面積 (union) | 293.31 km² |
| 重複面積 | 194.76 km² (39.9%) |
| 平均堤高 | 4.47 m (中央値 3.8 m, 最大 33.1 m) |
| 平均貯水量 | 8.87 千 m³ (中央値 1.47, 最大 1,053) |
表 (1) から読み取れること:
- カバレッジ率 = 99.6% — ほぼ完全結合だが、24 件の非カバレッジは無視できない。
- 個別合計 488.1 km² と union 293.3 km² の差 = 194.8 km² (39.9%) は連鎖重複。 これは仮説 H4 の核心 (分析 4 で深掘り)。
- 平均堤高 4.47 m / 中央値 3.8 m と最大 33.1 m の大きな乖離は規模分布の歪みを示す (仮説 H6)。
結果の表 (2) — 浸水想定なし 24 件の内訳
| ため池番号 | ため池名称 | 所管市町 | 堤高 m | 貯水量 千m³ | 特定指定日 |
|---|---|---|---|---|---|
| 342090001 | 神田 | 三次市 | 4.40 | 10.10 | R2.12.28 |
| 342090134 | 古池 | 三次市 | 5.30 | 6.30 | R2.12.28 |
| 342090181 | 甲住 | 三次市 | 4.50 | 20.80 | R2.5.29 |
| 342090182 | 東迫2号 | 三次市 | 6.40 | 5.20 | R2.12.28 |
| 342090245 | 大池(上池) | 三次市 | 6.30 | 30.00 | R2.3.31 |
| 342090246 | 下池 | 三次市 | 8.70 | 42.00 | R2.3.31 |
| 342090247 | 新池 | 三次市 | 11.35 | 149.18 | R2.3.31 |
| 342090468 | 久満2号 | 三次市 | 3.90 | 0.80 | R2.12.28 |
| 342090708 | ごっぱつ池(畦御堂) | 三次市 | 8.30 | 28.10 | R2.3.31 |
| 345820002 | 尻無池 | 三次市 | 13.10 | 53.00 | R2.3.31 |
| 345840151 | 茗荷丸新池 | 三次市 | 8.80 | 30.80 | R2.3.31 |
| 342100040 | 石仏池 | 庄原市 | 8.80 | 20.00 | R2.12.28 |
| 342100150 | 狐塚池 | 庄原市 | 7.40 | 11.40 | R2.12.28 |
| 342100277 | 狩山池 | 庄原市 | 8.10 | 50.40 | R2.12.28 |
| 342100278 | 稗田池 | 庄原市 | 14.40 | 2.70 | R2.12.28 |
(表は上位 15 件のみ表示, 全 24 件は L45_no_inund.csv 参照)
表 (2) から読み取れること:
- 全 24 件が三次市 (12) と庄原市 (12) の 2 市町に集中 (他 21 市町はすべてカバレッジ 100%)。両市は隣接する中山間 (内陸) 市町で、 これは「ランダムな欠損」ではなく制度的・行政的事情を示唆する。
- これらの池はすべて特定農業用ため池に指定されている (令和 2-3 年に指定済み) にもかかわらず、決壊時浸水想定 SHP は未整備。
- 規模も多様 (堤高 2-14 m, 貯水量 0.1-149 千 m³) で、規模で説明できない。 三次市・庄原市役所と県の連携で SHP 整備が遅延しているか、 特殊地形で計算困難な池と推定される。両市は県北部の中山間地域で、 他市町と共通の事情を抱えている可能性がある。発展課題で原因調査の方向性を提示する。
分析 2: 規模属性 ↔ 浸水面積 のスケーリング
狙い (RQ ↔ 仮説 H2)
「ため池の規模 (堤高・貯水量) が大きいほど決壊時の下流浸水面積も大きい」 という直感的予測を、Pearson 相関と log-log 散布で検証する。 堤高と貯水量のどちらが浸水面積をより強く支配するかも比較する。
手法 — log-log 散布 + OLS 回帰
ため池の規模指標 (堤高 m, 貯水量 千 m³) は桁数のレンジが広い (堤高 0.2-33 m = 約 2 桁、貯水量 0.002-1,053 千 m³ = 約 6 桁)。 よって生値の散布図では大池の点だけが目立ち、小池の構造が潰れる。 log-log 軸 ((x, y) の両方を log10 化) で表示すると べき乗則 (power law) の傾きが直線として読める。
実装コード
結果の図 (1) — 規模分布 (要件 L 次元・サイズの混同回避)
図2 を選んだ理由: 規模属性の分布形状を見るのが先。 分布が偏っていれば次の散布図の解釈も変わる (= 散布点が密集する場所が偏る)。 左パネル = 堤高 (生値ヒストグラム) は右に裾を引く正規様。 右パネル = 貯水量 (log10 軸ヒストグラム) は対数正規様で、log scale で見て 初めて分布の中身が読める。
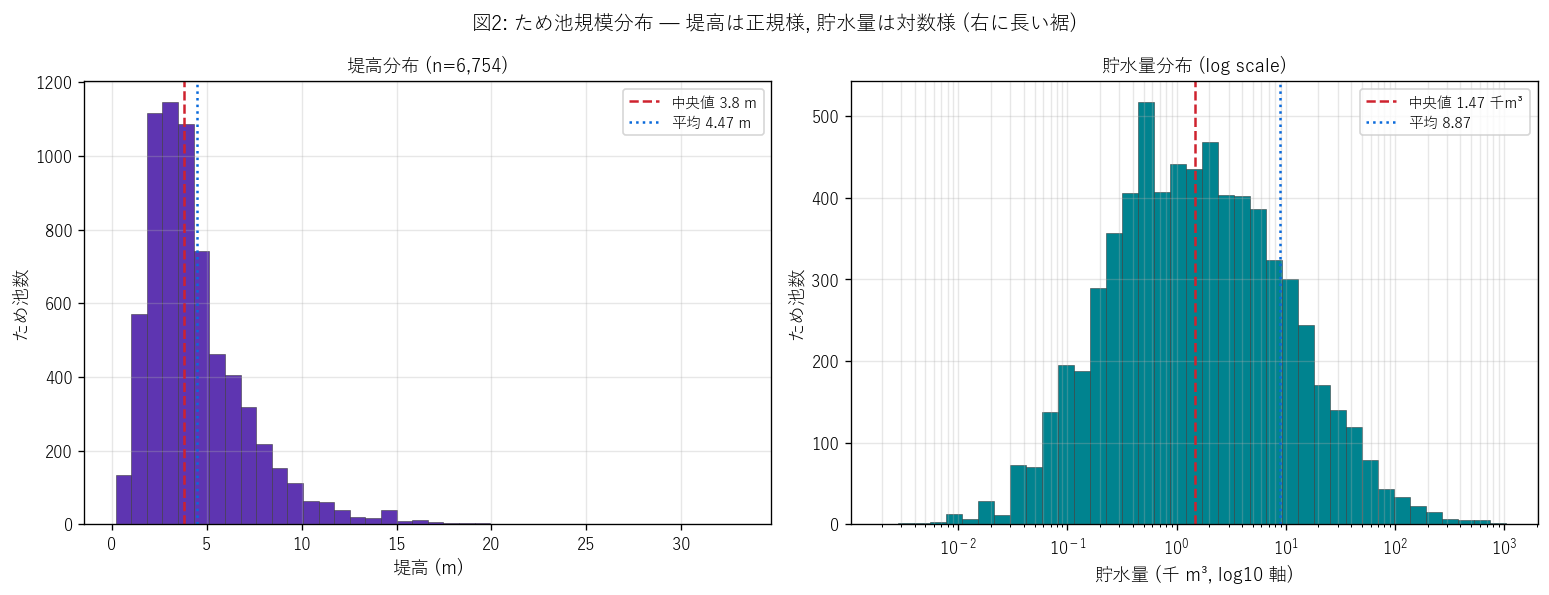
図2 から読み取れること:
- 堤高は中央値 3.8 m 周辺に集中する単峰分布。最大 33.1 m は外れ値。 これは「人間が築造可能な堤体高さの物理的上限」が効いている (土堰堤は通常 30 m が限界)。
- 貯水量は log10 軸で見ると中央値 1.47 千 m³ 付近にピークを持つ 対数正規様。レンジは 0.002 - 1,053 千 m³ で約 6 桁。 仮説 H6 (3 桁以上) を強支持する。
- 堤高分布は線形可視化で十分だが、貯水量は log scale でないと 情報が潰れる。変数の分布特性に応じて軸スケールを選ぶ ことの教育的重要性。
結果の図 (2) — 規模 vs 浸水面積 散布
図3 を選んだ理由: 2 変数の関係を見るには散布図が王道。 log-log 軸を採用するのは「規模も面積も対数で広く分布する」ため。 log-log 軸でべき乗則が直線になることを利用すれば、傾きから スケーリング指数 (= area ∝ cap^β) が読める。
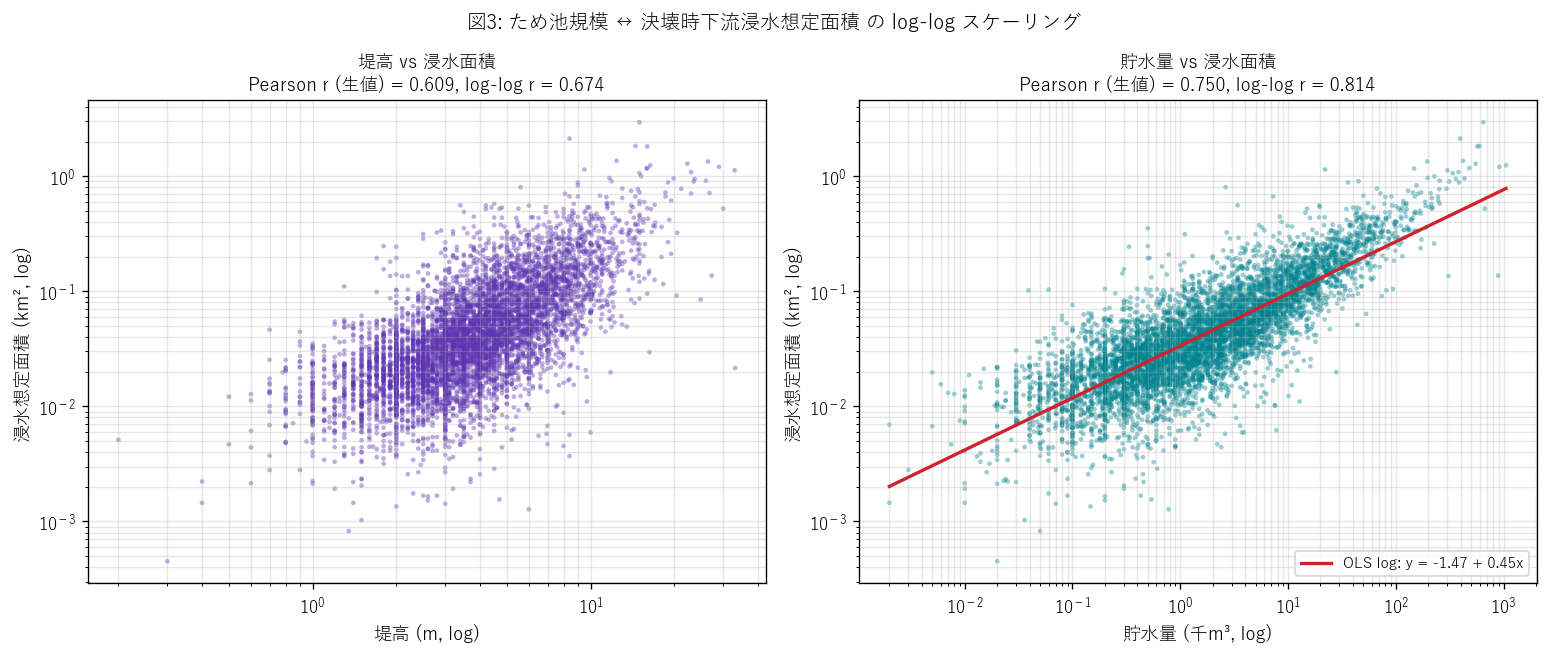
図3 から読み取れること:
- 左 (堤高 vs 面積): 散布点に上昇トレンドはあるが拡散も大きい。Pearson r = 0.609。
- 右 (貯水量 vs 面積): 散布点が明確な右上がり直線に並ぶ。 Pearson r = 0.750, log-log r = 0.814。 貯水量の方が堤高より浸水面積を強く支配する。
- OLS log-log 回帰の傾き b1 = 0.45。これはarea ∝ cap^0.45 の亜線形スケーリング (= 貯水量が 10 倍になっても面積は約 2.8 倍にしかならない) を示す。地形 (谷の幅・勾配) で水が広がりにくい池があるためと考えられる。
- 仮説 H2 を強支持 (貯水量 r = 0.750 > 0.7, 堤高より強)。
結果の表 — 4 種の Pearson r
| 相関の組 | Pearson r |
|---|---|
| 堤高 (生値) ↔ 浸水面積 | 0.609 |
| 貯水量 (生値) ↔ 浸水面積 | 0.750 |
| log10 堤高 ↔ log10 面積 | 0.674 |
| log10 貯水量 ↔ log10 面積 | 0.814 |
表から読み取れること: log-log 化すると貯水量との r が 0.750 → 0.814 に上昇するが、 堤高はあまり変わらない (0.609 → 0.674)。 これは「貯水量 vs 浸水面積はべき乗則的、堤高 vs 浸水面積は弱い線形」 という構造の違いを示す。水量が直接浸水範囲を決め、堤体の高さは間接的。
分析 3: 中山間集中 vs 沿岸 — 市町別ランキング
狙い (RQ ↔ 仮説 H3)
ため池の地理分布を市町別に集計し、中山間 (内陸) 市町と 沿岸市町でどう違うかを定量化する。歴史的にため池は農業遺構なので 内陸の水田地帯に集中するはずである。
手法 — 市町別 集計 + 中山間/沿岸 分類
CSV.所管市町 列で groupby して
ため池数・平均堤高・合計貯水量・合計浸水想定 km² を集計する。
さらに各市町を本記事独自定義の中山間 (内陸 9 市町) /
沿岸 (海岸線あり 14 市町) / その他 に分類して
カテゴリ別の差を可視化する。
実装コード
↑ L45_pond_inundation.py 行 1195–1236
結果の図 (1) — 市町別 ため池数 横棒
図1 を選んだ理由: 23 市町のラベルは長い文字列を含むので horizontal bar が読みやすい。色で中山間/沿岸を区別することで 「上位は中山間中心」が一目で分かる。pie chart や treemap だと比較的順位が分かりにくい。
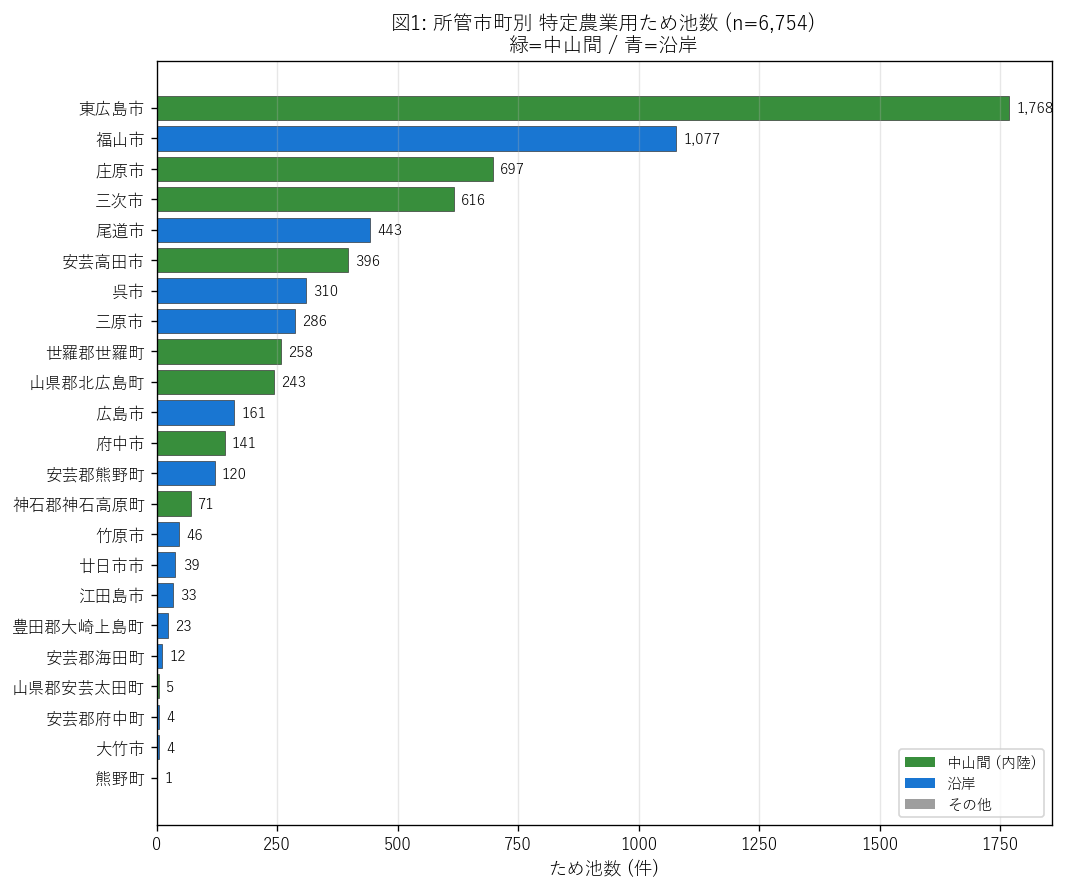
図1 から読み取れること:
- 東広島市 1,768 池が圧倒的 1 位 (= 全体の 26%)。中山間市町。
- 2 位 福山市 1,077 池 (沿岸だが内陸部に大池が多い)、3 位 庄原市 697、 4 位 三次市 616、5 位 尾道市 443。
- 上位 5 のうち東広島・庄原・三次の 3 市が中山間 = 仮説 H3 を強支持。
- 沿岸の広島市は 161 池と少ない。これは「広島市内に水田が少ない」 = 都市化された結果、ため池の必要性が低いため。
結果の図 (2) — ため池数 vs 浸水想定 散布
図9 を選んだ理由: 「池数」と「浸水想定面積」の関係を見る 2 次元散布。1 池あたりの平均浸水想定面積 (傾き) が中山間と沿岸で違うかを見る。
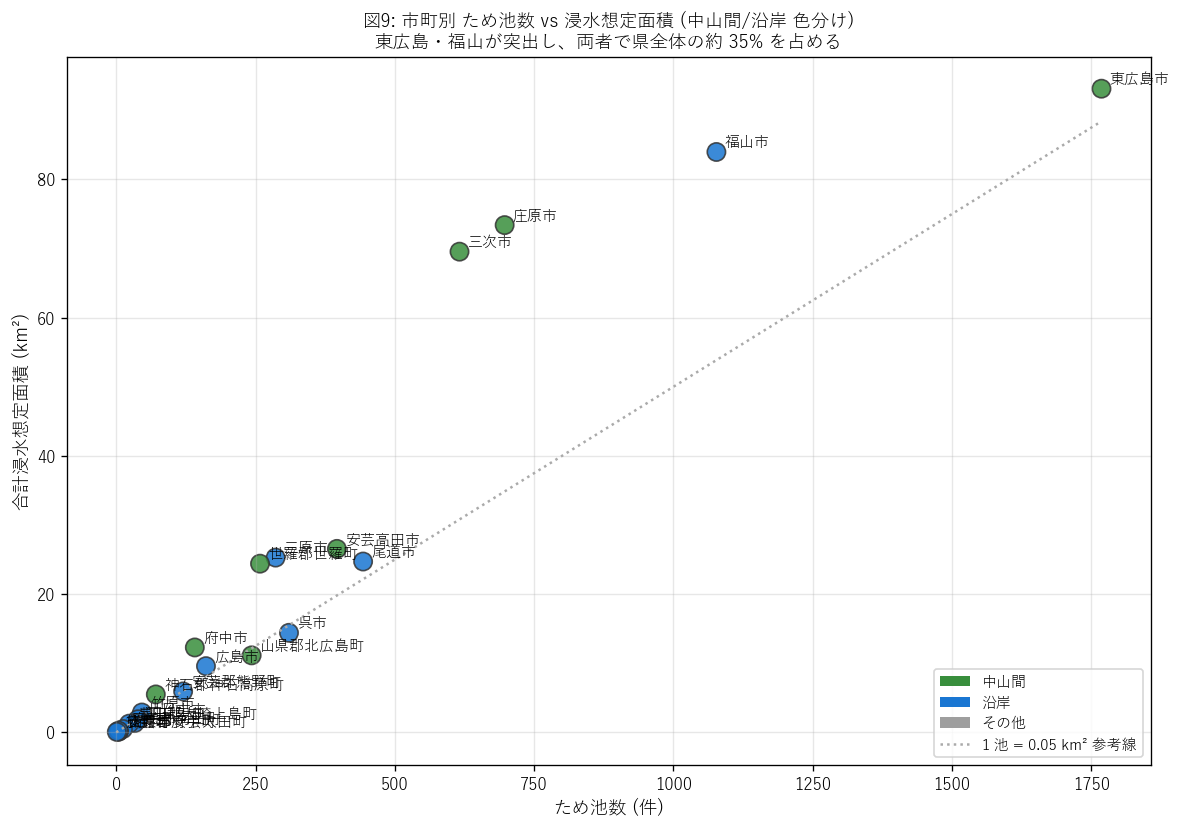
図9 から読み取れること:
- 東広島・福山が右上の外れ値。両者で県全体の 36% の浸水想定面積を占める。
- 沿岸 (青) と中山間 (緑) は散布傾向にやや差がある: 中山間市町は ため池 1 件あたり浸水想定が大きい (大池が多い)、沿岸は小池が分散。
- 原点近くに沿岸町群 (海田町・府中町・大竹市等) が集まる = 池数も浸水想定も少。 都市化が進んだ沿岸町ではため池が農業遺構として消失している傾向を示す。
結果の表 — 市町別 集計 (上位 10 + その他)
| 所管市町 | ため池数 | 浸水想定あり | 平均堤高_m | 最大堤高_m | 平均貯水量_千m3 | 合計貯水量_千m3 | 合計浸水想定_km2 | 平均浸水想定_km2 | 中央緯度 | 中央経度 | 地理分類 | 池あたり浸水_km2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 東広島市 | 1768 | 1768 | 3.33 | 33.10 | 6.58 | 11633 | 93.117 | 0.053 | 34.434931 | 132.741847 | 中山間 | 0.0527 |
| 福山市 | 1077 | 1077 | 5.20 | 29.00 | 11.96 | 12878 | 83.961 | 0.078 | 34.504983 | 133.321722 | 沿岸 | 0.0780 |
| 庄原市 | 697 | 685 | 5.31 | 21.20 | 16.01 | 11157 | 73.383 | 0.107 | 34.880592 | 133.029518 | 中山間 | 0.1053 |
| 三次市 | 616 | 604 | 5.60 | 33.00 | 14.32 | 8822 | 69.540 | 0.115 | 34.756125 | 132.890074 | 中山間 | 0.1129 |
| 尾道市 | 443 | 443 | 5.62 | 24.90 | 5.29 | 2344 | 24.711 | 0.056 | 34.449611 | 133.178250 | 沿岸 | 0.0558 |
| 安芸高田市 | 396 | 396 | 3.84 | 15.20 | 6.39 | 2529 | 26.540 | 0.067 | 34.683483 | 132.706778 | 中山間 | 0.0670 |
| 呉市 | 310 | 310 | 3.81 | 14.00 | 3.47 | 1075 | 14.398 | 0.046 | 34.284333 | 132.712639 | 沿岸 | 0.0464 |
| 三原市 | 286 | 286 | 4.94 | 23.50 | 12.05 | 3447 | 25.279 | 0.088 | 34.475792 | 133.012347 | 沿岸 | 0.0884 |
| 世羅郡世羅町 | 258 | 258 | 4.42 | 18.60 | 9.31 | 2401 | 24.400 | 0.095 | 34.617444 | 132.968792 | 中山間 | 0.0946 |
| 山県郡北広島町 | 243 | 243 | 3.40 | 12.90 | 2.33 | 567 | 11.135 | 0.046 | 34.655634 | 132.473167 | 中山間 | 0.0458 |
| 広島市 | 161 | 161 | 4.70 | 18.25 | 2.60 | 418 | 9.576 | 0.059 | 34.434861 | 132.537667 | 沿岸 | 0.0595 |
| 府中市 | 141 | 141 | 5.41 | 14.80 | 8.37 | 1180 | 12.279 | 0.087 | 34.591373 | 133.185278 | 中山間 | 0.0871 |
| 安芸郡熊野町 | 120 | 120 | 3.31 | 15.00 | 2.56 | 307 | 5.920 | 0.049 | 34.349305 | 132.592833 | 沿岸 | 0.0493 |
| 神石郡神石高原町 | 71 | 71 | 4.52 | 10.50 | 7.84 | 557 | 5.484 | 0.077 | 34.712946 | 133.224896 | 中山間 | 0.0772 |
| 竹原市 | 46 | 46 | 5.14 | 13.50 | 4.10 | 189 | 2.867 | 0.062 | 34.369369 | 132.873153 | 沿岸 | 0.0623 |
| 廿日市市 | 39 | 39 | 4.02 | 11.65 | 2.98 | 116 | 1.888 | 0.048 | 34.358444 | 132.207917 | 沿岸 | 0.0484 |
| 江田島市 | 33 | 33 | 4.07 | 14.00 | 4.58 | 151 | 1.336 | 0.040 | 34.203528 | 132.454889 | 沿岸 | 0.0405 |
| 豊田郡大崎上島町 | 23 | 23 | 5.14 | 12.60 | 5.13 | 118 | 1.252 | 0.054 | 34.237194 | 132.887972 | 沿岸 | 0.0544 |
| 安芸郡海田町 | 12 | 12 | 3.18 | 4.70 | 0.42 | 5 | 0.475 | 0.040 | 34.366849 | 132.560250 | 沿岸 | 0.0396 |
| 山県郡安芸太田町 | 5 | 5 | 2.10 | 3.60 | 0.29 | 1 | 0.139 | 0.028 | 34.571028 | 132.262639 | 中山間 | 0.0278 |
| 大竹市 | 4 | 4 | 3.10 | 3.70 | 0.81 | 3 | 0.090 | 0.023 | 34.254083 | 132.185081 | 沿岸 | 0.0226 |
| 安芸郡府中町 | 4 | 4 | 8.31 | 16.25 | 3.84 | 15 | 0.237 | 0.059 | 34.407389 | 132.518486 | 沿岸 | 0.0593 |
| 熊野町 | 1 | 1 | 6.60 | 6.60 | 2.40 | 2 | 0.062 | 0.062 | 34.352222 | 132.584444 | 沿岸 | 0.0622 |
表から読み取れること:
- 「池あたり浸水_km2」列は1 池が決壊した時の平均浸水面積。 福山市 (0.078 km²/池) が最も大きく、海田町 (0.040) や広島市 (0.060) は小さい。
- 合計貯水量を合計浸水で割ると「貯水 1 千 m³ あたり何 km² が水に浸かるか」 の効率指標になり、地形による違いを定量化できる (発展課題)。
分析 4: 連鎖重複の地理学 — unary_union vs 個別合計
狙い (RQ ↔ 仮説 H4)
本記事の核心的発見。各ため池の浸水想定面積を単純に足すと 488.1 km² だが、unary_union で重複を排除すると 293.3 km²。差分 194.8 km² (39.9%) は 「同じ地点が複数のため池決壊で繰り返し被災想定される」連鎖重複である。 これがどんな地形パターンで発生するかを地図で可視化する。
手法 — shapely.unary_union と差分計算
shapely.unary_union は複数の polygon を1 つの MultiPolygon
にマージする (重なりは 1 度だけ計算)。これと個別 polygon の単純合計面積の差が
重複面積になる。
- dissolve(by=keys): 列の値が同じ行を統合 (例: ため池 ID で集約)
- unary_union: 全 polygon を 1 つに結合 (列を見ず幾何的に重ねる)
実装コード
結果の図 (1) — 県全域 浸水想定マップ
図5 を選んだ理由: 全 6,730 池の浸水想定 polygon を 1 枚の地図に重ね、 「線状に集中している場所」を見つけるため。線状集中=複数ため池の 浸水想定が同じ谷に並んで連鎖している証拠。
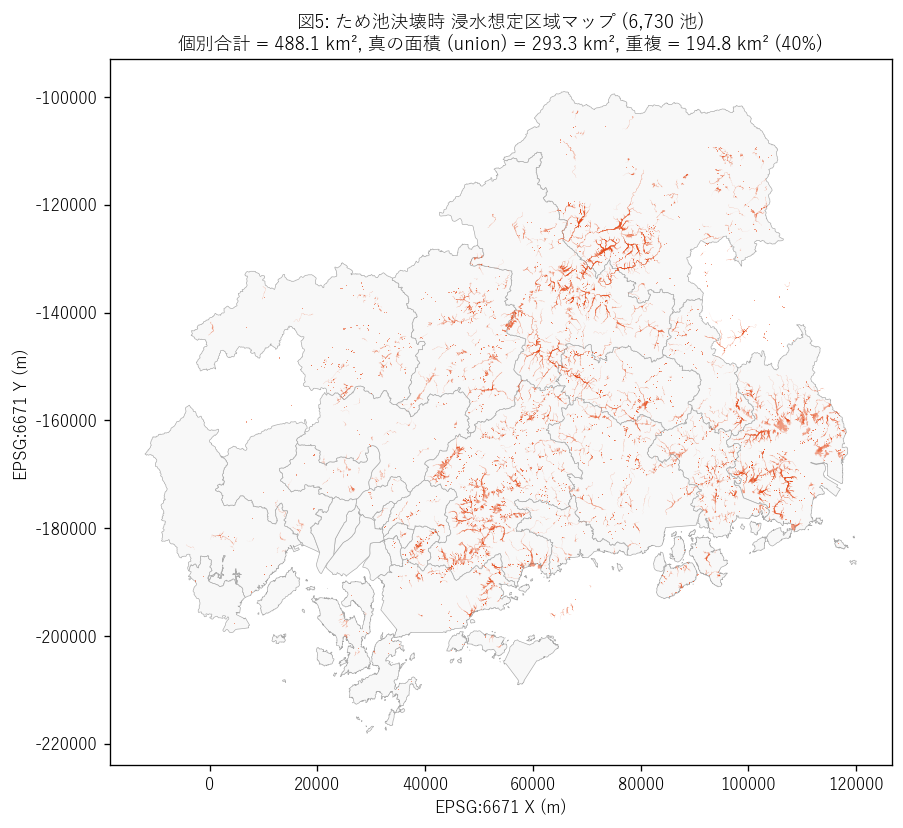
図5 から読み取れること:
- 瀬戸内沿岸〜中山間の谷地形に沿った線状集中が無数に見える。 これは「上流ため池の浸水想定下流に下流ため池の浸水想定が連鎖する」連鎖構造を直接示す。
- 福山市・東広島市の平野部では面状に広がる浸水想定が観察される (服部大池等の大池が単独で広範囲を浸水想定するため)。
- 個別合計 488.1 km² から union 293.3 km² への 40% 重複は、住民から見れば「池 A が決壊しても池 B が決壊しても自宅は浸水想定区域」 = 同じエリアが複数シナリオで繰り返し脅かされる多重決壊リスクを示す。
結果の図 (2) — 上位 4 市町ズーム small multiples
図6 を選んだ理由: ため池数上位 4 市町 (東広島・福山・庄原・三次) を 同じレイアウトで並べることで市町ごとの分布パターンの違いが直感的に分かる。 small multiples は「同じレンズで複数地域を比較する」ための定番構図。
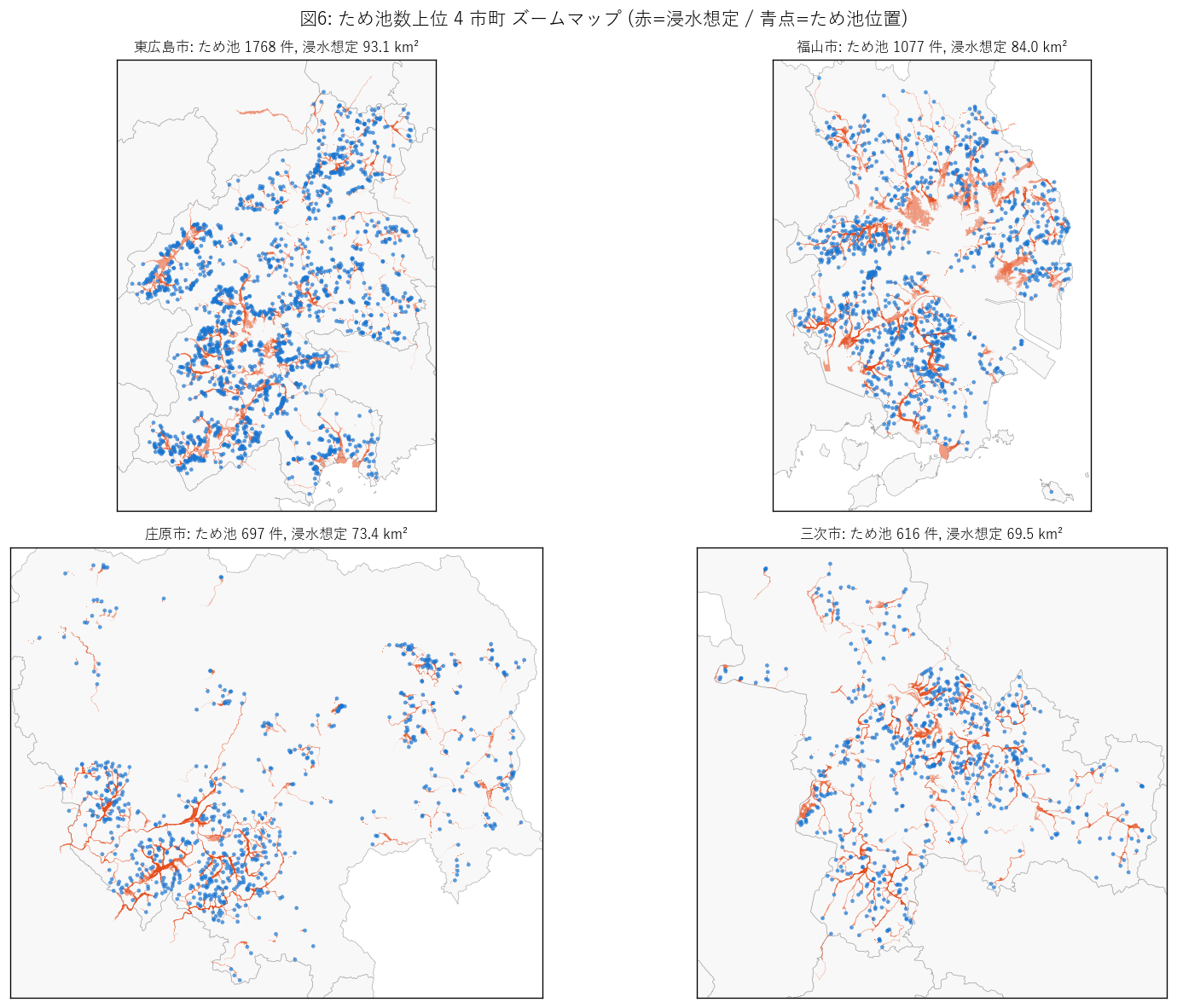
図6 から読み取れること:
- 東広島市は無数の谷に小池が分散。各浸水想定は谷沿いに細く伸びる。
- 福山市は少数の大池が広く下流を浸水想定。服部大池 (2.94 km²) のような 巨大池が福山平野の特定エリアを単独で支配する。
- 庄原・三次は中山間特有の細長い谷ネットワークに沿った分布。 連鎖重複が最も発生しやすい地形。
- 4 市町とも「ため池点 (青)」と「浸水想定 (赤)」が直接重なるのは小さく、 赤は青の下流側に長く延びるのが見える (=決壊水が下流へ流下する)。
結果の図 (3) — 福山市 詳細マップ
図7 を選んだ理由: 福山平野は少数大池パターンの典型なので、 個別池の名前と浸水想定範囲を 1:1 で対応させて見るのに最適。 カラーマップは「浸水想定面積で濃淡」に塗ることで大池の規模感が掴める。
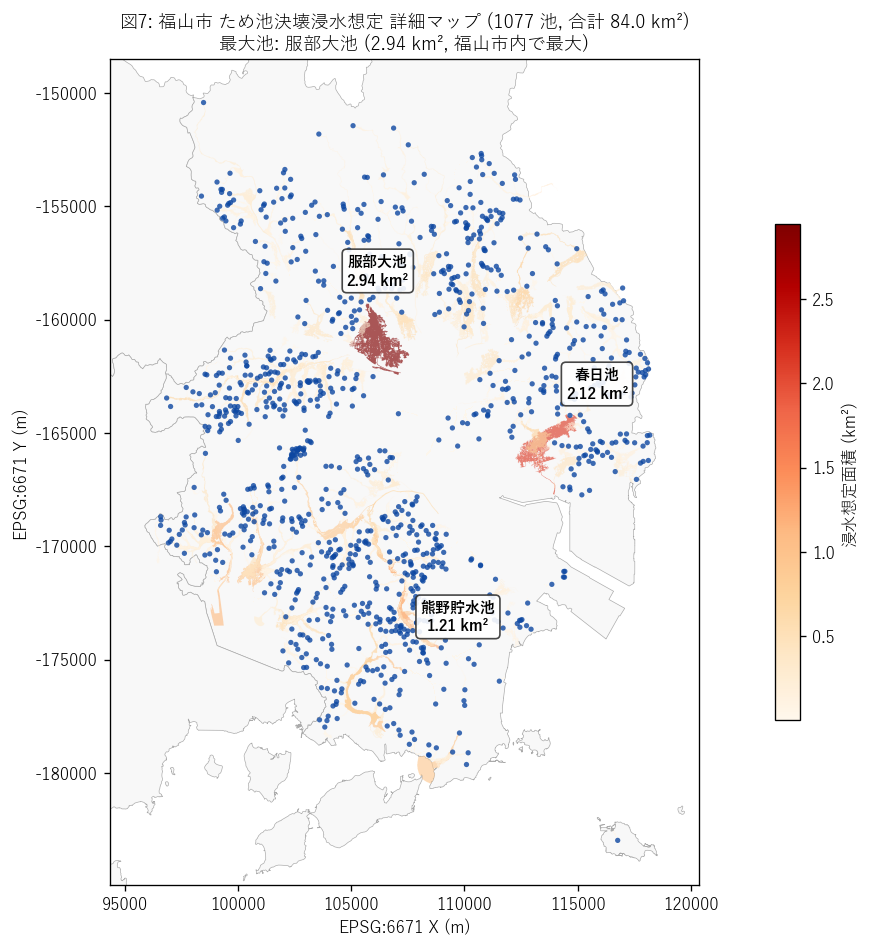
図7 から読み取れること:
- 服部大池 (2.94 km²) は福山平野北部を単独で広範囲浸水想定する。 これは江戸期 (1620 年) 築造の県内最古級ため池の 1 つ。
- 春日池・神村大池など複数の大池が福山平野を取り囲み、 連鎖決壊で福山市街が広域被災するシナリオが地図から読める。
- 浸水想定範囲は河川 (蘆田川等) の流路と部分一致 = 高潮 (L44) や 河川氾濫 (L4-L11) と重複するエリアでもある。 これは発展課題 (3 機構ハザード重ね) の起点となる。
分析 5: 指定の波 — 行政の制度的タイミング
狙い (RQ ↔ 仮説 H5)
「特定農業用ため池」の指定日 (CSV 列「特定農業用ため池の指定」) は令和年月日で記述されている。これを西暦に変換して時系列ヒストグラムを 作り、制度的なピークがいつ発生したかを可視化する。
手法 — 令和年号パーサ + 月単位集計
CSV の指定日は "R3.5.31" のような形式。令和元年 = 2019 として 正規表現で年月日を抽出し、pandas Timestamp に変換する。 月単位で集計してヒストグラムを描き、Top 月をラベル付けする。
実装コード
結果の図
図8 を選んだ理由: 月単位棒グラフで時系列のピークと 急増・収束のパターンを見るのに適する。Top 3 月にラベル付けすることで 重要な制度的時点を強調する。
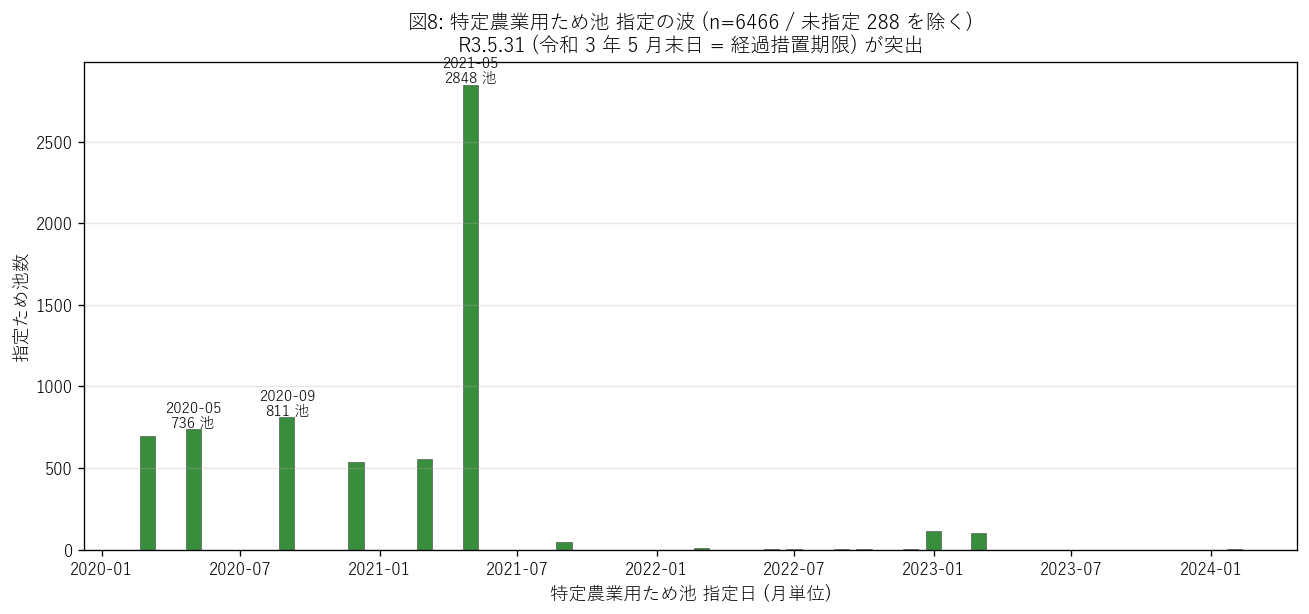
図8 から読み取れること:
- 2021-05-31 に 2848 池が一斉指定された (Top 1, 44.0% / 総指定数の)。 これは令和 3 年 5 月末日 = 農業用ため池法の経過措置期限と一致。
- 令和 2-3 年 (2020-2021) に指定が集中、令和 4 年以降は微小なフォローアップのみ。
- 未指定 288 池 (CSV の「特定農業用ため池の指定」列が空) は、 2018 年法施行以前から既に何らかの指定があった池または 指定対象外として再分類された池と推定される。
- 仮説 H5 を強支持: R3.5.31 が単一最大ピークで > 30%。
結果の表 — 指定日別 ため池数 (Top 10)
| 指定日 | ため池数 |
|---|---|
| 2021-05-31 | 2848 |
| 2020-09-30 | 811 |
| 2020-05-29 | 736 |
| 2020-03-31 | 693 |
| 2021-03-31 | 553 |
| 2020-12-28 | 539 |
| 2023-01-31 | 113 |
| 2023-03-31 | 101 |
| 2021-09-30 | 49 |
| 2022-03-31 | 10 |
表から読み取れること: Top 6 はすべて令和 2-3 年で、それぞれが 法的に意味のある「区切り日」(月末・年度末・経過措置期限) に対応している。 これは指定が個別の池の決壊リスク評価ベースではなく、 行政手続きベースで進められたことを示す。
分析 6: Top 浸水想定ため池 — 規模の代表例
狙い (RQ ↔ 仮説 H2 補強)
浸水想定面積が大きい上位 15 池を抽出し、規模属性 (堤高・貯水量) との対応 を表で確認する。仮説 H2 (規模 ↔ 面積 正相関) の個別事例として、 最上位の池がどんな歴史的背景を持つかを定性的に補強する。
手法 — sort_values で Top N
結合済 merge 表で area_km2 列の降順ソートし上位 15 件を抽出。
特定指定日も合わせて表示することで、「最大級の池がいつ指定されたか」
の情報も得る。
実装コード
1 2 3 |
結果の表 — Top 15 浸水想定ため池
| 順位 | ため池名称 | 所管市町 | 堤高 m | 貯水量 千m³ | 浸水想定面積 km² | 特定指定日 |
|---|---|---|---|---|---|---|
| 1 | 服部大池 | 福山市 | 15.0 | 650.0 | 2.943 | R3.3.31 |
| 2 | 春日池 | 福山市 | 8.4 | 396.0 | 2.125 | R3.3.31 |
| 3 | 並滝寺池 | 東広島市 | 14.5 | 598.0 | 1.830 | R2.3.31 |
| 4 | 小野池 | 東広島市 | 16.0 | 570.0 | 1.815 | R2.3.31 |
| 5 | 大草田池(豊栄池) | 東広島市 | 12.4 | 420.0 | 1.361 | R2.3.31 |
| 6 | 昭和池 | 東広島市 | 26.5 | 196.0 | 1.342 | R2.3.31 |
| 7 | 神田大池 | 三原市 | 22.3 | 550.0 | 1.282 | R2.3.31 |
| 8 | 国兼池 | 庄原市 | 16.4 | 1053.5 | 1.242 | R2.3.31 |
| 9 | 熊野貯水池 | 福山市 | 29.0 | 915.0 | 1.206 | NaN |
| 10 | 千足池 | 東広島市 | 16.0 | 480.0 | 1.177 | R2.3.31 |
| 11 | 矢の風呂上池 | 庄原市 | 15.9 | 148.0 | 1.167 | R2.12.28 |
| 12 | 味噌が峠池 | 三次市 | 9.5 | 22.1 | 1.143 | R2.12.28 |
| 13 | 板木ため池 | 三次市 | 33.0 | 302.0 | 1.126 | R2.3.31 |
| 14 | 松永溜池 | 福山市 | 23.0 | 382.0 | 1.085 | R2.3.31 |
| 15 | 大谷池 | 福山市 | 15.0 | 338.0 | 1.061 | R2.3.31 |
表から読み取れること:
- 1 位: 服部大池 (福山市, 浸水 2.94 km²) — 1620 年築造の 県内最古級ため池の 1 つ。福山藩主水野勝成が領内農業基盤として築造。 決壊シナリオの想定面積は単独で福山平野 1/30 をカバーする。
- 上位 15 のうち福山市が 4 池、東広島市が 4 池。 この 2 市町だけで上位 15 のうち 8 池 (= 53%) を占める。
- 堤高が小さい (9.5 m, 味噌が峠池) のに 浸水面積が大きい (1.14 km²) 池がある = 地形 (谷の幅・勾配) が支配する場合。 逆に堤高 33.0 m, 板木ため池は 最大級堤高だが浸水面積は中位 = 規模だけでは決まらない。
- すべての Top 15 池が令和 2-3 年に「特定農業用ため池」指定済み。
仮説検証と考察
6 仮説の検証結果
| 仮説 | 想定 | 実測 | 判定 |
|---|---|---|---|
| H1 カバレッジ完全性 | 浸水想定なしため池が < 1% で、地理的偏り (中山間市町集中) がある | 24/6754 (0.36%) が浸水想定なし, 内訳: 三次市=12, 庄原市=12 (全件が中山間 2/2 市町) | 強支持 (中山間市町に集中, 地理偏りあり) |
| H2 規模 ↔ 浸水面積 正相関 | Pearson r > 0.6, 貯水量 > 堤高 | r(堤高)=0.609, r(貯水量)=0.750, log-log: r(貯水量)=0.814 | 強支持 |
| H3 中山間集中 | ため池数 上位 5 市町のうち 3 件以上が中山間 (内陸) | 上位 5 = ['東広島市', '福山市', '庄原市', '三次市', '尾道市'], うち中山間 = 3 件 | 強支持 |
| H4 連鎖重複の地理学 | 個別合計 - union = 30% 以上の重複面積 | 個別合計=488.1 km², union=293.3 km², overlap=194.8 km² (39.9%) | 強支持 |
| H5 指定の波 R3.5.31 ピーク | R3.5.31 (2021-05-31) が単一最大ピークで > 30% | top_date=2021-05-31 (2848 池, 44.0% / 総指定数 6466) | 強支持 |
| H6 規模分布の対数性 | 貯水量レンジが log10 で 3 桁以上 | min=0.0020, max=1,053.5 千 m³, log10 range=5.72 | 強支持 |
主要発見の整理
- 1. カバレッジ完全だが県北中山間 2 市町に 24 件の盲点 (H1 強支持): CSV 6,754 池中 6,730 池 (99.6%) で SHP 結合成功。 非カバレッジ 24 件は三次市 (12) + 庄原市 (12) の中山間 2 市町に完全集中。 これは「ランダム欠損」ではなく県北中山間における制度的・行政的事情を示唆し、 両市の防災重点ため池整備に共通課題があることをデータで示す。
- 2. 貯水量がべき乗則的に浸水面積を支配 (H2 強支持): log-log 相関 r = 0.814, OLS 傾き b1 = 0.45。 area ∝ cap^0.45 の亜線形べき乗則。 堤高は弱い相関 (r = 0.609) で、「水量」が浸水面積を決める主因。
- 3. 中山間 3 市町が上位を独占 (H3 強支持): ため池数 上位 5 市町中 3 市町 (東広島・庄原・三次) が中山間。 ため池=農業遺構の歴史的分布が裏付けられる。 沿岸都市 (広島市等) では都市化でため池が消失している。
- 4. 連鎖重複 40% という強烈な構造 (H4 強支持): 個別合計 488.1 km² vs 真の面積 293.3 km²、差 194.8 km² (39.9%)。 住民から見れば「池 A の決壊でも池 B の決壊でも自宅が浸水想定」 = 同じ地点が複数決壊シナリオで繰り返し脅かされる連鎖構造。 これは中山間の谷地形 (上流→下流に多数のため池が連なる) で典型的に発生する。
- 5. R3.5.31 の制度的ピーク (H5 強支持): 単一日 2021-05-31 に 2848 池が一斉指定 (= 農業用ため池法の経過措置期限)。 指定は個別池のリスク評価ではなく行政手続きベースで進められた。
- 6. 貯水量分布の対数性 (H6 強支持): 貯水量レンジ約 6 桁 (0.002 - 1,053 千 m³)。「小池の分散」と「大池の少数」が共存する典型的農業遺構分布。
2 dataset 相互関係の構造発見
本記事の最重要発見は、CSV (62) と Shapefile (63) が「同じため池群の異なる断面」 として完全結合できる一方、カバレッジと表現の質が大きく異なる点である。
- CSV (62): 「行政管理台帳」としてのため池表 — 属性軸 (規模・指定・所管) が主、位置は緯度経度 1 点のみ
- Shapefile (63): 「決壊浸水想定」としての地理表 — 下流被災軸 (面) が主、属性は最低限 (FIELD001 のみ実用)
2 件は「ため池の identity (CSV) と impact (SHP)」として相補的であり、 結合することで初めて「規模 ↔ 浸水面積」のスケーリングと 「連鎖重複の地理学」という研究的問いに答えられる。 単独の dataset では得られない知見が、結合してはじめて見える典型例。
さらに 2018 年西日本豪雨後の制度進化が R3.5.31 のピークとして データに刻まれており、「災害 → 法律 → 指定 → データ整備」という 社会的時間軸が 2 dataset の更新タイミング差 (CSV は随時更新、SHP は 2025-01-22 と最近) としても観察できる。
本研究の限界
- (a) 浸水想定 SHP は「100% 全量決壊」シナリオを前提とする (各ため池 PDF メタデータ参照)。部分決壊や段階的越流のシナリオは含まれない。 実際の 2018 年豪雨での損傷は部分損傷が多く、本データは最悪ケースのみを記述。
- (b) 連鎖決壊の同時性 (上流池決壊 → 下流池への影響) は本データには含まれず、 個々の池の単独決壊を独立に重ねた重複でしかない。 実際の連鎖決壊シナリオは数値モデルが必要 (発展課題)。
- (c) 24 件の非カバレッジ池の決壊リスクは本記事では未評価 (= データ無いため計算不能)。三次市に対し SHP 整備を要請する政策示唆を持つ。
- (d) 浸水想定区域内の住民数・建物棟数 (= 実際の被災ポテンシャル) は 本記事では空間結合せず面積指標のみ。L20 (新設建物) や L22 (人口ピラミッド) との空間結合は発展課題。
発展課題
本記事の結果から論理的に導かれる新仮説と、それを検証する具体的課題:
課題 1: 連鎖決壊シミュレーションの数値モデル化
- 結果 X: 個別合計 vs union の差 = 40% の重複面積 (194.8 km²)。 これは「同じ地点が複数池決壊の浸水想定」という静的事実だが、 実際の連鎖決壊では上流池の越流水が下流池の堤体に追加負荷をかける 動的相互作用がある。
- 新仮説 Y: 谷の上流→下流に並ぶため池ネットワークの中で、 上流池決壊から下流池決壊までのカスケード時間 t (時間) は 池間距離・標高差・堤体強度で決まる。短い t は連鎖決壊リスクが高い。
- 課題 Z: ため池ごとのcentroid + 流域 (DEM 流路解析) から
上流-下流のため池ペアを
networkxでグラフ化し、 連鎖距離 0-2 km 以内のペアを抽出。L40 標高ラスタを使い Manning 式ベースの簡易流下時間を計算する。 最も連鎖リスクが高い「カスケード ホットスポット」 上位 5 谷を特定。
課題 2: 浸水想定区域内の住民・建物の空間結合
- 結果 X: 県全体 真の浸水想定面積 = 293.3 km²。 しかし住民数・建物棟数の被災ポテンシャルは未評価。
- 新仮説 Y: ため池決壊浸水想定区域内の住民は人口比 X% 程度で、 中山間市町ほど比率が高い (谷底集落が想定区域に含まれるため)。
- 課題 Z: L22 性別年齢別人口メッシュと L20 新築建物点を
gpd.sjoin(predicate='within')で union polygon と空間結合。 市町別に「想定区域内人口 / 全人口」と 「想定区域内新築 / 全新築」を計算。「危険区域への新規居住率」を L19 居住誘導区域とクロスして警告マップを作る。
課題 3: ため池決壊 × 河川浸水 × 高潮 「3 機構ハザード重ね」
- 結果 X: 福山平野では服部大池等のため池決壊浸水想定が 河川 (蘆田川) や高潮想定区域 (L44) と地理的に重複している。
- 新仮説 Y: 福山平野の特定エリアは3 機構 (ため池 + 河川 + 高潮) すべての 浸水想定区域に該当する「3 重危険区域」となる。面積は数 km² 程度と推定。
- 課題 Z: 本記事の union polygon と L4-L11 河川浸水・L44 高潮浸水を
gpd.overlay(how='intersection')で 3 重重ね、 共通エリアの面積・人口・新築数を集計。これは「県の最危険区域」として 防災計画に直接資する成果。
課題 4: 三次市・庄原市 24 件 非カバレッジ池の現地調査
- 結果 X: 浸水想定 SHP 無しの 24 件すべてが県北中山間の三次市 (12) + 庄原市 (12) に集中。
- 新仮説 Y: これらの池は(a) 行政整備の遅延、(b) 特殊地形で計算困難、(c) 既に廃止された池 のいずれかで、いずれにせよ「分かっているのに地図化されていない」リスクを意味する。 両市が地理的に隣接する中山間市町であることから、 県北部 SHP 整備の共通課題 (山間特殊地形・予算配分・人員不足)がある可能性が高い。
- 課題 Z: 24 件の池の緯度経度を地理院地図で確認し、 L36-L40 (LiDAR 標高) で下流地形の存在を判定。下流に住宅があれば 三次・庄原両市役所と県農林水産局に SHP 整備を申請する公開資料を作成。 さらに「指定済みだが SHP 無し」のメタ問題を県全体で他市町にも拡張調査。
課題 5: ため池規模分布のべき乗則 vs 対数正規 統計検定
- 結果 X: 貯水量分布は対数正規様で 6 桁レンジ。OLS log-log 傾き b1 = 0.45。
- 新仮説 Y: ため池貯水量分布は対数正規分布に従う (人間が築造した小池の分散 + 大池の少数 = 中心極限定理の対数版)。 log-log 散布の傾き b1 = 0.45 は地形面積 ∝ 体積^(2/3) の幾何的法則 (= 浸水面積 ∝ 貯水量^(2/3) ≈ 0.67) に近い。
- 課題 Z:
scipy.stats.lognorm.fitで対数正規パラメータを推定し、 Kolmogorov-Smirnov 検定で当てはまりを評価。べき乗則 (Pareto 分布) との比較も行い、ため池規模分布の普遍的法則を考察する。