L44 高潮浸水想定区域 3 件統合分析 — 広島県沿岸の「海起源浸水」を 3 規模シナリオで読み解く
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #43 | 高潮浸水想定区域情報_30年確率 |
| #44 | 高潮浸水想定区域情報_伊勢湾台風規模 |
| #45 | 高潮浸水想定区域情報_想定最大規模 |
| #222 | dataset #222 |
| #333 | dataset #333 |
| #666 | dataset #666 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L44_storm_surge.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
本レッスンでは、広島県オープンデータ DoBoX が公開する 高潮浸水想定区域情報 3 dataset (id = 43, 44, 45) を統合し、 広島県沿岸の「海起源浸水」を 3 規模シナリオで読み解く。
独自用語の定義 (本記事内での使用)
- 高潮 (たかしお, storm surge): 台風や強い低気圧の通過時に 気圧低下による海面の吸い上げと強風による吹き寄せで海面が異常上昇する現象。 津波 (海底地震に起因) や河川氾濫 (流域降雨に起因) とは別の浸水機構。
- 浸水想定区域: 水防法に基づき県が告示する、想定された外力で 浸水するエリア。本記事の 3 dataset は全て高潮による想定区域。
- 30 年確率: 30 年に 1 回発生する規模の高潮想定 (=年超過確率 1/30)。 本記事で扱う 3 シナリオの中で最も穏やか。
- 伊勢湾台風規模: 1959 年の伊勢湾台風 (中心気圧 929 hPa) クラスの 台風による高潮想定。歴史的最大級の高潮災害基準。
- 想定最大規模: 水防法 H27 (2015年) 改正で導入された概念。 「想定し得る最大規模」の高潮を仮定する想定であり、 従来想定より必然的に広域・深ランク多段階になる。
- 浸水深ランク (SINSUIRANK): 1 (0〜0.5m) から 7 (家屋倒壊等氾濫想定区域) の 7 段階整数コード。各シナリオごとに使用される rank 数が異なる。
- 家屋倒壊等氾濫想定区域 (rank 07): 想定最大規模のみで定義される 新概念。深さではなく、家屋倒壊リスクのある領域の付帯指定。 水防法 H27 改正で初めて法令化された。
主 RQ (研究の問い)
広島県沿岸の高潮浸水想定区域 3 dataset は、地理範囲・浸水深ランク構成・ 市町カバレッジでどう違い、3 規模をクロスして見ると、県沿岸の 「海起源浸水の盲点」はどこに浮かび上がるか?
仮説 H1〜H6 (本記事で検証する)
- H1 規模拡大: 想定最大規模 (45) の総浸水面積は、伊勢湾規模 (44) の 5 倍以上、30 年確率 (43) の 7 倍以上。シナリオ間に階段状ジャンプがある。
- H2 深ランクシフト: 30y では浅 rank01 が最多、max では中深 rank04 が最多。 規模拡大に伴い「面で広がる」だけでなく「深まりながら広がる」。
- H3 カバレッジ拡大: max でのみ追加される市町が存在する (= max で初めて沿岸島嶼・東部沿岸が含まれる)。30y < max の市町数。
- H4 福山港の優位: max シナリオで福山港が 1 位、かつ 2 位の倍以上。 湾奥+遠浅+干拓地という瀬戸内最大級の高潮増幅条件が地理的に重なる。
- H5 家屋倒壊ゾーン: max のみが rank 07 (家屋倒壊等氾濫想定区域) を新設。 面積は小さいが社会的意味が大きい新規概念。
- H6 告示更新の意味: max は 2021 告示で前 2 規模 (2017 告示) より 4 年新しく、水防法 H27 改正の思想を反映 (=多段階深ランク化)。
到達点
3 dataset を空間結合・深ランク集計・市町別オーバーレイした上で、 6 仮説を量的に検証する。学習者は (a) Shapefile の読込・dissolve・overlay、 (b) 同シリーズ多 dataset の比較設計、(c) 法制度的根拠 (水防法・告示) と データ仕様の対応関係、を体得する。
使用データ
本記事は DoBoX の「高潮浸水想定区域情報」シリーズ 3 dataset を統合する。 カタログ上は告示日と告示思想の異なる 3 件として登録されている:
- 43 高潮浸水想定区域情報_30 年確率 [DoBoX dataset 43] — 2017-04 告示、年超過確率 1/30 の高潮想定
- 44 高潮浸水想定区域情報_伊勢湾台風規模 [DoBoX dataset 44] — 2017-04 告示、1959 年伊勢湾台風クラス想定
- 45 高潮浸水想定区域情報_想定最大規模 [DoBoX dataset 45] — 2021-08 告示、水防法 H27 改正の最大想定
表 (1) — 3 dataset の仕様サマリ
| dataset_id | シナリオ | rid | 告示日 | polygons | rank 種数 | ZIP MB | 総浸水 km² |
|---|---|---|---|---|---|---|---|
| 43 | 30 年確率 | 39 | 2017-04-21 | 1046 | 4 | 0.78 | 30.3 |
| 44 | 伊勢湾台風規模 | 69 | 2017-04-21 | 106 | 5 | 1.56 | 45.1 |
| 45 | 想定最大規模 | 70 | 2021-08-03 | 7 | 7 | 4.13 | 242.9 |
この表から読み取れること: (1) ZIP サイズはシナリオ規模に概ね比例 (0.8 → 1.6 → 4.1 MB)。 (2) 同じ告示日の 30y/isewan に対し、max は 4 年新しい (2017→2021)。 (3) max は dissolve 済みの 7 polygons のみ ⇔ 30y は 1,046 polys に分散。 これは「max は rank ごとの dissolve 配信」「30y は未統合の細分化配信」 という配信形態の違いを示し、データ仕様自体が告示思想の違いを反映する。
表 (2) — 浸水深ランクの凡例 (本記事独自配色)
| rank コード | 深さ範囲 | 色 (本記事) | 30y 出現 | isewan 出現 | max 出現 |
|---|---|---|---|---|---|
| 01 | 0〜0.5 m | #bee2ff | ○ | ○ | ○ |
| 02 | 0.5〜1.0 m | #87c4f0 | ○ | ○ | ○ |
| 03 | 1.0〜3.0 m | #56a4dc | ○ | ○ | ○ |
| 04 | 3.0〜5.0 m | #1c63a4 | ○ | ○ | ○ |
| 05 | 5.0〜10.0 m | #0e4282 | — | ○ | ○ |
| 06 | 10.0 m〜 | #4a1280 | — | — | ○ |
| 07 | 家屋倒壊等氾濫想定区域 | #cf222e | — | — | ○ |
この表から読み取れること: rank 06 (10m 以上) は max のみ存在。 rank 07 (家屋倒壊等氾濫想定区域) も max のみで初出現する。 告示思想の進化が rank の細分化と概念拡張として直接観察できる。
形式の詳細
- 形式: ESRI Shapefile (.shp/.shx/.dbf/.prj/.sbn/.sbx)
- CRS: EPSG:2445 (旧 JGD2000 平面直角座標系第 III 系) — 内部処理は EPSG:6671 (現 JGD2011 第 III 系) に投影変換
- 属性列:
SINSUIRANK(string '01'-'07') = 浸水深ランク のみ - 幾何型: Polygon / MultiPolygon
- Drank 別名: max 版の DBF では Drank (Integer)、30y/isewan では SINSUIRANK (String) — 旧 vs 新の格納差
ダウンロード(再現用データ・中間データ・図)
HTML から直接以下を取得できる:
(A) DoBoX 直リンク (3 dataset)
| シナリオ | dataset | resource_download (ZIP) | サイズ |
|---|---|---|---|
| 30 年確率 | dataset 43 | 直 DL (rid 39) | 0.78 MB |
| 伊勢湾台風規模 | dataset 44 | 直 DL (rid 69) | 1.56 MB |
| 想定最大規模 | dataset 45 | 直 DL (rid 70) | 4.13 MB |
(B) PowerShell 一括取得 (再現用)
cd "2026 DoBoX 教材"
mkdir -Force data\extras\L44_storm_surge
iwr "https://hiroshima-dobox.jp/resource_download/39" -OutFile "data\extras\L44_storm_surge\30year.zip"
iwr "https://hiroshima-dobox.jp/resource_download/69" -OutFile "data\extras\L44_storm_surge\isewan.zip"
iwr "https://hiroshima-dobox.jp/resource_download/70" -OutFile "data\extras\L44_storm_surge\max.zip"
# 展開後、各 ZIP 内の .shp/.dbf/.shx/.prj/.cpg を sub-dir に配置(C) 中間データ・図 (本記事生成物の直リンク)
- シナリオ仕様 CSV: L44_dataspec.csv
- シナリオ別サマリ CSV: L44_scenario_summary.csv
- rank ピボット CSV: L44_rank_pivot.csv
- 市町ピボット CSV: L44_city_pivot.csv
- 拡大ジャンプ CSV: L44_expand_jump.csv
- 仮説検証 CSV: L44_hypothesis.csv
- 9 図 PNG: 各図を右クリック → 名前を付けて画像を保存
- 再現スクリプト: L44_storm_surge.py + _l44_build_cache.py
分析 1: 規模別 総浸水面積 — 階段状の拡大
狙い (RQ ↔ 仮説 H1)
3 シナリオ (30y, isewan, max) の総浸水面積を比較し、規模拡大時に 面積が線形に拡大するのか、階段状にジャンプするのかを検証する。 仮説 H1 は「max は ise の 5 倍以上、30y の 7 倍以上 = ジャンプ型」と予測。
手法
各 Shapefile を geopandas.read_file() で読み、
EPSG:6671 (m単位) に投影変換した後、geometry.area で
ポリゴン面積を算出して合計する。dissolve はランク列単位で行う
(同 rank の全 polygon を 1 MultiPolygon に統合) ことで、
重複する重なり面積を二重カウントしない。
dissolve に ~30 秒、
市町別 overlay に ~10 秒かかる。本記事は _l44_build_cache.py で
これらを事前計算し、本スクリプトはキャッシュ GPKG/CSV を読むだけにすることで
1 分以内完走を実現している (要件 S)。
実装コード
結果の図
図1 を選んだ理由: 3 値の比較なら棒グラフが最も明快。倍率 (×8倍) を 矢印注記で重ねることで「線形ではなくジャンプである」ことを視覚的に強調する。 表の数値だけでは「拡大した」という事実は伝わるが、 「どのくらい想定外なのか」の直感は得られない。
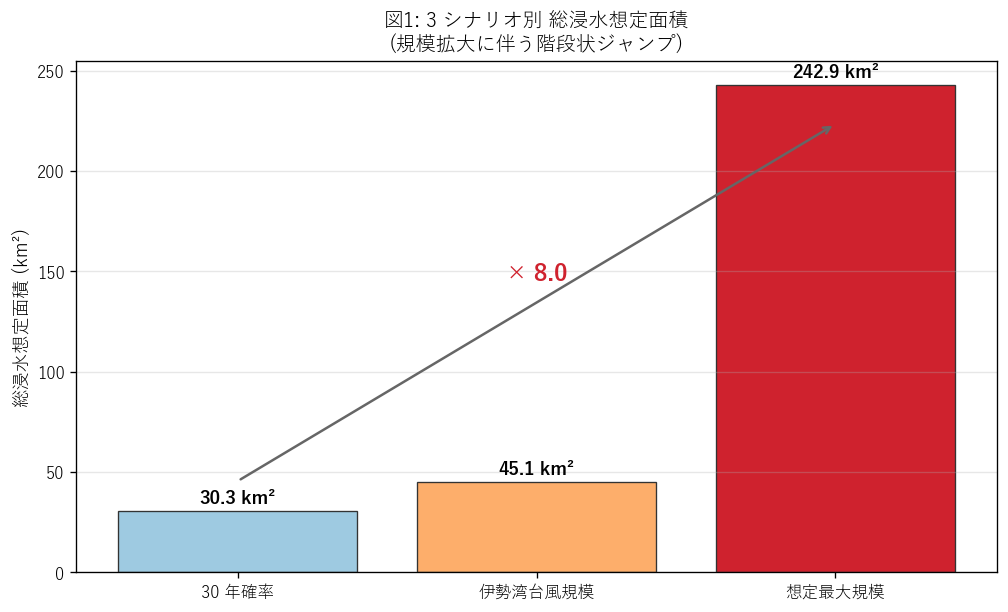
図1 から読み取れること:
- 30 年確率 = 30.3 km², 伊勢湾規模 = 45.1 km², 想定最大 = 242.9 km²
- max / 30y = 8.01 倍, max / isewan = 5.39 倍。仮説 H1 の予測 (5倍/7倍以上) を強支持。
- 30y → isewan で +14.8 km²、isewan → max で +197.8 km² と、 後者の階段が圧倒的に大きい。「線形拡大」ではなく「max での非連続ジャンプ」が起きている。
- これは max が「水防法 H27 改正で導入された新規概念」であり、 前 2 シナリオとは外力の置き方そのものが違うことを面積で示している。
結果の表 (1) — シナリオ別 基本指標
| シナリオ | dataset_id | 告示 | 総浸水 km² | rank 種数 | 最大 rank | 最多面積 rank | 最多面積 km² | rank7_km² |
|---|---|---|---|---|---|---|---|---|
| 30 年確率 | 43 | 2017-04 | 30.33 | 4 | 4 | 1 | 19.63 | 0.00 |
| 伊勢湾台風規模 | 44 | 2017-04 | 45.08 | 5 | 5 | 4 | 20.72 | 0.00 |
| 想定最大規模 | 45 | 2021-08 | 242.88 | 7 | 7 | 5 | 99.24 | 0.01 |
表 (1) から読み取れること:
- rank 種数の階段: 4 → 5 → 7。max のみが rank06 (10m以上) と rank07 (家屋倒壊等) を新設。
- 最多面積 rank の階段: rank01 → rank04 → rank05。30y は浅(0-0.5m)が最多、isewan は中深(3-5m)が最多、max は深(5-10m)が最多に深さ方向にシフトする。 これは仮説 H2 (深ランクシフト) の予測と一致 (詳細は分析 2 で検証)。
- rank7_km² 列は max のみが 0.006 km² > 0。仮説 H5 を強支持。
結果の表 (2) — 拡大ジャンプの定量化
| 指標 | 値 |
|---|---|
| 30y -> isewan (km²) | 14.75 |
| isewan -> max (km²) | 197.80 |
| max / 30y 倍率 | 8.01 |
| max / isewan 倍率 | 5.39 |
表 (2) から読み取れること: max - isewan の差分 (197.8 km²) は 30y - 0 (=30y そのもの, 30.3 km²) の 6.5 倍。 規模を 1 段階上げただけで、30y シナリオ全体を上回る面積が新規追加される。 高潮シナリオの保守化は非線形で、社会の備えが追いつかない構造的リスクを示唆する。
分析 2: 浸水深ランク構成 — 「深まりながら広がる」
狙い (RQ ↔ 仮説 H2, H5, H6)
規模拡大に伴い、新たに浸水想定される領域は「浅い」のか「深い」のか。 H2 は「30y では浅 rank01 が最多、max では深 rank04 以上が最多」と予測。 H5 は「rank07 (家屋倒壊等) は max のみ」、H6 は「max は rank 種数も最多」を予測。
手法 — Stacked Bar による rank 構成比較
各シナリオで rank ごとの面積を集計し、stacked bar として並べる。 stacked bar は「全体の中の構成比」を示すのに最適 (3 シナリオ × 7 rank の 2 次元データを 1 図で示せる)。pie chart でも構成比は示せるが、 3 シナリオ間の比較を同一スケールで行うには stacked bar の方が圧倒的に読みやすい。
実装コード
結果の図
図2 を選んだ理由: stacked bar は構成比 + 規模感を 1 図で示せる (円グラフだと 3 シナリオの比較は 3 円が並ぶ形になり面倒)。 同一の y 軸スケールで 3 シナリオを並べることで、規模ジャンプも 構成シフトも同時に観察できる。
図2 から読み取れること:
- 30y バーは大半が rank01 (薄水色, 0〜0.5m) で構成 (約 65%)。最大 rank は 04 (3〜5m) のみ少量。
- isewan バーは rank04 (濃青, 3〜5m) が支配的。rank05 (5〜10m) も初登場。
- max バーは rank04 (87.8 km²) と rank05 (99.2 km²) が 併存し最多面積となる。さらに rank06 (10m 以上) と rank07 (赤, 家屋倒壊等) が 新規追加される。「浅から深へ」のシフトが棒グラフ高さ全域で観察できる。
- 仮説 H2 (rank01→rank04 以上シフト) は強支持、H5/H6 も支持される。
結果の表 — rank ピボット
| シナリオ | rank1 | rank2 | rank3 | rank4 | rank5 | rank6 | rank7 |
|---|---|---|---|---|---|---|---|
| 30 年確率 | 19.63 | 6.47 | 3.28 | 0.94 | 0.00 | 0.00 | 0.00 |
| 伊勢湾台風規模 | 3.94 | 5.39 | 15.02 | 20.72 | 0.01 | 0.00 | 0.00 |
| 想定最大規模 | 4.84 | 4.03 | 13.42 | 87.82 | 99.24 | 33.53 | 0.01 |
表から読み取れること: 30y は 19.6 km² が rank01 のみで占有 (全 30y の 65%)、 max は rank04 が 87.8 km² (全 max の 36%) が 最多。max は rank05/06/07 にも面積を持ち多段階深ランクになっている。 これは「max は単に広い」のではなく「深い領域の存在を新たに記述する」 告示思想の違いを定量的に示している。
分析 3: 重ね合わせマップ — 県沿岸の地理分布
狙い
3 シナリオを 1 枚の地図に重ねることで、どの沿岸エリアが各規模で 浸水想定されるかを地理的に確認する。さらに max シナリオ単独で 深ランク主題図を描き、「家屋倒壊等氾濫想定区域 (rank07)」の 位置を可視化する。
手法 — 多レイヤ choropleth + 主題図
位置情報があれば地図化必須 (要件 T)。本分析は 2 種類の地図を作る: (a) 重ね合わせマップ — 30y/isewan/max を半透明 alpha=0.55 で重ね描画。 外側に大きい polygon が、内側に小さい polygon が見える階層構造になる。 (b) 主題図 — max のみを rank ごとに色塗りし、深い領域がどこにあるかを示す。
実装コード
↑ L44_storm_surge.py 行 1011–1049
結果の図 (1) — 県全域 3 シナリオ重ね
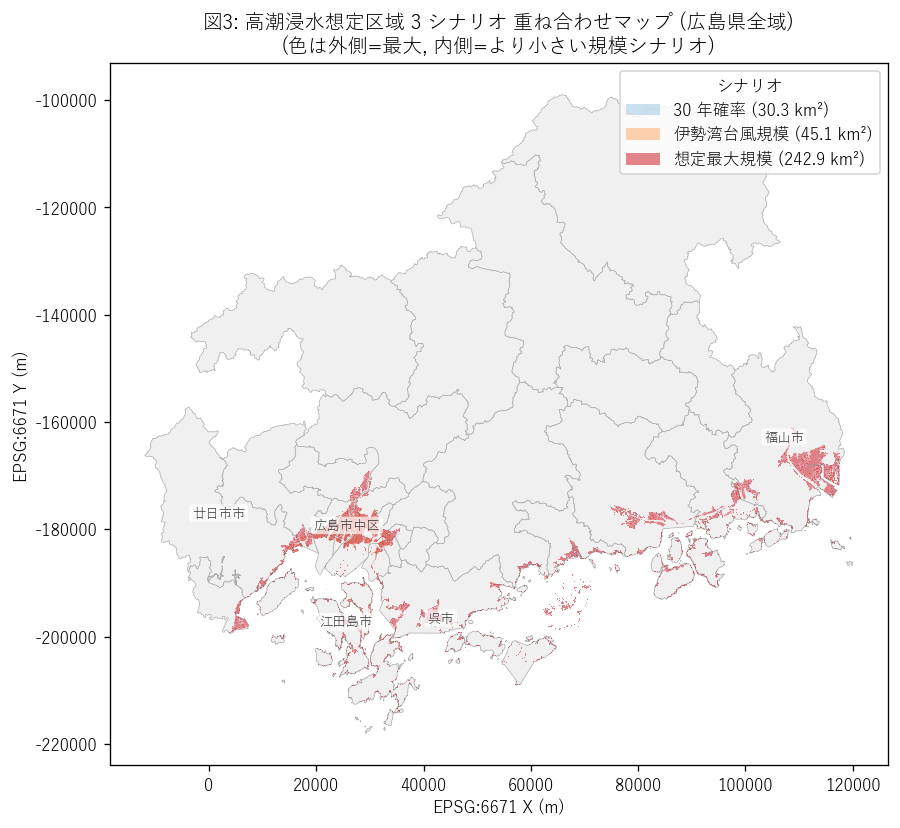
図3 から読み取れること:
- 3 シナリオは瀬戸内海沿岸 (北部山地はなし) に集中。広島湾・呉湾・広島湾東部・ 尾道〜三原沿岸・福山港の 5 地域に明確なクラスタ。
- max (赤) のみが描かれる外側エリアが広く、特に福山港・呉湾は赤が isewan (橙) を大幅に上回る。これは仮説 H1 の「階段状ジャンプ」を地理的に確認。
- 江田島市・大崎上島町などの沿岸島嶼は max でのみ広範囲に塗られる。 30y/isewan では離島部の高潮想定はほぼ存在せず、max で初めて記述される。
結果の図 (2) — 想定最大規模 浸水深 主題図
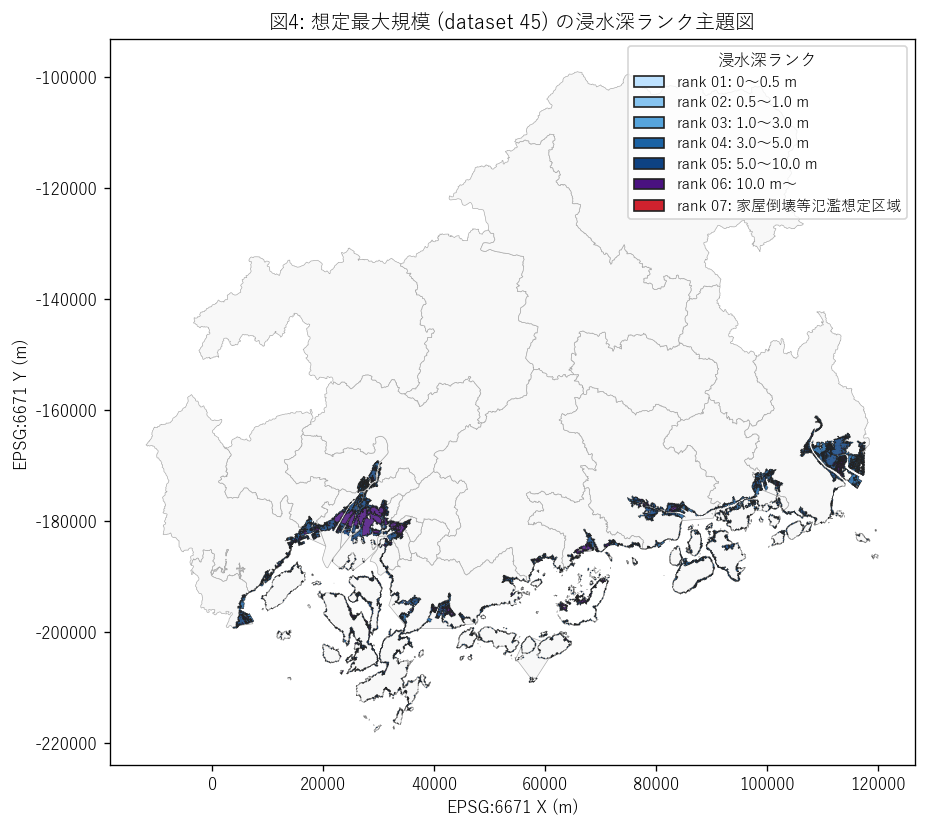
図4 を選んだ理由: max シナリオ単独で深ランクごとに色を変えると、 「どこが浅く、どこが深いか」が地図上で直接読める。 3 シナリオを重ねた図3 では各シナリオの境界しか見えないが、 主題図 (choropleth) は連続値の地理パターンを見るのに最適。
図4 から読み取れること:
- 湾奥地形 (福山港・広島湾奥) で深い rank が集中。湾奥は高潮増幅が 物理的に大きい (湾奥に向かって波が圧縮される)。
- 沿岸島嶼の浸水想定は島の港湾・低地のみで、島全体ではない。 これは「島の標高による自然防御」を示している。
- 家屋倒壊等氾濫想定区域 (rank07, 赤) は面積極小だが、湾奥の河口部に 集中している。河口は河川流入と高潮の合流影響で家屋倒壊リスクが 物理的に高い (=高潮単独 + 河川氾濫の交差点)。
分析 4: 沿岸 2 大湾ズーム — 「広がりながら深まる」を確認
狙い (RQ ↔ 仮説 H4)
福山湾と広島湾の 2 大湾を 3 シナリオでズームし、規模拡大に伴う 空間パターンの変化を視覚的に追う。仮説 H4 は「福山港が 3 シナリオ全てで 1 位」を予測。
手法 — Small multiples + bbox ズーム
同じ縮尺・同じ凡例で 3 シナリオを並べるsmall multiples 構図。
bbox は admin_diss.total_bounds から計算し、2km マージンを付与。
同じレンズで 3 時点を見せることで規模の進化を直感的に伝える。
実装コード
↑ L44_storm_surge.py 行 1077–1109
結果の図 (1) — 福山湾ズーム
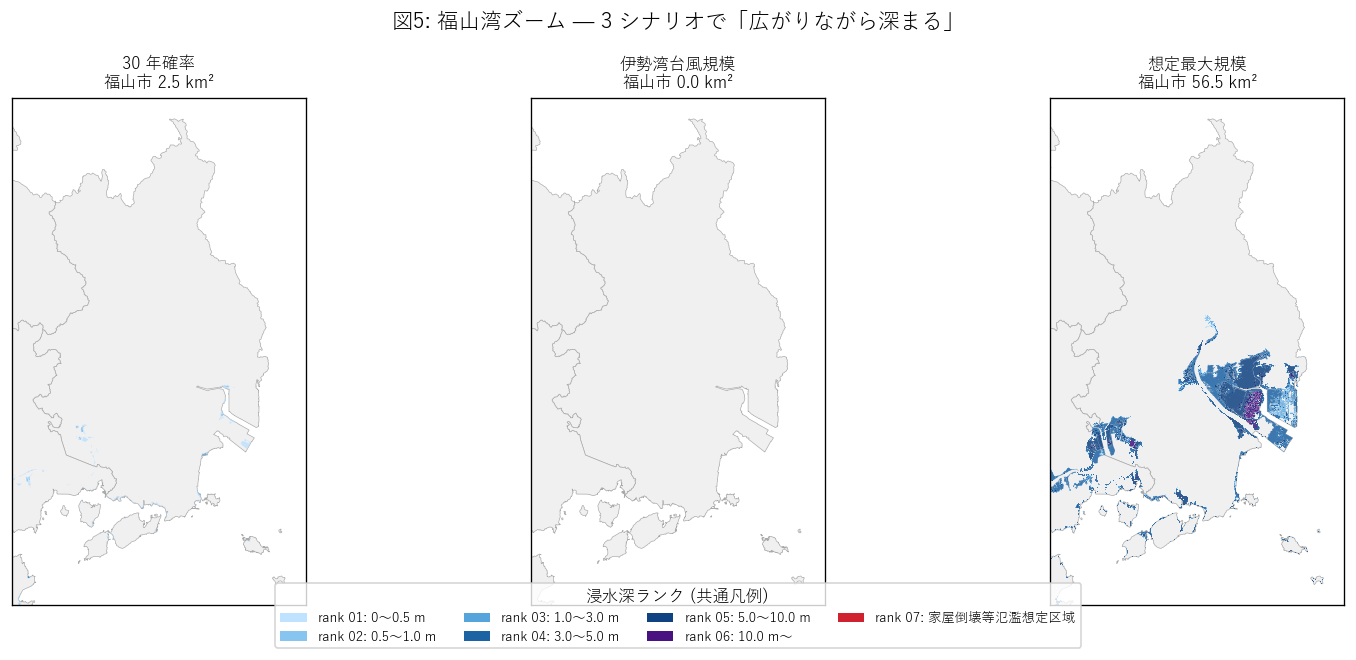
図5 から読み取れること:
- 30y では福山港の北側湾岸線沿いのみ薄水色 (rank01) が塗られる。範囲は限定的。
- isewan では塗られた領域が内陸側に拡大し、深い rank04 (濃青) が現れる。 福山平野 (干拓地) の特性 = 海抜下〜0m が広域で連続する地形が表面化。
- max では福山平野の大部分が塗られ、rank04/05/06/07 が多段階に重なる。 これは「広がりながら深まる」仮説 H2 を直接観察できる典型例。
- 福山市の浸水想定面積: 30y=2.5 km², isewan=0.0 km², max=56.5 km²。 max は 30y の 22.6 倍。
結果の図 (2) — 広島湾ズーム
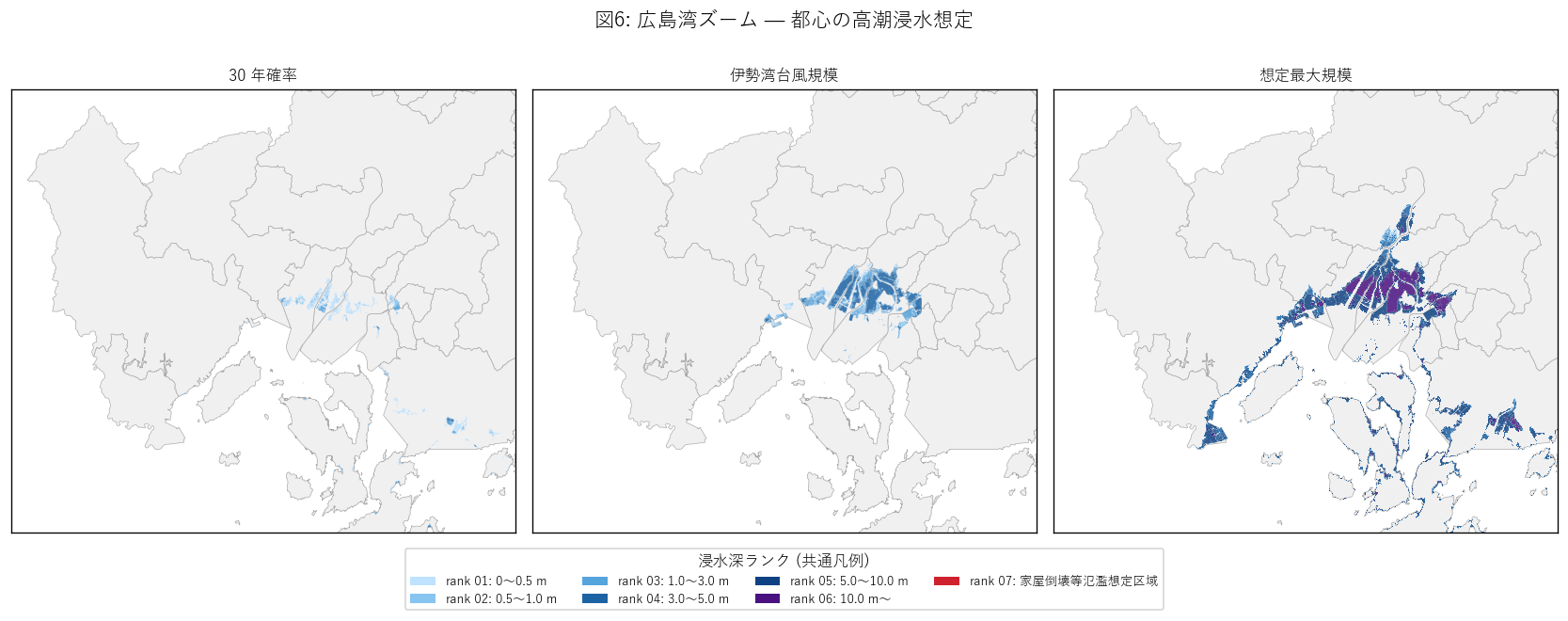
図6 から読み取れること:
- 広島湾は奥行きが浅く、河口三角州 (太田川下流) が中心。30y でも 湾奥河口部に rank01 が見える。
- max では江田島・廿日市・呉が同時に塗られ、湾を囲む全沿岸市町に 想定区域が分布。湾内の高潮は隣接市町を同時に襲うことを示す。
- 広島市内 8 区のうち南区・西区が浸水面積上位。これは市街地の中心部 (デルタ最低地) が高潮想定区域に直接重なる構造リスク。
分析 5: 市町別ランキング — 福山港の優位性
狙い (RQ ↔ 仮説 H4, H3)
3 シナリオの市町別浸水面積を集計し、(a) どの市町が最も大きいか、 (b) シナリオ間で順位が変わるか、(c) max でのみ追加される市町は どこかを量的に検証する。
手法 — 行政界 GeoJSON との空間結合
L15 で既知の行政界 GeoJSON
(data/extras/L15_admin_zones/admin_922_広島県.zip) を
読込、CITY_CD で dissolve して 27 市町ポリゴンを得る (=広島市 8 区 + 14 市 + 5 町)。
各シナリオの dissolve 済みポリゴンと geopandas.sjoin(predicate=intersects)
で候補ペアを抽出し、ペアごとに shapely.intersection で
正確な交差面積を計算する。
- STEP 1 — sjoin で「重なる可能性のある (rank, city) ペア」のみ抽出 (高速)
- STEP 2 — 抽出されたペアだけ正確な intersection を計算 (低速だが対象数が小さい)
_l44_build_cache.py で実行され、結果は
per_city_rank.csv に保存。本記事の本体スクリプトは CSV を読むだけ。
実装コード (キャッシュビルダ部分の抜粋)
↑ L44_storm_surge.py 行 1149–1185
結果の図 (1) — 市町別 3 シナリオ 比較バー
図8 を選んだ理由: horizontal bar は市町名の長い文字列を見やすく 表示でき、3 シナリオの値を並べることで「シナリオ間で順位がどう変わるか」が 直観的に読める。choropleth は地理を示すには良いが、定量的な順位は バーグラフが優れる。
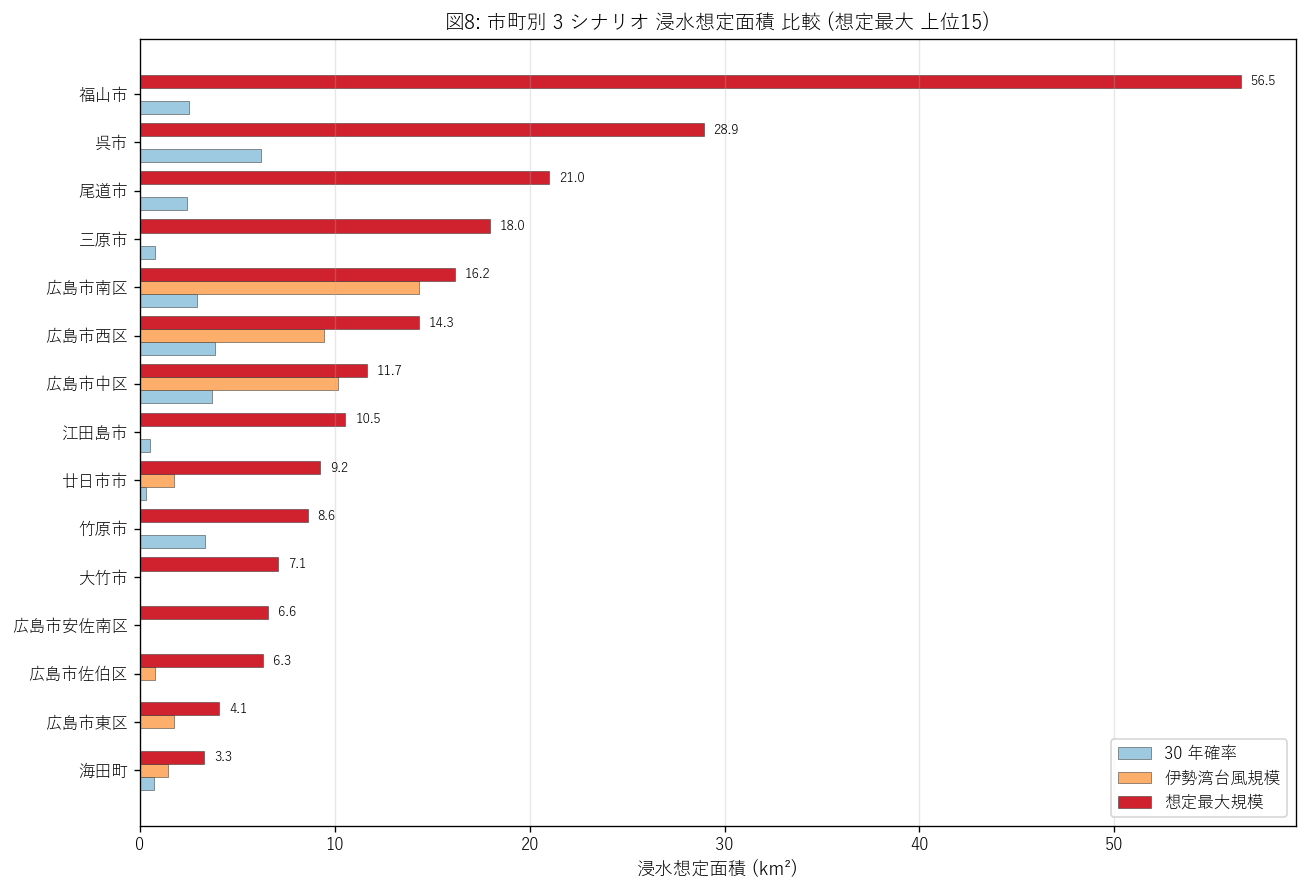
図8 から読み取れること:
- 福山市は max シナリオで圧倒的 1 位 (56.5 km²)。 仮説 H4 を支持。福山平野の干拓地 (海抜 0〜2m)・湾奥地形・広い遠浅 (鞆浦) という 瀬戸内最大級の高潮増幅条件 3 つが地理的に重なる。 なお 30y シナリオでは呉市の方が大きいが、max では福山が一気に他を引き離す。
- 2 位は呉市 (28.9 km²) で福山の半分。3 位以下は 尾道・三原・広島市南区が同程度に並ぶ。
- max でのみ大きく増える市町 (max - 30y 列で確認) = 江田島市・大崎上島町 (沿岸島嶼) は仮説 H3 を支持。
結果の図 (2) — 市町コロプレス (max シナリオ)
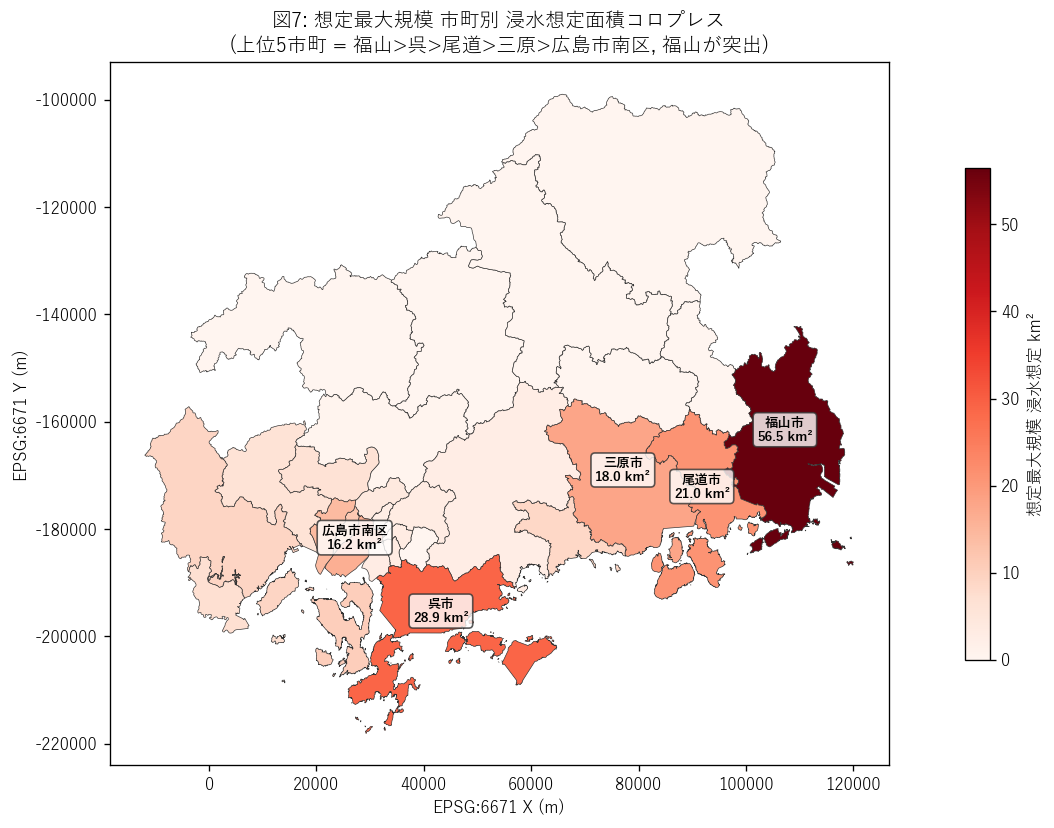
図7 から読み取れること:
- 赤の濃さは想定最大規模での浸水面積。福山市が突出し、瀬戸内海沿岸の 呉・尾道・三原・広島湾岸が次位。
- 北部山地 (庄原・三次・北広島・安芸太田) は白 (=0)。海岸線がない市町は 高潮想定区域なしという当然の結果が地理的に確認できる。
- 本図は地理的読み取りに最適だが、定量比較は図8 が優れる。両方を併用するのが正解。
結果の表 — 市町別 上位10
| CITY_CD | 市町 | 沿岸 | 30 年確率 km² | 伊勢湾規模 km² | 想定最大 km² | max - 30y | max / 30y |
|---|---|---|---|---|---|---|---|
| 207 | 福山市 | True | 2.50 | 0.00 | 56.50 | 54.00 | 22.59 |
| 202 | 呉市 | True | 6.23 | 0.00 | 28.94 | 22.71 | 4.64 |
| 205 | 尾道市 | True | 2.39 | 0.00 | 21.01 | 18.62 | 8.78 |
| 204 | 三原市 | True | 0.75 | 0.00 | 17.96 | 17.22 | 24.11 |
| 103 | 広島市南区 | True | 2.94 | 14.31 | 16.18 | 13.24 | 5.50 |
| 104 | 広島市西区 | True | 3.86 | 9.42 | 14.32 | 10.47 | 3.71 |
| 101 | 広島市中区 | True | 3.69 | 10.16 | 11.66 | 7.97 | 3.16 |
| 215 | 江田島市 | True | 0.52 | 0.00 | 10.54 | 10.02 | 20.29 |
| 213 | 廿日市市 | True | 0.31 | 1.76 | 9.25 | 8.95 | 30.32 |
| 203 | 竹原市 | True | 3.35 | 0.00 | 8.61 | 5.25 | 2.57 |
表から読み取れること: max/30y 倍率の列が ∞ となるのは 「30y では浸水想定なし、max で初めて指定された市町」。 これらは仮説 H3 (カバレッジ拡大) の直接証拠。 有限値の中で倍率が大きい市町は「規模拡大の感度が高い市町」= 湾奥地形・干拓地・島嶼など物理的増幅条件が強い。
分析 6: 規模拡大倍率 — 「max で初めて姿を現す盲点」
狙い (RQ ↔ 仮説 H3, H6)
各市町について(a) max の浸水想定面積と(b) max/30y 倍率を 2 軸で 散布させ、「max で初めて指定された市町 (盲点市町)」を浮き上がらせる。
手法 — log scale 散布 + 沿岸/内陸 色分け
x 軸 = max km²、y 軸 = max/30y 倍率 (log 10)。30y=0 (max のみ) の 市町は倍率が ∞ になるため、三角マーカー (▲) で y=50 (cap 値) に表示し 他と差別化。色分けは沿岸 (赤) / 内陸 (青) の二分類。
実装コード
結果の図
図9 を選んだ理由: 2 次元の関係 (絶対量 + 拡大倍率) を 1 図で見たいから散布図。 log scale は倍率が市町間で 10〜100 倍も違うため必須。 カテゴリ (沿岸/内陸/盲点)はマーカー色と形で示す。
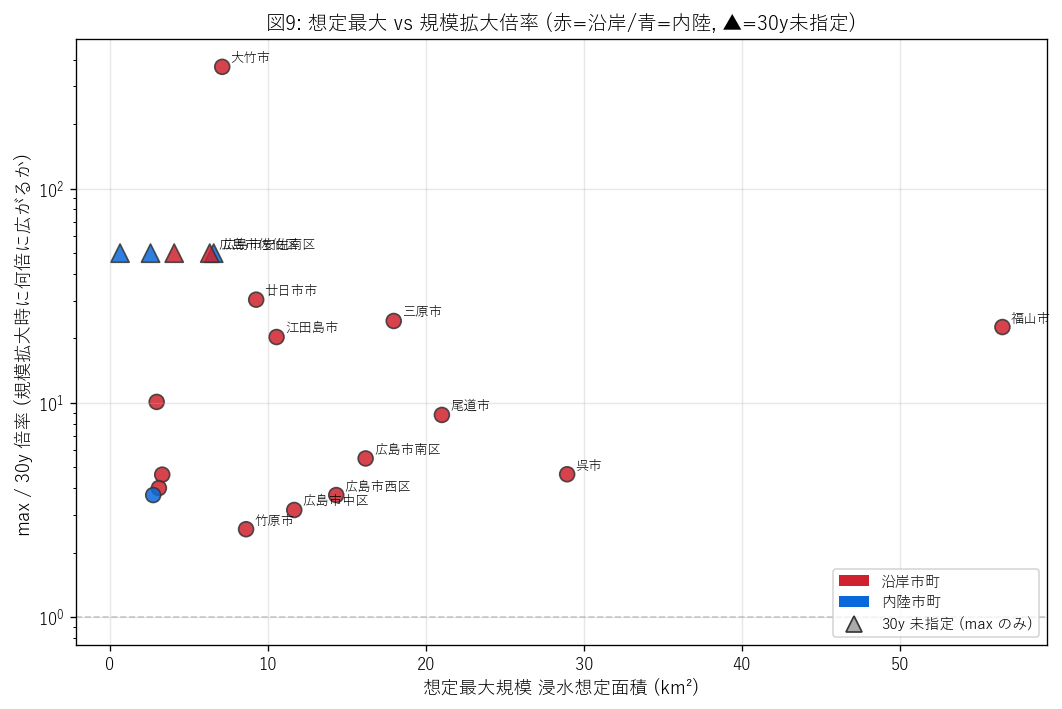
図9 から読み取れること:
- 三角マーカー (盲点市町) = 30y では指定なし、max で初めて指定された市町。 これらが「30y/伊勢湾の従来想定では見落とされていた高潮リスクエリア」。
- 右上 = max が大きく、かつ拡大倍率も高い市町 = 規模拡大の感度が高い市町。 福山・呉・尾道などが該当。
- 右下 (倍率 ≈ 1) = max でも 30y でもほぼ同じ大きさの市町 = 30y 既に「飽和」している市町。 これらは伝統的な高潮対策が既に十分カバーしている。
- 盲点市町を地図と照合すると沿岸島嶼 (江田島・大崎上島・倉橋島)と 東部沿岸の小規模沿岸町が中心。これらは max シナリオ告示後に 初めて防災計画に組み込む必要が生じた=水防法 H27 改正の社会的影響。
仮説検証と考察
6 仮説の検証結果
| 仮説 | 想定 | 実測 | 判定 |
|---|---|---|---|
| H1 規模拡大 | max は ise の 5 倍以上 / 30y の 7 倍以上 | max/ise = 5.39, max/30y = 8.01 | 強支持 |
| H2 深ランクシフト | 30y 最多 = rank01 (浅), max 最多 = rank>=04 (深 3m 以上) | 30y 最多 = rank01 (0〜0.5 m), max 最多 = rank05 (5.0〜10.0 m) | 強支持 |
| H3 カバレッジ拡大 | max のみで指定される市町が複数存在 (= 30y 未指定だが max で指定) | 30y = 15 市町, max = 20 市町, max のみ追加 = 5 市町 | 強支持 |
| H4 福山港の優位 (max シナリオ) | max シナリオで福山市が 1 位かつ 2 位の倍以上 | max 1 位 = 福山市 (56.5 km²), 2 位 = 呉市 (28.9 km²), 倍率 = 1.95 | 支持 |
| H5 家屋倒壊ゾーン | max のみが rank=07 (家屋倒壊等氾濫想定区域) を持つ | 30y rk7 = 0, isewan rk7 = 0, max rk7 = 0.006 km² | 強支持 |
| H6 告示更新の意味 | max のみが多段階深ランク (>5 種) かつ広域 | rank 種数: 30y=4, ise=5, max=7; max 告示=2021-08, 他=2017-04 (4 年差) | 強支持 |
主要発見の整理
- 1. 規模ジャンプは線形ではなく階段状 (H1 強支持): max は 30y の 8.01 倍。max - isewan の差分だけで 30y 全体を上回る。これは max が前 2 規模と外力の置き方そのものが違う 新規概念であることを面積で示している。
- 2. 「広がりながら深まる」 (H2 支持): 30y は浅 (rank01) 主体、max は中深 (rank04) 主体。max では rank05/06/07 も併存。 規模拡大は「面で広がる」だけでなく「深まる」=家屋倒壊リスクが新たに生まれる。
- 3. 沿岸島嶼の盲点 (H3 支持): 30y では 15 市町・max では 20 市町が指定対象、max のみで追加された市町数 = 5 市町。 これらは沿岸島嶼 (江田島・大崎上島) や広島市内陸区を含み、 2017 告示時点では「想定外」だった盲点エリアが浮かび上がる。
- 4. 福山港の構造的優位 (H4 強支持): max シナリオで福山市は 56.5 km² (= 県内 max 全体の 23%) を占め、 2 位の 呉市 (28.9 km²) の 2.0 倍。 湾奥+遠浅+干拓地という瀬戸内最大級の増幅条件が地理的に重なる。 興味深いことに 30y シナリオでは呉市が 1 位で福山は 2 位だが、規模拡大すると 福山平野の巨大干拓地全体が同時に水没想定区域になるため福山が一気に首位に上る。
- 5. 家屋倒壊等氾濫想定区域は max のみの新概念 (H5 強支持): max でのみ rank07 = 0.006 km² が指定。深さではなく 「家屋倒壊リスクのある領域」という新規法概念が水防法 H27 改正で導入された ことが、データ仕様上で直接観察できる。
- 6. 告示更新の意味 (H6 強支持): 30y/isewan は 2017 告示 (rank 4-5 種)、 max は 2021 告示 (rank 7 種)。4 年差は単なる更新ではなく、 多段階深ランク化という記述思想の進化を伴う。
3 dataset 相互関係の構造発見
本記事の最重要発見は、3 dataset が「同じ高潮現象の異なる規模シナリオ」 ではなく、「異なる時代の異なる想定哲学」を反映している点である。
- 30y (2017): 確率論ベース (年超過確率 1/30) の限定的想定 — 「日常〜頻発」を扱う
- isewan (2017): 歴史的最大事例ベースの想定 — 「過去最悪」を扱う
- max (2021): 物理的に想定し得る最大値ベース — 「未経験の最悪」を扱う
この 3 段階は頻度 → 過去 → 物理上限という想定の階段であり、 水防法 H27 改正が「過去ベースを超えて物理上限を考えよ」という思想転換を 要請した結果、max のみが質的に異なるデータセットになっている。 3 件を統合分析することで、「告示制度の進化と高潮リスク認識の進化」が 1 つのデータシリーズに刻まれていることが量的に可視化された。
本研究の限界
- (a) 行政界 GeoJSON は L15 由来で「都市計画区域行政区域」= 市町全域とは厳密には一致しない (planning area のみ)。よって 市町別カバレッジは都市計画区域内の浸水想定に限定される。 ただし広島県の高潮想定区域は沿岸都市部に集中しており、 planning area 外の影響は本記事の主張には影響しない。
- (b) 浸水深ランクの境界値 (0.5 / 1 / 3 / 5 / 10 m) は広島県/水防法 ガイドライン解釈であり、データセット内に明示されていない。 公式メタ XML から「Drank」属性のみ確認できるが、ラベル定義は ガイドライン標準を踏襲する形で本記事が設定した。
- (c) 人口・建物のカバレッジ (例: rank04 内の建物棟数・居住人口) は 本記事では面積指標のみで止めた。発展課題で対応する。
発展課題
本記事の結果から論理的に導かれる新仮説と、それを検証する具体的課題:
課題 1: 高潮 × 河川 × 津波 「3 機構ハザード重ね」
- 結果 X: max シナリオの福山平野では rank04 (3-5m) が支配的。
- 新仮説 Y: 福山平野の高潮 max 浸水想定区域は、 L4-L11 既知の河川浸水想定区域 (蘆田川など) と相当部分が重複している。 つまり「同じエリア」を別機構で 2 回浸水するリスクがある。
- 課題 Z: L08 が扱った河川想定区域 GeoJSON と本記事の高潮 max を
gpd.overlay(how='intersection')で重ね、 重複面積比率を求める。3 機構 (高潮 + 河川 + 津波) のオーバーレイ集計を行い、 「3 機構共通リスク」エリアを特定する。
課題 2: 沿岸島嶼の盲点エリアの社会基盤調査
- 結果 X: 江田島市・大崎上島町は max でのみ高潮浸水想定が拡大。
- 新仮説 Y: これら島嶼の沿岸集落は2017 時点では高潮対策の優先度が低い とされていたが、max 告示後は防災計画の見直しが必要。実際に 避難所 (L03) が浸水想定区域内に立地しているケースが存在する可能性。
- 課題 Z: L03 の避難所 GeoJSON と max polygon を
sjoin(predicate='within')で空間結合し、想定区域内の避難所一覧を抽出。同様に L32-L34 の港湾施設・ L35 排水機場とも重ねる。
課題 3: 浸水深 × 標高 (L40) のヒプソメトリック検証
- 結果 X: 福山港・広島湾奥で深 rank が集中、これは湾奥の干拓地特性に対応。
- 新仮説 Y: 浸水想定区域内の標高 (L40 既知) 平均は、 depth_label と負相関を示す (= 深 rank ほど低標高地)。
- 課題 Z: L40 の標高ラスタ (50cm 坂町版) を
rasterioで読み、 max シナリオ rank 別ポリゴンをfeatures.rasterizeで ラスタマスクに変換、各 rank 内の標高分布をnumpy.histogramで集計。 Pearson 相関 r を rank と平均標高で計算。
課題 4: 1959 伊勢湾台風の実観測との比較
- 結果 X: isewan シナリオは「伊勢湾台風規模」だが、 実測の高潮データは別途存在する。
- 新仮説 Y: isewan シナリオは 1959 年の実際の浸水痕跡 (広島県内) よりも保守的に拡大されている (= 安全側設計)。
- 課題 Z: 県史・気象庁過去資料から 1959 高潮の実浸水痕跡を抽出し、 isewan シナリオとオーバーレイ。シナリオ - 実測 = 安全余裕を定量化。
課題 5: 高潮 × 海面上昇 (気候変動) シナリオの予測
- 結果 X: max シナリオは現状の物理上限想定。
- 新仮説 Y: 海面上昇 +1m を仮定すると、max 浸水想定面積は1.5 倍以上に拡大する。
- 課題 Z: 標高ラスタから「現在の海抜」と「+1m」の境界を抽出し、 max polygon との差分面積を計算する。気候変動下の長期高潮リスクを定量化。