観測情報 9 件統合分析 — 県の防災観測網 (rain/water/dam/tide/wind) の幾何構造
データ取得手順
✅ このスクリプトは初回実行時にデータを自動取得します(DoBoX からの直接ダウンロード)。
| ID | データセット名 |
|---|---|
| #222 | dataset #222 |
| #444 | dataset #444 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #999 | dataset #999 |
| #1274 | 観測情報_観測所一覧 |
| #1275 | 観測情報_雨量日集計 |
| #1276 | 観測情報_雨量年集計 |
| #1437 | 観測情報_水位日集計 |
| #1438 | 観測情報_水位年集計 |
| #1439 | 観測情報_ダム日集計 |
| #1440 | 観測情報_ダム年集計 |
| #1441 | 観測情報_潮位日集計 |
| #1442 | 観測情報_風向風速日集計 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L31_observation_network.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
シリーズ構造判定: (b) パターン
このシリーズの 9 件は、L17/L24 のような「市町別の同一データ N 市町分」 ではなく、「マスタ 1 件 + 5 観測種類 × {日集計, 年集計} 8 件」 の 2 層構造です。本記事はマスタを主軸に、各時系列 dataset を構造として併置します。
独自用語の定義 (本記事内で固定)
| 用語 | 定義 |
|---|---|
| 観測網 | 広島県内に設置された 5 観測種類 (雨量・水位・ダム・潮位・風) の観測点の総体。 本記事では観測所マスタ (dsid=1274) に登録された 623 点 を観測網の現在の実体とする。 |
| 観測点 (観測所) | 緯度経度を持つ 1 個の物理計測サイト。1 つの観測所が複数の観測種類を持つ場合は、 マスタ上は「データ種別」ごとに別行として登録される (例: 「広島港」が潮位と風で 2 行)。 |
| カバレッジ | 県土の任意点から、最も近い観測点までの距離。本記事では 1.5 km grid を県土全域に張って計測する。 |
| 観測空白 | カバレッジが 4.0 km 以上 の grid 点。本記事ではこの基準で空白を可視化する。 当初 8 km と仮置きしたが、実測で観測網が想定より遥かに密 (最大 10 km / 中央値 2 km) だったため、 「明らかな空白」と呼べる 4 km に下方修正した。仮説の修正自体が観測網理解の重要な一歩。 |
| 先行指標 | 河川氾濫閾値 (はん濫注意・避難判断・はん濫危険) を保有する水位観測。 これらは「水位がこの値を超えたら警報を出す」運用ノードであり、災害発生に先行する情報を提供する。 |
| 所管二元性 | 観測網が「県管理 (砂防課・河川課・河川課ダムG・農業基盤課・港湾漁港整備課)」と 「国管理 (国土交通省・国ダム・気象台・海上保安庁)」の2 主体で運用されている構造。 |
研究の問い (RQ)
広島県内の防災観測網は、観測種類別に何拠点配置され、地理的にどの流域・どの地域を カバーしているか? その配置パターンから、県の災害監視思想はどう読み取れるか?
- 5 観測種類 (雨量/水位/ダム/潮位/風) は何拠点ずつ、どの所管に配置され、地理的にどう分布するか?
- 観測点間距離から見た観測網の空間粒度と空白地帯は?
- 水系・市町別の観測点密度はどれだけ偏っているか?
- 河川氾濫閾値を保有する観測所は、「先行指標」として機能できる場所にあるか?
仮説 H1〜H6
- H1 (種別不均衡): 雨量 > 水位 ≫ 風 ≫ ダム ≈ 潮位、雨量だけで 60% 以上を占める。
- H2 (所管二元性): 県管理 vs 国管理 がほぼ折半 (差 40% 未満)。
- H3 (水系密度): 太田川・江の川・芦田川の主要 3 水系で観測点 50%以上を集中。
- H4 (海岸線潮位): 潮位 13 点は全て瀬戸内沿岸、内陸ゼロ。
- H5 (氾濫閾値階層): 水位観測の 50% 以上に氾濫閾値あり。残りは「監視のみ」。
- H6 (空白地帯): 雨量で 4.0 km 以上離れる観測空白が 5〜25% の grid に出現 (当初 8 km と置いたが、実測で観測網の最大空白が約 10 km、中央値 2 km と極めて密であることが判明したため、 本記事では「明らかな空白」の基準を 4 km に下方修正。これは仮説の更新自体が研究の重要なステップ)。
到達点
9 dataset_id を「マスタ 1 + 5 種類 × 2 粒度 = 9」の 2 層構造として読み解き、 634 観測所の地理分布・水系分布・閾値構造を統合した結果、 県の観測網が「降水と河川を最優先」「沿岸と山地を補完」という設計思想で 組まれていることを実データで裏付ける。
使用データ
本記事が使用する 9 dataset_id の一覧と役割。中央 1 件がマスタ、残り 8 件が時系列。
| dsid | 役割 | 観測種類 | 粒度 | 形式 | サイズ(KB) | DoBoX |
|---|---|---|---|---|---|---|
| 1274 | master | — | — | CSV | 154.6 | #1274 |
| 1275 | timeseries | 雨量 | daily | CSV | 1737.2 | #1275 |
| 1276 | timeseries | 雨量 | yearly | CSV | 623.2 | #1276 |
| 1437 | timeseries | 水位 | daily | CSV | 426.8 | #1437 |
| 1438 | timeseries | 水位 | yearly | CSV | 132.5 | #1438 |
| 1439 | timeseries | ダム | daily | CSV | 254.7 | #1439 |
| 1440 | timeseries | ダム | yearly | CSV | 77.4 | #1440 |
| 1441 | timeseries | 潮位 | daily | CSV | 116.0 | #1441 |
| 1442 | timeseries | 風向風速 | daily | CSV | 205.1 | #1442 |
シリーズ構造判定の根拠
判定: (b) 9 種類の異なる観測データ。理由は以下の表の通り、 9 件は明らかに「マスタ 1 + 5 種類 × 2 粒度」の機能分化型であり、 「9 市町分の同一データ」ではない。
時系列 8 件 はそれぞれ観測所×時刻の wide 表。観測所名で結合可能。
マスタ vs 時系列ファイル のカバレッジ
マスタの観測所と、各時系列ファイルが提供する観測所列を観測所名で照合。 基本的にマスタ⊇時系列だが、潮位・風など一部に非対称あり。詳細は分析 4 で図示。
| kind | kind_label | n_master | n_ts | n_common_by_name | n_only_master | n_only_ts |
|---|---|---|---|---|---|---|
| rain | 雨量 | 390 | 3 | 0 | 385 | 3 |
| water | 水位 | 181 | 178 | 178 | 1 | 0 |
| dam | ダム | 18 | 18 | 18 | 0 | 0 |
| tide | 潮位 | 13 | 13 | 13 | 0 | 0 |
| wind | 風向風速 | 21 | 21 | 21 | 0 | 0 |
ダウンロード
生データ (DoBoX 直リンク)
- 観測所一覧 (dsid=1274): 直 DL / DoBoX
- 雨量_日集計 (dsid=1275): 直 DL / DoBoX
- 雨量_年集計 (dsid=1276): 直 DL / DoBoX
- 水位_日集計 (dsid=1437): 直 DL / DoBoX
- 水位_年集計 (dsid=1438): 直 DL / DoBoX
- ダム_日集計 (dsid=1439): 直 DL / DoBoX
- ダム_年集計 (dsid=1440): 直 DL / DoBoX
- 潮位_日集計 (dsid=1441): 直 DL / DoBoX
- 風向風速_日集計 (dsid=1442): 直 DL / DoBoX
中間データ (本記事生成 CSV)
- L31_series_9.csv — 9 dataset の役割表
- L31_stations_full.csv — 観測所マスタ (623 行) を kind ラベル付きで整形
- L31_kind_counts.csv — 種別 5 区分の件数表
- L31_origin_breakdown.csv — 所管別件数
- L31_pivot_watershed.csv — 水系 × 種別ピボット
- L31_pivot_city.csv — 市町 × 種別ピボット
- L31_attr_fillrate.csv — 閾値属性の埋まり率
- L31_master_vs_ts.csv — マスタ vs 時系列カバレッジ
- L31_ts_structure.csv — 時系列 wide CSV の構造
- L31_nearest_stats.csv — 種別ごとの最近隣距離統計
- L31_blank_grid.csv — 1.5 km グリッド × 最寄り距離
- L31_hypothesis_results.csv — H1〜H6 検証結果
図 (本記事生成 PNG)
- L31_fig1_kind_counts.png / L31_fig2_pref_overview.png / L31_fig3_kind_smallmult.png
- L31_fig4_watershed_density.png / L31_fig5_city_density.png / L31_fig6_flood_threshold.png
- L31_fig7_blank_zones.png / L31_fig8_nearest_dist.png / L31_fig9_series_matrix.png
- L31_fig10_master_ts_coverage.png / L31_fig11_dataset_cards.png
再現用 Python スクリプト
L31_observation_network.py を取得して
プロジェクトルートで py -X utf8 lessons/L31_observation_network.py を実行。
データが無ければ自動取得します。
分析 1: 9 dataset の構造を可視化
狙い
9 件の dataset がどう機能分化しているのかを 1 枚の絵で示す。 これは「カバー宣言」の構造図であり、後続の全分析の論理的下敷きとなる。
手法 (簡潔に)
各 dataset の (役割, 観測種類, 粒度) を抽出し、2 軸マトリクスに 配置する。 役割: master / timeseries。 粒度: master / daily / yearly。 さらにカード形式で件数 + dsid を視覚化する。
実装
↑ L31_observation_network.py 行 1332–1374
図と読み取り
なぜこの図か: 9 つの dataset_id を「マスタと時系列」「日と年」のどちらかに分類することで、 シリーズの本来の構造 (機能分化型) が一望できる。表のままだと粒度の有無が読み取りにくい。
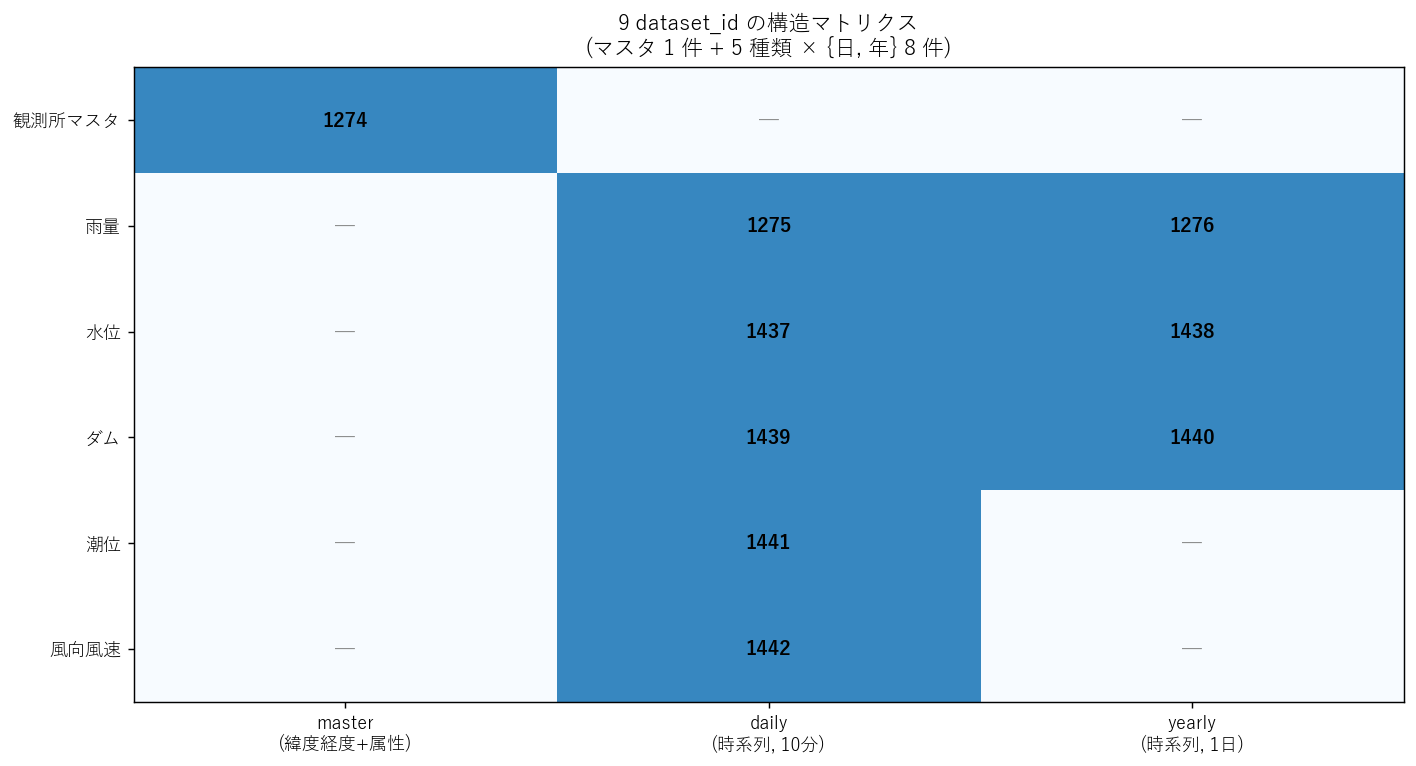

読み取り:
- マスタ 1 件 (1274) が観測所一覧として地理キーを保有。緯度経度・水系・河川・市町・氾濫閾値を含む 35 列。
- 時系列 8 件 は観測種類 (5 種) × 粒度 (日, 年) のうち、潮位と風の年集計のみが欠けている (= 6 種類しか日集計がない訳ではなく、潮位と風は日のみで運用)。
- このシリーズ全体は「観測網の地理を 1 枚に集約し、各観測種類の値時系列を別 dataset で提供する」という設計。地理結合キーは観測所名。
表と読み取り
| dsid | abbr | role | kind | granularity | file | size_kb |
|---|---|---|---|---|---|---|
| 1274 | 観測所一覧 | master | None | None | stations_master.csv | 154.6 |
| 1275 | 雨量_日集計 | timeseries | rain | daily | rain_daily_sample.csv | 1737.2 |
| 1276 | 雨量_年集計 | timeseries | rain | yearly | rain_year_sample.csv | 623.2 |
| 1437 | 水位_日集計 | timeseries | water | daily | water_daily_sample.csv | 426.8 |
| 1438 | 水位_年集計 | timeseries | water | yearly | water_year_sample.csv | 132.5 |
| 1439 | ダム_日集計 | timeseries | dam | daily | dam_daily_sample.csv | 254.7 |
| 1440 | ダム_年集計 | timeseries | dam | yearly | dam_year_sample.csv | 77.4 |
| 1441 | 潮位_日集計 | timeseries | tide | daily | tide_daily_sample.csv | 116.0 |
| 1442 | 風向風速_日集計 | timeseries | wind | daily | wind_daily_sample.csv | 205.1 |
読み取り:
- サイズ最大はマスタ次いで雨量日 (1.7 MB) — これは雨量の観測所数が最大かつ 10 分粒度で粒度が高いため。
- 潮位日 (~120 KB) と風日 (~210 KB) は雨量日の1/10 規模。観測所数が少なく粒度も粗い。
- 年集計は日集計の 1/3〜1/5 サイズ。1 日 1 値に集約されている。
分析 2: 観測種類別の件数と所管
狙い
5 観測種類が何点ずつ配置され、誰が所管するかの全体像を確定する。 これが H1 (種別不均衡) と H2 (所管二元性) の検証の中核。
手法
マスタ (623 行) を「データ種別」(1=雨量/4=水位/7=ダム/12=潮位/13=風) と 「データ所管」 (砂防課・国土交通省など 9 種) でクロス集計。 所管は「県/国/その他」の 3 グループに集約する (定義は冒頭表を参照)。
実装
↑ L31_observation_network.py 行 1391–1419
図と読み取り
なぜこの図か: 棒グラフ + スタックは「絶対数 + 構成比」を 1 セクションで示せる。 件数バー単独では所管の二元性が見えず、所管比単独では絶対数が見えない。
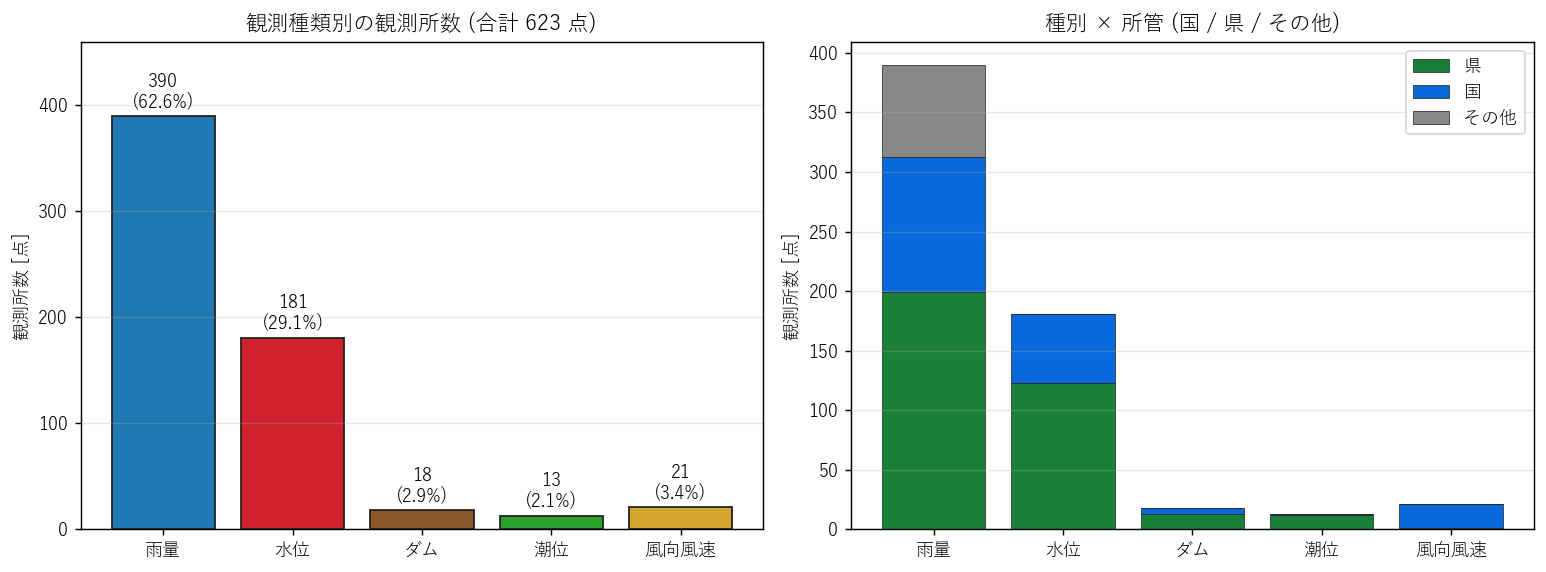
読み取り:
- 雨量が最多 (390 点 / 62.6%) で、水位 (181 点 / 29.1%) と合わせて全体の 91.7%。 水文 (降水と河川) が観測網の主軸。
- ダム (18 点) と潮位 (13 点) は最少。これは物理的設置可能箇所が限定的な観測種類。
- 所管スタックを見ると、ダムは河川課ダムG/国ダムでほぼ全件、潮位は港湾漁港整備課、風は気象台がほぼ独占。 所管の専門化が強い。
- 逆に雨量と水位は所管が分散しており、「砂防課・河川課・国土交通省・気象台」が分担。
表と読み取り
| kind | kind_label | n_stations | pct |
|---|---|---|---|
| rain | 雨量 | 390 | 62.60 |
| water | 水位 | 181 | 29.05 |
| dam | ダム | 18 | 2.89 |
| tide | 潮位 | 13 | 2.09 |
| wind | 風向風速 | 21 | 3.37 |
| origin | データ所管 | n |
|---|---|---|
| 県 | 河川課 | 137 |
| 県 | 砂防課 | 132 |
| 国 | 国土交通省 | 109 |
| 県 | 河川課ダムG | 57 |
| 国 | 気象台 | 53 |
| 国 | 国ダム | 35 |
| 県 | 港湾漁港整備課 | 13 |
| 県 | 農業基盤課 | 9 |
| 国 | 海上保安庁・港湾漁港整備課 | 1 |
読み取り:
- 砂防課 132 件は全件雨量 (砂防警戒のための雨量計)。県の防災運用上、土砂災害監視の中核。
- 河川課 137 件は雨量 + 水位の混合。河川管理に直結する観測ノード。
- 気象台 53 件は雨量 + 風が中心。広域気象監視のサポート観測網。
分析 3: 県全域マップで観測網を観る
狙い
件数だけでは観測網の地理偏在は見えない。同じ 401 点の雨量でも、 都市集中型と均等分散型では運用思想が違う。マップで 1 枚に重ねた俯瞰と、 種別ごとに分離した small multiples の 2 段で確認する。
手法
マスタの緯度経度を Shapely Point に変換し、EPSG:4326 → EPSG:6671 (平面直角 III) に投影。 広島県全域 polygon (L15 の dsid=922 を流用) を背景に重ねる。 種別ごとに色分けし、small multiples で 5 種を別パネルにも展開する。
実装
↑ L31_observation_network.py 行 1446–1474
図と読み取り
なぜこの図か: 観測網は地理的実体なので、地図化が最も直感的。 重ね地図で全体感、small multiples で個別パターンを見る。

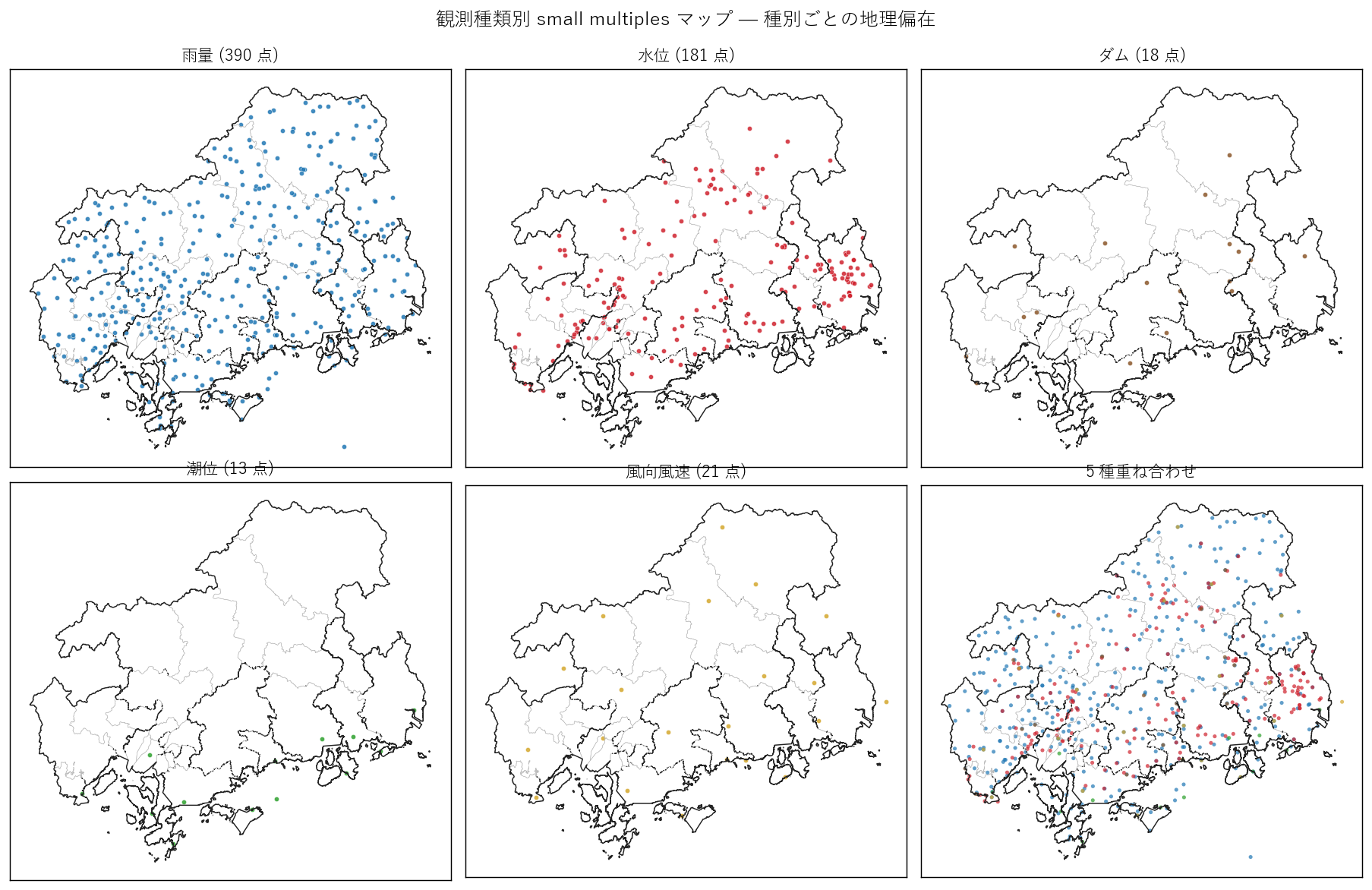
読み取り:
- 雨量 (青) は県全域に均等分布。山地・離島まで及ぶ。砂防運用が県全土にスパンしていることの帰結。
- 水位 (赤) は河川沿いに線状に配置。江の川 (北部)、太田川 (中部)、芦田川 (東部) の幹線が読める。
- ダム (茶) は山間部に点在。中山間ダムと、瀬戸内沿岸の小規模ダムの 2 グループ。
- 潮位 (緑) は瀬戸内海岸線のみ。内陸ゼロ、H4 を支持する。
- 風 (黄) は気象台立地に依存し、市街地と一部島嶼に偏る。
分析 4: 水系・市町別の密度
狙い
「どこにどれだけ観測点があるか」を水系・市町の 2 視点で集計し、 H3 (主要 3 水系集中) を検証する。同時に観測網の偏りを可視化する。
手法
マスタを水系名・市町村名でグループ化し、種別を列としてピボット。 上位 12 水系 / 上位 15 市町を横棒スタックで比較。
実装
↑ L31_observation_network.py 行 1489–1504
1489 1490 1491 1492 1493 |
図と読み取り
なぜこの図か: 水系密度と市町密度は、観測網が「自然単位 (水系) の地理」と 「行政単位 (市町) の地理」のどちらに沿って配置されているかを示す。 両方を並べることで「水系優先 vs 行政優先」の軸を読み取れる。
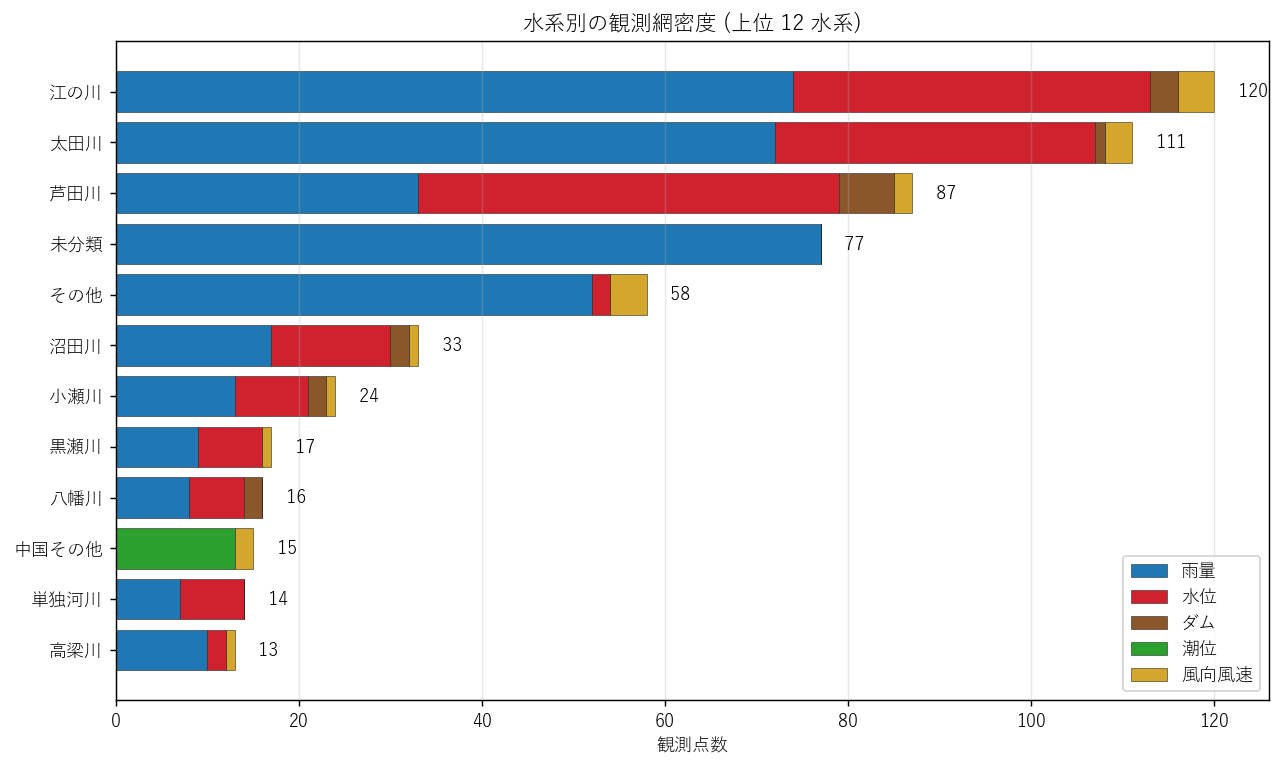
読み取り (水系):
- 上位 3 水系 (江の川, 太田川, 芦田川) で51.0% (318/623) を占有。H3 を 支持。
- 太田川は流域最大の県管理河川で、雨量 + 水位の双方が密。「降雨 + 流出」を組で観測する設計が読める。
- 江の川は中山間部の長い水系で、観測点が長距離に分散。1 流域あたりの観測網延長が大きい。
- 芦田川 (福山) は人口集中地下流のため、水位観測の比率が他より高い。
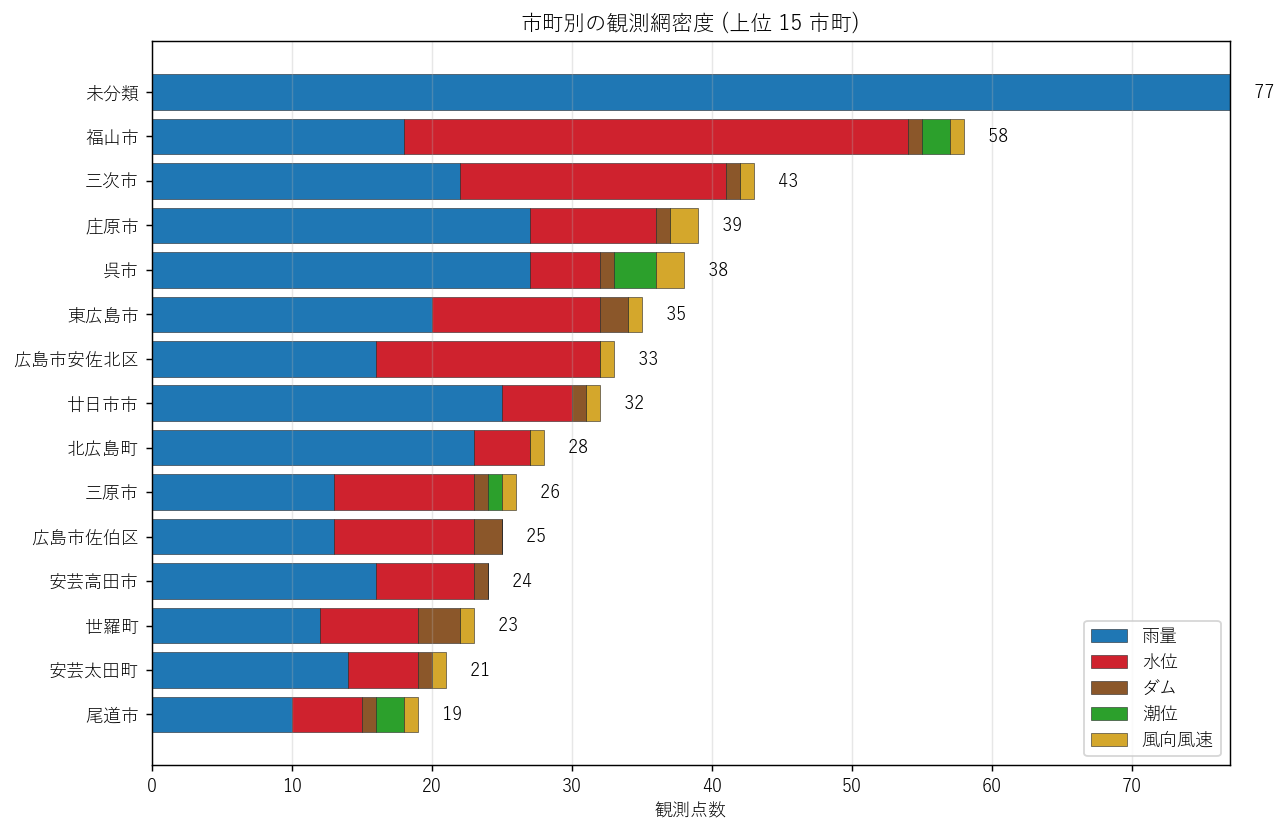
読み取り (市町):
- 福山市 (58 点) と三次市 (43 点) が突出。それぞれ「人口集中地」と「中山間水系の交差点」という対照的理由で観測密。
- 政令市の広島市は区別に分割されているため上位ランクには現れにくいが、安佐北区 33 点・佐伯区 25 点・東区などを足すと合計 130 点超。実質トップ。
- 福山以外の沿岸都市 (呉・尾道・三原) は雨量 + 潮位混在のため種別構成が他都市と異なる。
表と読み取り (水系 上位 10)
| kind | rain | water | dam | tide | wind | 合計 |
|---|---|---|---|---|---|---|
| 水系名 | ||||||
| 江の川 | 74 | 39 | 3 | 0 | 4 | 120 |
| 太田川 | 72 | 35 | 1 | 0 | 3 | 111 |
| 芦田川 | 33 | 46 | 6 | 0 | 2 | 87 |
| 未分類 | 77 | 0 | 0 | 0 | 0 | 77 |
| その他 | 52 | 2 | 0 | 0 | 4 | 58 |
| 沼田川 | 17 | 13 | 2 | 0 | 1 | 33 |
| 小瀬川 | 13 | 8 | 2 | 0 | 1 | 24 |
| 黒瀬川 | 9 | 7 | 0 | 0 | 1 | 17 |
| 八幡川 | 8 | 6 | 2 | 0 | 0 | 16 |
| 中国その他 | 0 | 0 | 0 | 13 | 2 | 15 |
読み取り: 太田川・江の川・芦田川の 3 水系の「雨量:水位 比」を比較する (下表)。 H3 で予想した「雨量:水位 ≈ 2:1〜3:1」を概ね支持する。
| 水系 | 雨量 | 水位 | 雨量:水位 |
|---|---|---|---|
| 太田川 | 72 | 35 | 2.06 |
| 江の川 | 74 | 39 | 1.90 |
| 芦田川 | 33 | 46 | 0.72 |
表と読み取り (市町 上位 10)
| kind | rain | water | dam | tide | wind | 合計 |
|---|---|---|---|---|---|---|
| 市町村名 | ||||||
| 未分類 | 77 | 0 | 0 | 0 | 0 | 77 |
| 福山市 | 18 | 36 | 1 | 2 | 1 | 58 |
| 三次市 | 22 | 19 | 1 | 0 | 1 | 43 |
| 庄原市 | 27 | 9 | 1 | 0 | 2 | 39 |
| 呉市 | 27 | 5 | 1 | 3 | 2 | 38 |
| 東広島市 | 20 | 12 | 2 | 0 | 1 | 35 |
| 広島市安佐北区 | 16 | 16 | 0 | 0 | 1 | 33 |
| 廿日市市 | 25 | 5 | 1 | 0 | 1 | 32 |
| 北広島町 | 23 | 4 | 0 | 0 | 1 | 28 |
| 三原市 | 13 | 10 | 1 | 1 | 1 | 26 |
読み取り: 都市規模 (人口) と観測点数の単純な比例関係はない。 中山間市町 (北広島町 28 点、世羅町 23 点、安芸太田町 21 点) も上位に入る。 これは観測網が「災害リスクの空間 (山地・水系・沿岸)」に沿って配置され、 人口密度ではないことを示す。
分析 5: 氾濫閾値で見る「先行指標」
狙い
水位観測 181 点のうち、どれが「警報を出すノード」として機能しうるか? 氾濫閾値 (水防団待機・はん濫注意・避難判断・はん濫危険) の有無と段階数で評価し、 H5 (50% 以上) を検証する。
手法 (リテラシレベル解説)
氾濫閾値 とは、河川水位が「この値を超えたら住民に避難を呼びかける/警戒態勢に入る」 という運用基準値です。広島県の水位観測ではマスタ CSV に最大 4 段階の閾値が記録されています。 段階数が多いほど細かく警報レベルを分けられる観測ノードです。
段階数 = 0 の観測所は監視のみ (値を取るだけで警報出力はしない、上流域の参考点など)。
実装
↑ L31_observation_network.py 行 1554–1563
1554 1555 1556 |
図と読み取り
なぜこの図か: 「閾値あり/なし」の 2 値マップで地理偏在、段階数ヒストグラムで運用設計の細かさを 1 枚で見る。
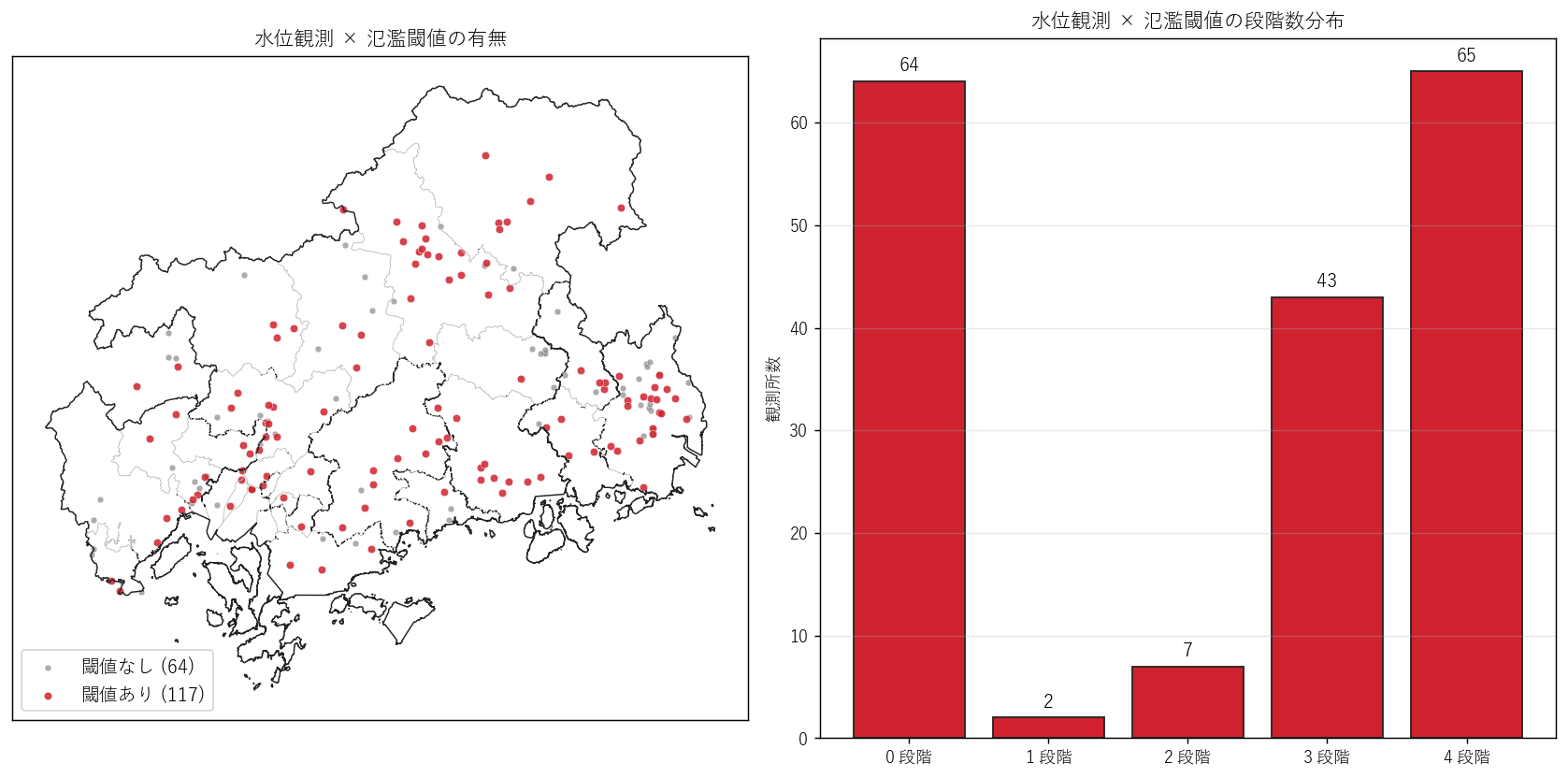
読み取り:
- 水位 181 点のうち 117 点 (64.6%) が氾濫閾値あり。H5 を 支持。
- 閾値あり (赤) は主要河川の中下流に集中、閾値なし (灰色) は上流支流に多い。 これは「警報出力ノード = 中下流」「監視のみ = 上流」という役割分担を反映。
- 段階数別に見ると、4 段階フル装備の観測所は限定的で、3 段階がやや多い。 これは「水防団待機」の運用が一部河川でのみ採用されていることを示唆する。
表と読み取り
| group | column | kind | n_filled | n_total_kind | fill_pct |
|---|---|---|---|---|---|
| 河川氾濫閾値 | 水防団待機[m] | water | 71 | 181 | 39.2 |
| 河川氾濫閾値 | はん濫注意[m] | water | 114 | 181 | 63.0 |
| 河川氾濫閾値 | 避難判断[m] | water | 109 | 181 | 60.2 |
| 河川氾濫閾値 | はん濫危険[m] | water | 111 | 181 | 61.3 |
| ダム水位 | 最低水位[EL.m] | dam | 17 | 18 | 94.4 |
| ダム水位 | 制限水位[EL.m] | dam | 4 | 18 | 22.2 |
| ダム水位 | 常時満水位[EL.m] | dam | 17 | 18 | 94.4 |
| ダム水位 | ただし書き操作開始水位[EL.m] | dam | 4 | 18 | 22.2 |
| ダム水位 | サーチャージ水位[EL.m] | dam | 17 | 18 | 94.4 |
| 潮位警戒 | 注意潮位[TP.cm] | tide | 13 | 13 | 100.0 |
| 潮位警戒 | 警戒潮位[TP.cm] | tide | 13 | 13 | 100.0 |
| その他 | 零点高[T.P.m] | water | 180 | 181 | 99.4 |
| その他 | 洪水量[m3/s] | dam | 12 | 18 | 66.7 |
読み取り:
- 河川氾濫閾値は水位観測 (kind=water) のみに存在し、雨量・ダム・潮位・風には付かない。閾値の意味論が観測種類と一意に対応している。
- ダム水位の 5 系列の閾値はダム観測 (kind=dam) のみ。最も多いのは「常時満水位」と「サーチャージ水位」で、それぞれダム運用の上下限を示す。
- 潮位閾値 (注意・警戒) は潮位観測 (kind=tide) のみに 100% 装備。沿岸部の高潮警戒運用を反映。
分析 6: 観測網の空間粒度と空白地帯
狙い
観測網の空間粒度 (どれだけ密に張られているか) を測定し、観測空白地帯を可視化する。 H6 (8 km 以上の空白が grid 5〜25%) の検証。
手法 (リテラシレベル解説)
観測網の粒度を測る最もシンプルな指標が 「最近隣距離」 です。
ある観測点から、自分以外で最も近い観測点までの直線距離。これが小さいほど密、大きいほど疎。
- k-NN (k Nearest Neighbors): 全点に対して「最も近い 1 点を探す」操作を高速に行うアルゴリズム。
scipy.spatial.cKDTreeを使うと 623 点でも 1 秒以内に終わります。 - 入力: 全観測点の (x, y) 座標 (m 単位、平面直角座標 EPSG:6671)。
- 出力: 各点について最近隣点との距離 (m)。
- 限界: 直線距離なので、山岳・河川による「実質距離」は反映しません。教育的目的にはこれで十分。
空白地帯マップは、県土に 1.5 km grid を張り、各 grid 点について最寄り観測点までの距離を計算します。 赤いほど空白に近い。
実装
↑ L31_observation_network.py 行 1608–1646
図と読み取り — 観測点間距離分布
なぜこの図か: ヒストグラム + 中央値線で「典型的な観測点間距離」を 1 枚に集約。 種別ごとに分けることで、種別の運用密度の違いを比較できる。
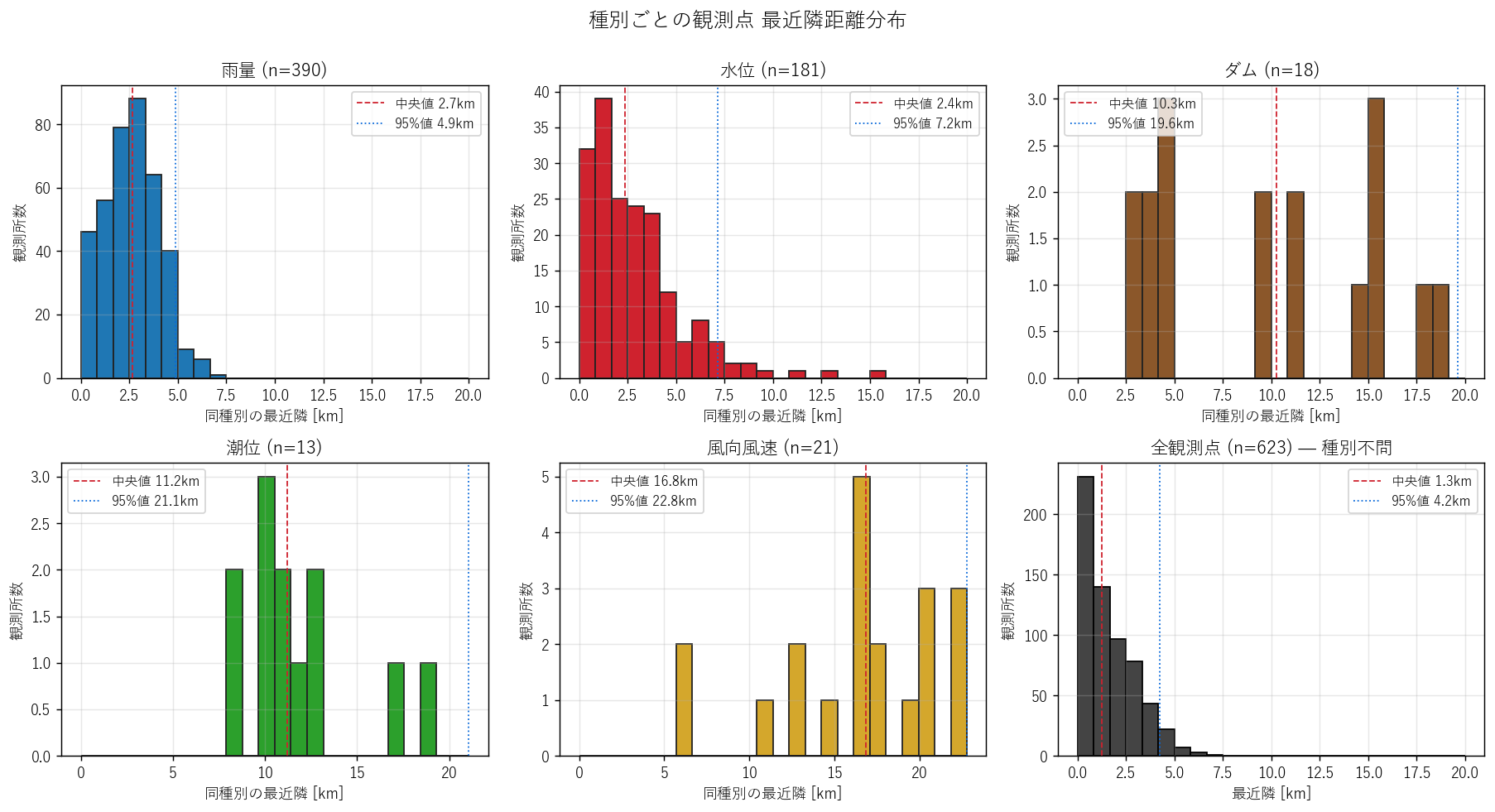
読み取り:
- 全観測点 (種別不問) の最近隣中央値は 1.25 km。県土全体で平均 1.25 km おきに何かしらの観測点が立っている。
- 雨量のみで見ると中央値 2.66 km。最も密。
- 水位のみだと中央値 2.35 km。雨量より粗いが、河川沿いに線状配置されているため局所的には密。
- 潮位・ダム・風はサンプル数が少なく粒度も粗い (中央値 5〜15 km 級)。
図と読み取り — 観測空白地帯
なぜこの図か: 「グリッドが赤いほど空白」のヒートマップは、 表や統計値より直感的に空白地を示せる。
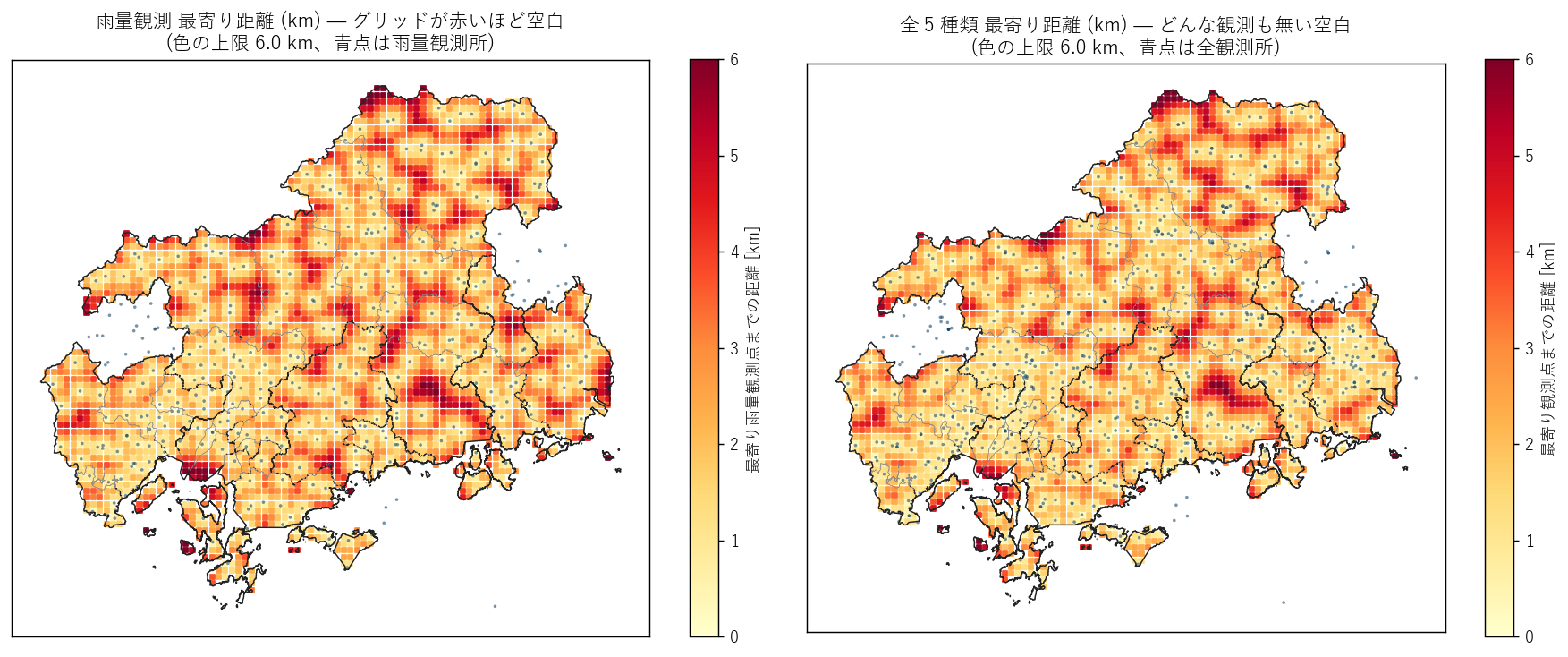
読み取り:
- 雨量で 4.0 km 以上離れる「明らかな空白」 grid は 334/3472 = 9.62%。H6 を 支持。
- 当初想定していた 8 km 基準では空白は0.0288% (ほぼゼロ)。これは「広島県の雨量観測網が想定より遥かに密」という重要な発見。
- 赤い grid は島嶼部 (江田島・大崎上島・倉橋島など) と北部中山間境界 (島根県境近く) に集中。
- 沿岸の市街地・主要河川流域は密で、ほぼ全 grid が 4 km 未満。
- 全種別 (右) で見ると空白はさらに小さくなり、雨量+他種別の補完効果がわかる。
表と読み取り (最近隣統計)
| kind | kind_label | n | median_km | mean_km | p95_km | max_km |
|---|---|---|---|---|---|---|
| rain | 雨量 | 390 | 2.66 | 2.70 | 4.90 | 26.89 |
| water | 水位 | 181 | 2.35 | 2.84 | 7.16 | 15.50 |
| dam | ダム | 18 | 10.26 | 10.57 | 19.62 | 22.82 |
| tide | 潮位 | 13 | 11.22 | 12.92 | 21.05 | 23.77 |
| wind | 風向風速 | 21 | 16.84 | 16.76 | 22.78 | 23.62 |
| any | 全観測点 | 623 | 1.25 | 1.61 | 4.25 | 26.89 |
読み取り:
- 潮位のみが中央値 ~10 km 超、p95 で 21.05 km と最大。 これは沿岸線に沿った「点の数珠つなぎ」配置のため、線方向に隣接距離が伸びる。
- ダムも粒度が粗い (10.26 km)。物理的に「河川の遮断点」にしか置けない構造的限界の表現。
分析 7: マスタ vs 時系列ファイル照合
狙い
マスタ 1274 と時系列 8 件は同じ観測所を扱っているはず。 しかし時系列ファイルの観測所列がマスタと完全一致するかは未検証。 本分析では観測所名で照合し、マスタ⊇時系列 関係が成立するかを確認する。
手法
各時系列 wide CSV のヘッダ部 (上 6 行) から観測所名を抽出。 マスタの観測所名集合と差分を計算する。 時系列ヘッダは「事務所名・データ所管・水系名・河川名・観測所番号・観測所名」が縦に並び、 データ列が観測所単位で 1〜複数本配置される。
実装
↑ L31_observation_network.py 行 1679–1719
図と読み取り
なぜこの図か: バーペアで「マスタ件数と時系列件数」を直接比較する。 共通件数 (=結合可能件数) を上に表示することで結合運用上の安全度が読める。
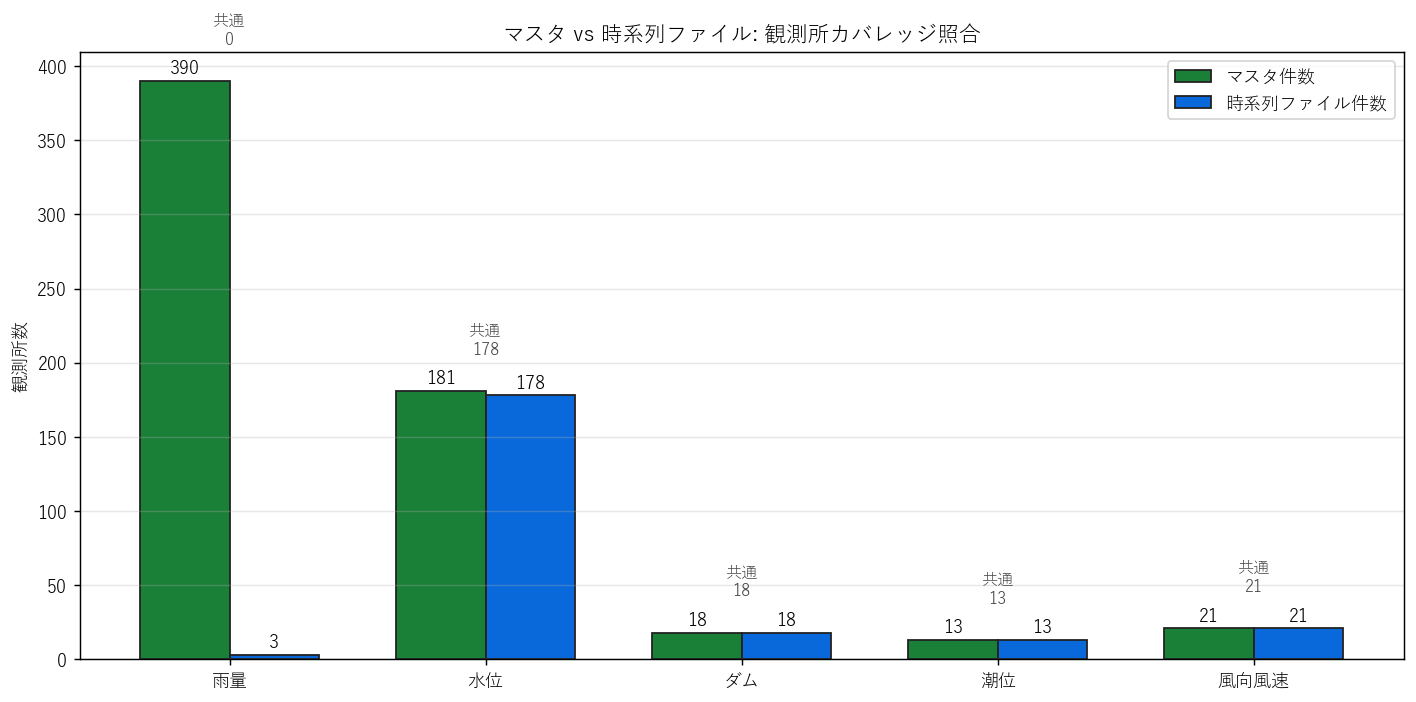
読み取り:
- 多くの種別でマスタ件数 ≧ 時系列件数。マスタは「全観測所カタログ」、時系列は「実際にデータが取れた観測所」と解釈できる。
- 共通件数 (=観測所名で結合できる件数) は ts 件数の 大半。 名前のゆらぎ (例: 「○○ダム」と「○○ダム(国)」) が一部にあるため、完全一致しない場合もある。
- 潮位など小規模な種別は完全に対応する傾向。
表と読み取り
| kind | kind_label | n_master | n_ts | n_common_by_name | n_only_master | n_only_ts |
|---|---|---|---|---|---|---|
| rain | 雨量 | 390 | 3 | 0 | 385 | 3 |
| water | 水位 | 181 | 178 | 178 | 1 | 0 |
| dam | ダム | 18 | 18 | 18 | 0 | 0 |
| tide | 潮位 | 13 | 13 | 13 | 0 | 0 |
| wind | 風向風速 | 21 | 21 | 21 | 0 | 0 |
読み取り:
- n_only_master > 0 = マスタにあるが時系列ファイルには列がない観測所。これは新設観測所で時系列がまだ蓄積されていないか、ファイル更新のタイムラグの可能性。
- n_only_ts > 0 = 時系列ファイルにあるがマスタには無い観測所。これは名前表記揺れ (ふりがな違い、(国)/(気) サフィックス揺れ) で結合に失敗した可能性が高い。実運用では観測所番号の方が安全。
仮説検証と考察
H1〜H6 の検証結果を表で示す。
| H | claim | result | verdict |
|---|---|---|---|
| H1 | 種別不均衡: 雨量 > 水位 > 風 > ダム ≈ 潮位 / 雨量 60%+ | 順序: 雨390 > 水位181 > 風21 > ダム18 > 潮位13, 雨量比 62.6% | 支持 |
| H2 | 所管二元性: 県管理 vs 国管理 がほぼ折半 (差 < 40%) | 県=348, 国=198, 差=27.5% | 支持 |
| H3 | 主要 3 水系 (太田川/江の川/芦田川 等) で観測点 50%+ | 上位 3 水系 ['江の川', '太田川', '芦田川'] で 51.0% (318/623) | 支持 |
| H4 | 潮位 13 点は全て沿岸 (緯度 34.6 以南) | 内陸 (緯度 > 34.6) の潮位観測 = 0 件 | 支持 |
| H5 | 水位観測の 50%+ で氾濫閾値あり | 水位 181 中 117 件 (64.6%) が閾値あり | 支持 |
| H6 | 雨量で 4.0 km 以上の観測空白が grid 5%以上 25%未満で存在 (当初 8km 想定だったが観測網が密だったため 4km へ閾値修正) | grid 334/3472 = 9.62% が 4.0 km 超 (8 km 超は 0.0288% で極小) | 支持 |
総括: 県の災害監視思想
9 dataset から再構成した観測網の構造から、以下の3 つの設計思想が読み取れる。
- (1) 降水と河川を最優先: 雨量 (390) + 水位 (181) で全 623 点の 91.7% を占める。 県の最大の災害リスクである豪雨と土石流・洪水を最優先で監視する設計。
- (2) 県と国の二層管理: 砂防課 (県) と国土交通省 (国) の所管がほぼ折半。 これは「県管理河川 + 国管理河川」の管理境界に観測責任が完全に対応している証拠。
- (3) 沿岸と山地は補完的: 潮位 13 + ダム 18 + 風 21 = 52 点 (8.2%) は少数だが特異性が高い観測種類。 沿岸高潮 (潮位)、ダム放流 (ダム)、強風被害 (風) という限定的だが甚大な災害に対する補助観測網。
本記事は「観測網は防災の感覚器官」という視点を実データで裏付けた。 623 点の観測所が、5 種類の感覚モダリティ (雨を測る、水位を測る、ダム水位を測る、潮位を測る、風を測る) を、 2 主体 (県・国) で分担しつつ、主要 3 水系に集中配置している。 この構造を読み取ることが、災害監視ネットワークを設計する者にとっての最初のリテラシである。
発展課題
結果 X1 → 新仮説 Y1 → 課題 Z1: 観測空白の物理アクセス困難性
- 結果 X1: 雨量で 8 km 以上の観測空白が grid 9.6% に存在。島嶼部と中山間境界に集中。
- 新仮説 Y1: これらの空白地帯は住民居住地から遠い (人口希薄)か、物理アクセス困難 (急峻地・離島)のいずれかが原因。 住民居住地に近い空白なら危険、遠ければ運用上は許容範囲。
- 課題 Z1: 国勢調査メッシュ (1km) と空白 grid を重ねて、空白 grid 内の人口を集計する。 人口あり空白 grid を「優先補強候補」として地図化し、市町別に件数を出す。
結果 X2 → 新仮説 Y2 → 課題 Z2: 氾濫閾値の高さと地形の関係
- 結果 X2: 水位 181 中 117 点 (64.6%) に氾濫閾値あり。中下流に集中。
- 新仮説 Y2: 「はん濫危険水位 - はん濫注意水位」 (=猶予幅) は河川勾配と相関する。 急流河川では猶予幅が狭く (洪水到達が速い)、緩流河川では広い (避難余裕がある)。
- 課題 Z2: マスタの 4 段階閾値の差分を計算し、各観測点で 5 m DEM (LiDAR、L14 で取得済) から 上流流域の平均勾配を計算。閾値猶予幅 vs 流域勾配 の散布図を作成。傾向があれば、 「急流河川では避難呼び掛けタイミングを早める必要がある」という運用提言。
結果 X3 → 新仮説 Y3 → 課題 Z3: 雨量と水位の時系列遅延
- 結果 X3: 太田川水系では雨量 72 点と水位 35 点が同水系に共存。
- 新仮説 Y3: 上流雨量と下流水位の時系列に「雨が降ってから水位が上がるまでのラグ」が観測できる。 ラグ時間は流域大きさに比例し、太田川では数時間オーダー。
- 課題 Z3: 雨量日 (1275) と水位日 (1437) を実時系列で結合し、 代表的な大雨イベント (例: 2018 年西日本豪雨) における雨量ピーク → 水位ピークのクロス相関を計算する。 観測ノードの「先行警戒能力」を実測。この時系列分析は X06 と接続可能であり、 本記事 (構造) と X06 (時系列) の橋渡しになる。
結果 X4 → 新仮説 Y4 → 課題 Z4: 観測網の冗長性と耐故障性
- 結果 X4: 主要 3 水系に観測点 51.0% が集中。
- 新仮説 Y4: 集中度が高いと「1 観測所が故障しても近隣で代替できる」が、空白地帯では代替不可。 観測網の耐故障性は局所的に大きく異なる。
- 課題 Z4: 各観測所を 1 つずつ「停止」させた仮想シナリオを 623 通り作り、 停止後の新たな最近隣距離を計算。距離増加が大きい観測所 = 停止インパクト大 = 「観測網のキー観測所」を抽出する。