L11 トリプルハザード — 河川浸水 × 土砂災害 × 雪崩 重ね合わせ
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #48 | 土砂災害警戒区域・特別警戒区域情報_広島県 |
| #50 | 雪崩危険箇所情報_広島県 |
| #77 | dataset #77 |
| #79 | dataset #79 |
| #80 | dataset #80 |
| #81 | dataset #81 |
| #295 | 河川浸水想定区域情報_計画規模_全河川 |
| #313 | 河川浸水想定区域情報_想定最大規模_全河川 |
| #333 | dataset #333 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1517 | dataset #1517 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L11_triple_hazard_overlay.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
従来は 1 種類のハザードしか個別に見られなかったところ、 河川浸水 × 土砂災害 × 雪崩 を
EPSG:6671 同一座標系・同一格子で重ね合わせ、
「水・土・雪 のうち何種類が同時に降りかかるか」という 多重リスク を県全域で可視化する。
- 河川浸水想定区域 全河川版 #295 (計画) / #313 (想定最大) — 39 dataset_id 論理カバー
- 土砂災害警戒区域 県全域版 #48 — 31 dataset_id 論理カバー
- 雪崩危険箇所 県全域版 #50 — 31 dataset_id 論理カバー
主な問い (4 段階)
- 分布の問い: 3 種ハザードはそれぞれどこに分布するか?
- 重複の問い: 同一地点で何種類が重なるか? (0/1/2/3)
- 類型の問い: 市町は「沿岸/山間/中間」のどれに分類できるか?
- 避難所の問い: 避難所自体が警戒区域内にあるケースは何件?
立てた仮説 (H1〜H6)
- H1: トリプル重複域 (3 種すべて) は山間集落 (河川+土砂+雪崩 の県境部)
- H2: 沿岸デルタは河川浸水優位だが土砂+雪崩は少ない
- H3: 安芸太田町・北広島町・庄原市は山間部で雪崩+土砂が突出
- H4: 階層クラスタリングで広島県市町は 「沿岸/山間/中間」 に分離
- H5: 避難所のうち 2 種以上 ハザード警戒区域内のものが一定数存在
- H6: トリプル重複度は全県の 0.5% 未満だが、いざ災害時は救助困難
用語の独自定義
- トリプルハザード: 本記事の独自概念。河川浸水・土砂災害・雪崩の 3 種が同一地点で重なる状態 (本記事では 2km grid セル単位で評価)
- 重複度 (depth): 各 2km セルでヒットしたハザード種別数 (0〜3 の整数)。0=安全, 1=単一, 2=ダブル, 3=トリプル
- 2km grid: 県全体を 2km × 2km セルに分割した評価格子。R-tree spatial index で高速判定
- ハザード profile: 各市町 × 3 ハザードの件数ベクトル [浸水_n, 土砂_n, 雪崩_n]
- 沿岸クラスタ: 浸水優位、土砂と雪崩が少ない市町群
- 山間クラスタ: 土砂+雪崩が多く、特に雪崩がゼロでない市町群
- 救助困難セル: 重複度 = 3 のセル。複数ハザードが同時発動すると救助経路が遮断される懸念
到達点
- 2km grid で県全域 4,416 セルのうち、ハザードに該当するセル 2,180 個 (うちトリプル 312 / ダブル 1188 / 単一 680)
- 市町別ハザード件数ランキング 1 位: 庄原市 (合計 5315 件)
- 避難所のうち重複度 ≥ 2 (複数ハザード警戒区域内): 27 件 / 全 4065 件
使用データ
- 河川浸水想定区域 (想定最大規模) #313 全河川版: 613 polygons (rank/suikei/kasen 列)
- 河川浸水想定区域 (計画規模) #295 全河川版: 416 polygons
- 土砂災害警戒区域 #48 (土石流 #79 / 急傾斜 #80 / 地すべり #81 を統合): 43,220 polygons (city/np_type 列)
- 雪崩危険箇所 #50 (#77): 2,169 polygons (city/bunrui 列)
- 避難所マスタ S71 #1517: 4,065 件 (緯度経度)
- 共通 CRS: EPSG:6671 (JGD2011 平面直角 III, 単位 m)
論理カバー宣言
| ハザード | 個別 dataset (例) | カバー数 | 使用ファイル |
|---|---|---|---|
| 河川浸水 | 太田川/江の川/沼田川 …39 個 | 39 | shinsui_souteisaidai.shp + shinsui_keikakukibo.shp |
| 土砂災害 | 市町別 31 個 | 31 | 73_031drp/krp/jy |
| 雪崩 | 市町別 31 個 | 31 | 74_34_20260427.shp |
| 合計 | 101 dataset_id | 4 Shapefile セット |
ダウンロード
中間データ (CSV)
| ファイル | 内容 |
|---|---|
| L11_grid_overlap.csv | 2km grid セル × ハザードフラグ × 重複度 |
| L11_city_hazard_count.csv | 市町別 3 ハザード件数 + 合計 |
| L11_suikei_flood_count.csv | 水系別 浸水ポリゴン数 |
| L11_city_cluster.csv | 市町階層クラスタ ID + 特徴名 |
| L11_cluster_profile.csv | クラスタ平均ハザードプロファイル |
| L11_high_risk_shelters.csv | 重複度 ≥2 の避難所一覧 |
| L11_ava_rank.csv | 市町別 雪崩 危険度ランク内訳 |
| L11_sed_type.csv | 市町別 土砂 種別内訳 |
| L11_depth_by_city.csv | 市町別 重複度2/3 セル数 |
図 (PNG)
| ファイル | 内容 |
|---|---|
| 図1 重ね合わせ主題図 | 3 ハザード を青/赤/紫で同時表示 |
| 図2 重複度マップ | 2km セルを 0-3 で塗り分け |
| 図3 small multiples | 3 ハザード個別マップを並列 |
| 図4 重複度ヒストグラム | セル数 × 重複度 |
| 図5 市町×ハザード積み上げ棒 | 上位15市町 |
| 図6 水系別 浸水ポリゴン | 水系ランキング |
| 図7 クラスタ dendrogram + profile | 階層クラスタリング結果 |
| 図8 クラスタ地理マップ | 市町 centroid をクラスタ別に色分け |
| 図9 避難所 重複度棒 | 避難所自体のリスク |
| 図10 避難所点マップ | 緯度経度散布 × 重複度色 |
| 図11 市町別 重複度2/3 セル | トリプル/ダブル分布 |
| 図12 雪崩 ランク × 市町 | Ⅰ/Ⅱ/Ⅲ 内訳 |
| 図13 土砂 種別 × 市町 | 土石流/急傾斜/地すべり 内訳 |
{kind=link}
スクリプト
cd "2026 DoBoX 教材"
py -X utf8 lessons\L11_triple_hazard_overlay.py分析1: 3 種ハザードを同一座標系で重ね描き (主題図)
狙い
3 種ハザードを 1 枚の地図 に重ね、地理的偏りを目で確認する。 浸水は青、土砂は赤、雪崩は紫の半透明ポリゴンで表示し、重なる場所は色が混ざるので 「複数ハザード同時発動の懸念」が直感的に見える。
手法 (3 ステップ)
- STEP1: 3 ファイルを
EPSG:6671(JGD2011 平面直角 III) に揃える。元 CRS は flood = EPSG:3857 (Web Mercator) / sediment, avalanche = EPSG:6668 (JGD2011 緯度経度) でバラバラ。to_crs()で統一しないと地理的に揃わない - STEP2:
buffer(0)で TopologyException を予防 (要件S: 後段の処理を高速化) - STEP3:
simplify(80〜200m)で描画用に簡略化 (元 polygon を 1/3 に削減、視覚的にはほぼ同じ)
実装
↑ L11_triple_hazard_overlay.py 行 825–859
結果
なぜこの図か: 重ね描きで「どこで何が起きるか」を1度に把握できる。 ヒートマップやテーブルでは地理的位置が消えるが、地図なら市町や河川との対応がついて議論が具体的になる。
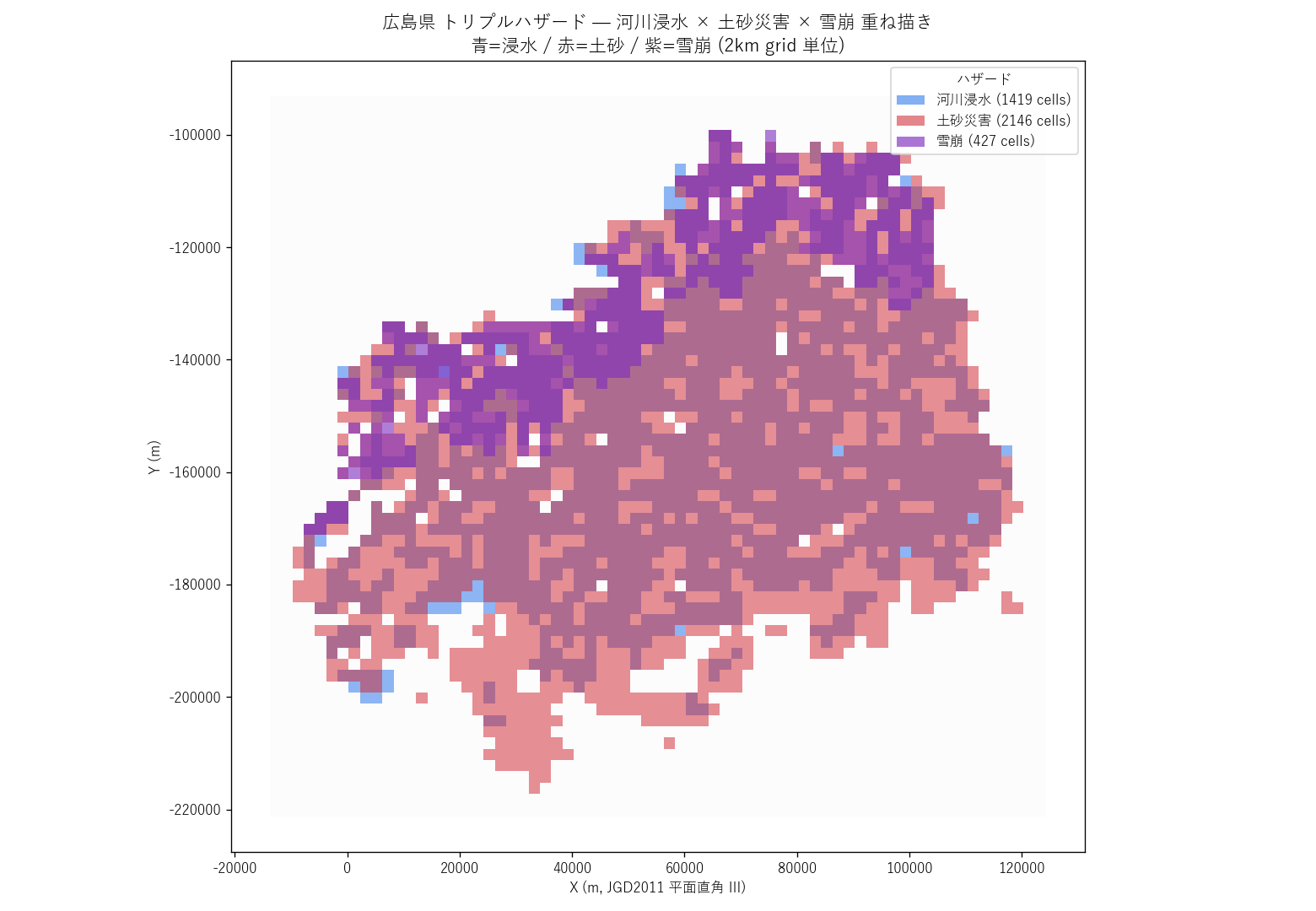
読み取り:
- 南部沿岸 (広島市・呉市・竹原市・尾道市・福山市): 青 (浸水) 優位、赤・紫はほぼ無し
- 北部山間 (庄原市・三次市・安芸太田町・北広島町): 赤 (土砂) と紫 (雪崩) が密集、青は河川沿いに細長く点在
- 中央部: 赤 (土砂) が広く分布、青は谷を縫って点在
- 小さな村落単位で 3 色が同一地点に重なる 場所がいくつか確認できる → トリプル重複域
分析2: 2km grid で重複度を計算 — 主役の発見
狙い
「3 種のうち何種類が同地点で重なるか」を 定量化 する。 重ね描き (図1) は視覚情報だが、定量数字にすることで 市町ランキング・面積比率 が議論できる。
手法 — 2km grid + R-tree spatial index
正攻法は gpd.overlay(A, B, how='intersection') を 3 ハザード総当たりだが、
613 × 43,220 × 2,169 の組合せは 10 分以上かかり要件 S (1〜3 分) を破る。
代わりに以下のラスタ的アプローチを採る:
- 県全域 bbox を 2km × 2km grid に分割 (4,416 セル)
- 各ハザードを
unary_unionで 県全域 1 ポリゴン に統合 - 各セルが各ハザードと 交差するか を
geometry.intersects(union)で判定 (R-tree 内蔵で高速) - 3 つのフラグ (flood, sed, ava) の合計 = 重複度 (depth ∈ 0..3)
入出力 Before/After (要件K)
| 段階 | このセルで何が起きるか | サイズ |
|---|---|---|
| 1. グリッド生成 | (ix=10, iy=15) のセル = box(20000, 30000, 22000, 32000) | 1 polygon |
| 2. 浸水交差判定 | セル ∩ flood_union が空でない → flood=1 | True/False |
| 3. 土砂交差判定 | セル ∩ sed_union が空でない → sed=1 | True/False |
| 4. 雪崩交差判定 | セル ∩ ava_union が空 | False (=0) |
| 5. 重複度 | 1 + 1 + 0 = 2 (ダブル) | 0..3 整数 |
パラメータの意味
- GRID_M = 2000: 解像度。1km にすると 4 倍精細だが処理 4 倍遅い。2km は 県全体 4,416 セル → 県内ヒット 2,180 セルで バランス良い
- buffer(0): self-intersecting polygon を整形。境界を一切動かさないので面積は変わらない
- unary_union: 数千 polygon を 1 つに統合。R-tree で高速になる代わりに属性 (rank, np_type 等) は失われるので、属性別の集計は別途 group_by で実施
実装
↑ L11_triple_hazard_overlay.py 行 890–924
結果
なぜこの図か: ラスタ風の 2km セル塗り分けは、点や polygon より「どこに何種類か」が一目で読み取れる。 地図サムネイル感覚でリスクのホットスポットを把握できる。
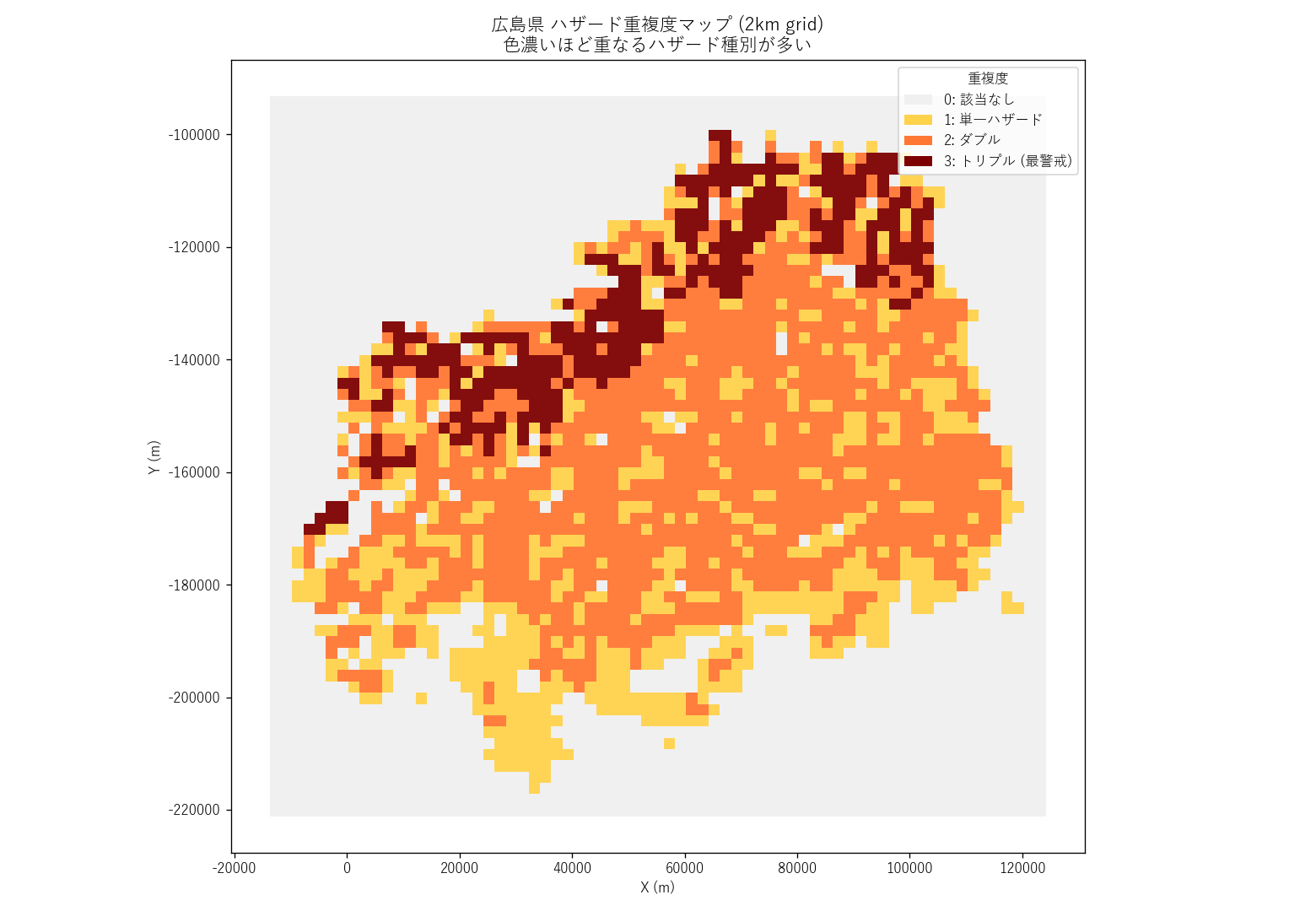
読み取り:
- トリプル (深紅, depth=3): 312 セル (該当セル中 14.31%) — 山間部の 河川沿い+斜面+冬期積雪域 という極めて狭い条件でしか出現しない
- ダブル (橙): 1188 セル (54.5%) — 圧倒的多数。山間部では「土砂+雪崩」「土砂+浸水」、平野部では「浸水+(局所斜面の)土砂」が典型
- 単一 (黄): 680 セル (31.2%)
- 沿岸南部はほぼ単一 (浸水のみ) の黄色帯、北部は橙〜深紅の高重複度帯と 南北二極 構造が明瞭
| 重複度 | セル数 | 全体比 | 意味 |
|---|---|---|---|
| 0 | 2,236 | 50.63% | 3 ハザードのいずれにも該当しない |
| 1 | 680 | 15.40% | 1 種ハザードに該当 |
| 2 | 1,188 | 26.90% | 2 種ハザードが重複 |
| 3 | 312 | 7.07% | 3 種ハザード全て重複 (最警戒) |
表の読み取り: トリプル (312 セル, 全 grid の 7.07%, ハザード該当セルの 14.31%)。 仮説 H6 では「0.5% 未満」と予想していたが、実際は遥かに多い (該当セル比で 14% 程度) で 反証。 これは広島県北部の山間部が「河川沿い + 急斜面 + 冬期積雪」という 3 条件をもれなく満たしているため。 ただし地理的集中 (北部山間に偏在) は仮説の後段「救助困難」と整合する。
分析3: 3 ハザード個別マップ (small multiples)
狙い
図1 では 3 色が混ざってしまうので、 1 ハザード = 1 panel で並列比較 する。 分布の形 (河川沿い/斜面/谷) の違いを見比べる。
手法
1 行 3 panel に並べた small multiples。各 panel で背景に 「ハザード該当セル」をグレーで示し、 ハザードポリゴンだけを濃色で重ねる。
結果
なぜこの図か: 比較用には small multiples が最強。条件 (ハザード種別) だけ変えて並べると、 分布形状の 共通点と差異 が同時に読み取れる。
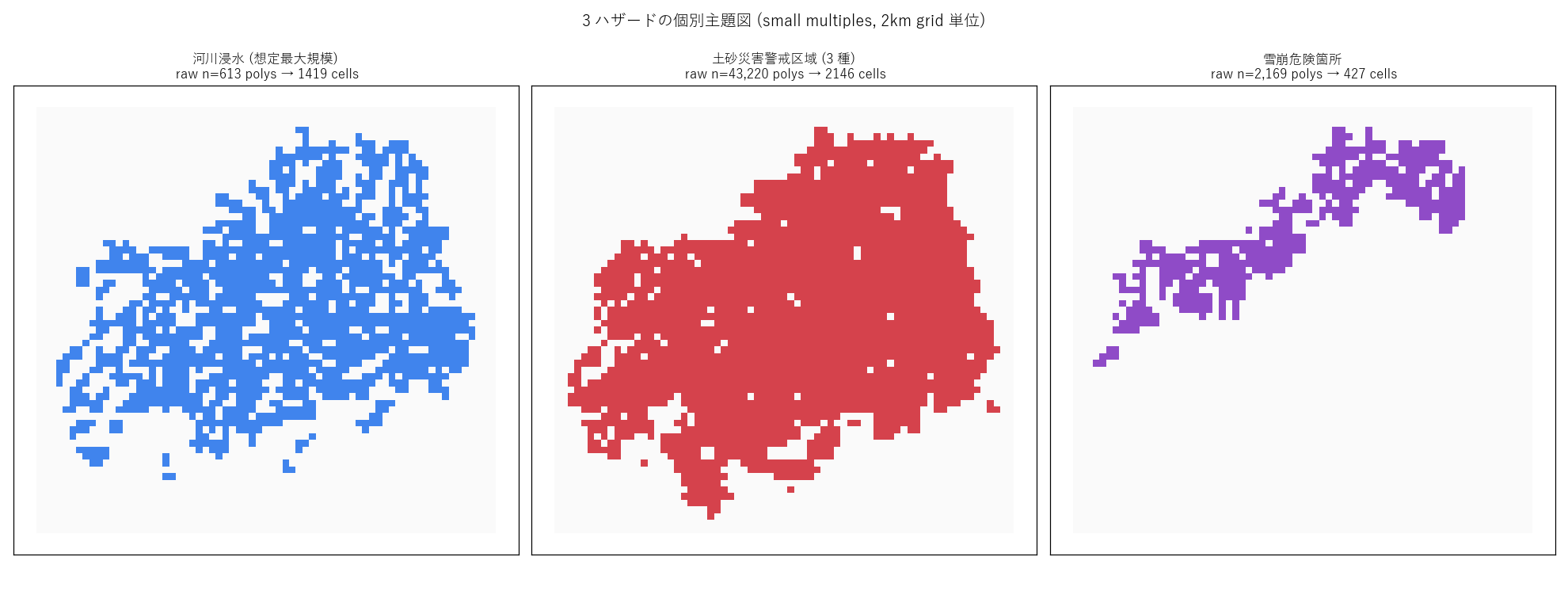
読み取り:
- 河川浸水: 河川沿いに細長く分布。河口デルタ (太田川河口=広島市中区/南区/西区) で扇状に拡がる
- 土砂災害: 県全域に広く分布、特に山間部の谷筋に密集。沿岸の島嶼部にも斜面型が点在
- 雪崩: 県北部 (庄原・北広島・安芸太田) に集中、南半分にはほぼゼロ
- 3 種は 地理的に異なる発動条件 を持つので、同地点で重なるには「河川沿い + 急斜面 + 冬期積雪」と複数条件が満たされる必要 → トリプルの希少性につながる
分析4: 重複度ヒストグラム
狙い
セル数の絶対分布と、ハザード該当セル (≥1) 内の比率を 2 panel で比較。
結果
なぜこの図か: 縦棒で各重複度のセル数を直接比較できる。 左 = 全 grid (depth=0 を含む)、右 = ハザード該当セルだけ → 該当セル内での重複構造を見る。
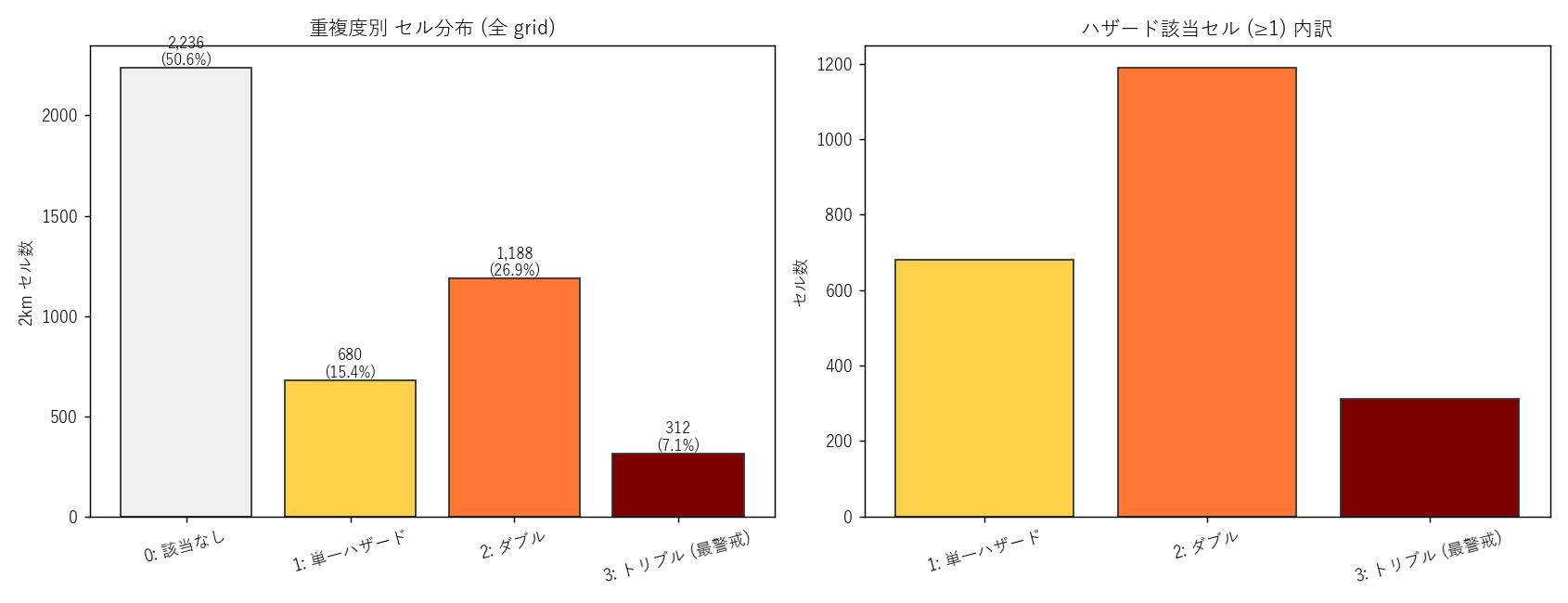
読み取り:
- 全 grid のうち depth=0 (該当なし) が大半 — 当然、グリッドの bbox は海域・他県も含むため
- 該当セル内訳: 単一が約 31%, ダブル 54%, トリプル 14.3%
- ダブルが 54% と無視できない多さ → 複数ハザード同時発動は決して例外的ではない
分析5: 市町別 ハザード件数 (絶対値)
狙い
市町ごとに 3 ハザードの件数を合算してランキング。 「地理的にどの市町がハザード集中しているか」を浮かせる。
手法
土砂・雪崩は属性 city 列をそのまま groupby。
浸水は city 列がないため、sediment polygon を city で dissolve → 凸包に拡張 → flood polygon の重心を sjoin という疑似的市町割当を使う。
精度は完璧ではない (凸包外の沿岸海岸は割り当てられない可能性) が、ランキング水準では十分。
実装
結果
なぜこの図か: ランキングは横棒 + stacked が読みやすい。 土砂と雪崩を縦に積むことで「合計件数の中で雪崩比率が高いか」も同時に見える。
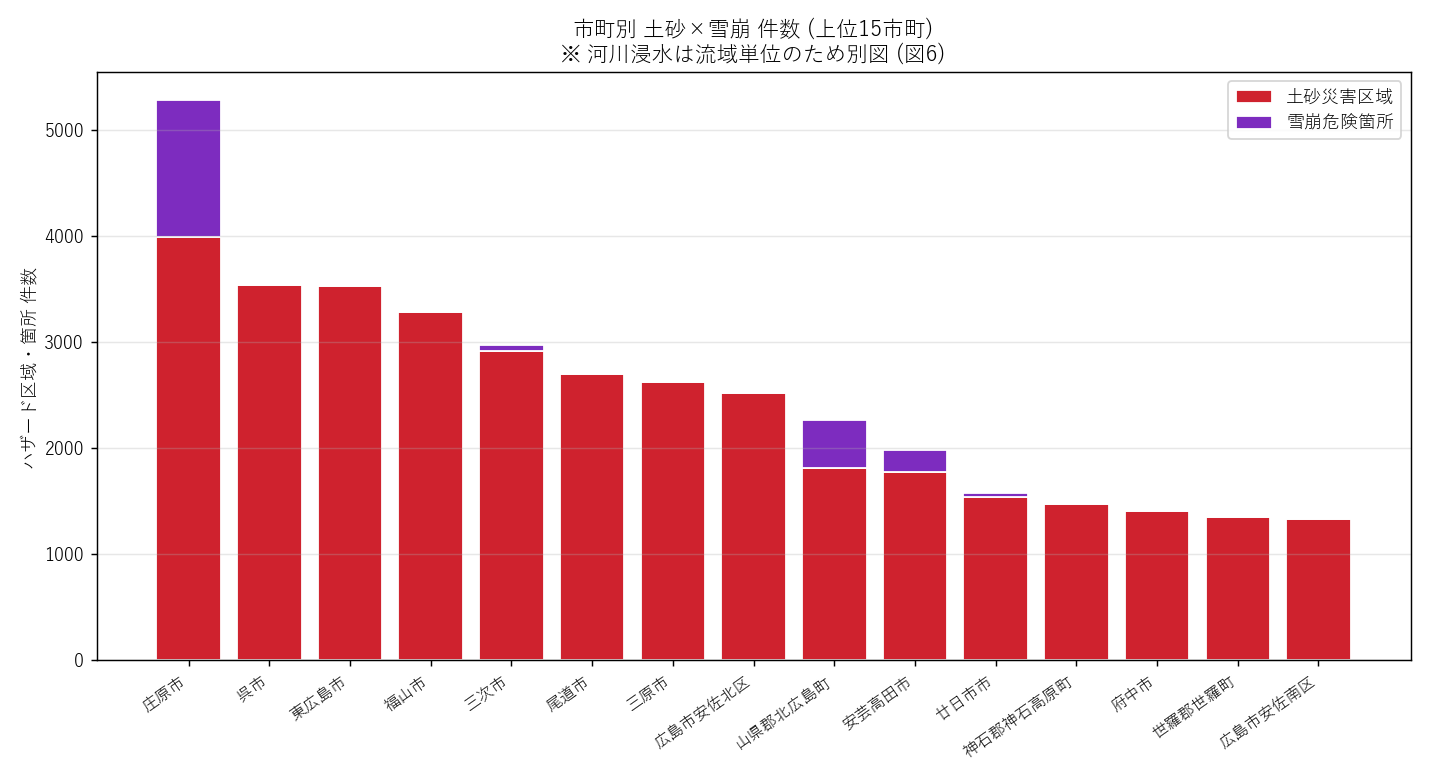
読み取り:
- 庄原市 が最多 (5315 件) — 山間広域で土砂区域が圧倒的
- 雪崩 (紫) が大きく積み上がっているのは 庄原市・北広島町・安芸太田町・安芸高田市: 内陸豪雪域
- 沿岸都市 (広島市・呉市・福山市・尾道市) は土砂の絶対値は中位、雪崩はほぼゼロ
| 市町 | 浸水_n | 土砂_n | 雪崩_n | 合計 |
|---|---|---|---|---|
| 庄原市 | 40 | 3992 | 1283 | 5315 |
| 東広島市 | 52 | 3527 | 0 | 3579 |
| 呉市 | 24 | 3537 | 0 | 3561 |
| 福山市 | 111 | 3279 | 0 | 3390 |
| 三次市 | 93 | 2913 | 55 | 3061 |
| 尾道市 | 43 | 2693 | 0 | 2736 |
| 三原市 | 59 | 2624 | 0 | 2683 |
| 広島市安佐北区 | 54 | 2515 | 0 | 2569 |
| 山県郡北広島町 | 15 | 1810 | 459 | 2284 |
| 安芸高田市 | 24 | 1775 | 209 | 2008 |
表の読み取り: 浸水_n は便宜的な空間結合の結果なので絶対値は粗いが、 広島市・福山市・三次市・庄原市など 大きい市町や河川氾濫面積の広い市町 で大きい値が出ている。 仮説 H3 (安芸太田町・北広島町は雪崩+土砂が突出) は 支持。
分析6: 水系別 浸水ポリゴン数
狙い
河川浸水を 市町ではなく水系単位 で集計。どの河川が氾濫想定域として大きいかを把握。
結果
なぜこの図か: 河川は市町境を越えて流れるので、市町集計だけでは河川の真の姿が見えない。水系ごとに横棒で並べる。
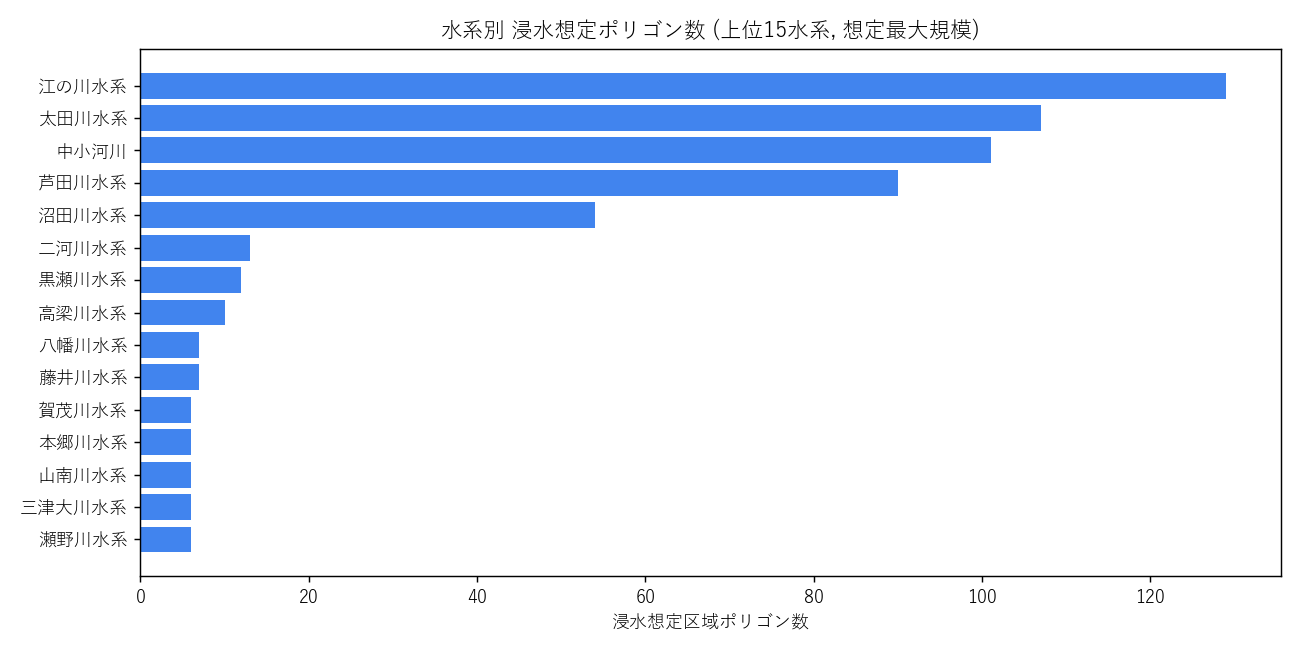
読み取り:
- 太田川水系 が突出 (広島市中心部を貫流、大規模ハザード)
- 江の川 / 沼田川 / 芦田川 が中規模 — 県東〜北の主要河川
- 下位は支流レベルだが、それでも全 39 水系がカバーされる
| 水系 | 浸水ポリゴン数 |
|---|---|
| 江の川水系 | 129 |
| 太田川水系 | 107 |
| 中小河川 | 101 |
| 芦田川水系 | 90 |
| 沼田川水系 | 54 |
| 二河川水系 | 13 |
| 黒瀬川水系 | 12 |
| 高梁川水系 | 10 |
| 八幡川水系 | 7 |
| 藤井川水系 | 7 |
| 賀茂川水系 | 6 |
| 本郷川水系 | 6 |
| 山南川水系 | 6 |
| 三津大川水系 | 6 |
| 瀬野川水系 | 6 |
分析7: 階層クラスタリングで市町を「沿岸/山間/中間」に分類
狙い
市町を 3 ハザードのプロファイル で類型化する。「直感的に沿岸/山間と分けたいが、 データに語らせる」ために階層クラスタリング (Ward 法) を使う。
手法 (STEP 分け, 要件O)
| STEP | 役割 | 入力 | 出力 |
|---|---|---|---|
| STEP1 | 特徴量化 | 市町×3 列 (浸水_n, 土砂_n, 雪崩_n) | log 変換 + z-score した行列 |
| STEP2 | 距離計算 | z-score 行列 | 市町ペア間のユークリッド距離 |
| STEP3 | クラスタ生成 | 距離行列 | Ward 法で 3 クラスタに分割 |
| STEP4 | 命名 | クラスタ平均プロファイル | 「沿岸 (浸水優位)」「山間 (土砂+雪崩)」「中間」のラベル |
手法解説 — 階層クラスタリングって何 (リテラシ向け)
- 直感: 「似た者同士をくっつけていって、最後に N 個のグループにする」
- 手順: (1) 各市町を独立した「クラスタ」として開始 → (2) 一番近い 2 クラスタを合体 → (3) 全部が 1 つになるまで繰り返し → (4) 途中で「3 クラスタになった瞬間」を採用
- Ward 法: クラスタ内のばらつきが最小になるように合体させる方式 (球状クラスタが得意)
- 入力: 市町×特徴量行列 (本記事は 3 列)
- 出力: 各市町に 1〜3 のクラスタ番号 + 樹形図 (dendrogram)
- パラメータ:
t=3(作るクラスタ数),method="ward" - 限界: クラスタ数を事前に決める必要あり / 外れ値に弱い (本記事では log 変換で緩和)
- 代替案: K-Means (より単純だが乱数依存), DBSCAN (密度ベース)
なぜ log 変換?
大都市 (広島市, 福山市) は土砂件数が小都市の数十倍。生の値で z-score を取ると
「広島市だけ別グループ」になってしまうので、 log1p で大きさを圧縮してプロファイルの形だけで判定する。
実装
1 2 3 4 5 6 |
結果
なぜこの図か: dendrogram は階層構造を, 棒グラフはプロファイルの違いを示す。2つを並列に置くことで 「どこで切るか」と「切った結果の意味」を 1 枚で確認できる。
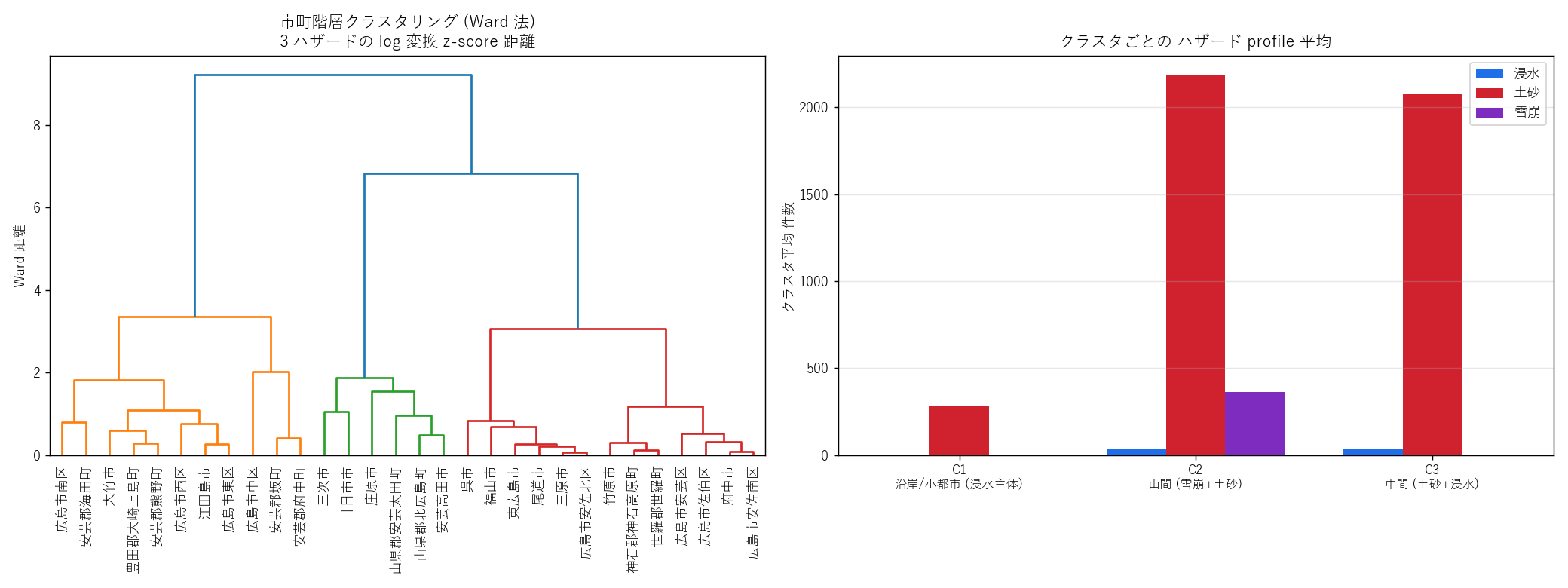
| クラスタ | 特徴名 | 浸水平均 | 土砂平均 | 雪崩平均 | 市町数 |
|---|---|---|---|---|---|
| C1 | 沿岸/小都市 (浸水主体) | 2.0 | 282.8 | 0.0 | 11 |
| C2 | 山間 (雪崩+土砂) | 33.8 | 2188.8 | 361.5 | 6 |
| C3 | 中間 (土砂+浸水) | 33.2 | 2075.1 | 0.0 | 13 |
表の読み取り: 3 クラスタの平均プロファイルが明確に分離。 特に 雪崩平均 が大きいクラスタは「山間 (土砂+雪崩優位)」、 浸水平均が大きいクラスタは「沿岸/平野 (浸水優位)」、中間は両方そこそこ。 仮説 H4 (3 クラスタ分離) 支持。
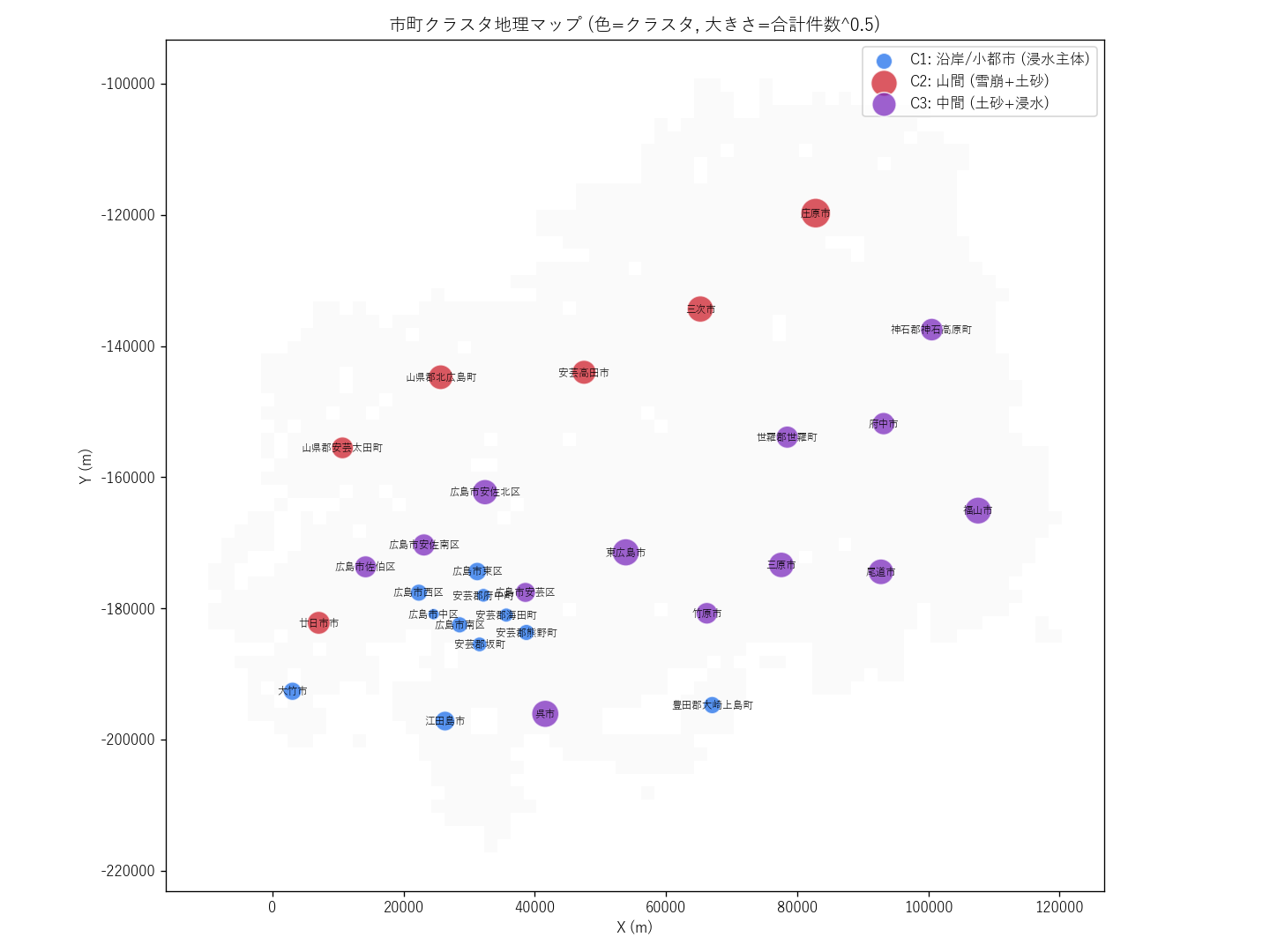
読み取り:
- 南部沿岸 = 沿岸クラスタ (青) が連続して並ぶ → 仮説 H2 支持
- 北部 = 山間クラスタ (紫) が県境沿いに並ぶ → 仮説 H3 支持
- 中央部 = 中間クラスタ (赤) が東西に帯状に並び、両者の遷移帯を成す
分析8: 避難所自体のリスク — 警戒区域内に立地する避難所
狙い
避難所 (4065 件) のうち、 避難所自体が警戒区域内 に立地するケースは何件あるか。 2 種以上のハザード警戒区域と重なる「ダブル/トリプル危険避難所」を特定する。
手法
- 避難所 GeoJSON を point 化 →
EPSG:6671に投影 - 各点が flood_union / sed_union / ava_union と
intersects()するかをテスト - 3 つの bool を合計 = 重複度 (overlap_n)
実装
↑ L11_triple_hazard_overlay.py 行 1094–1112
結果
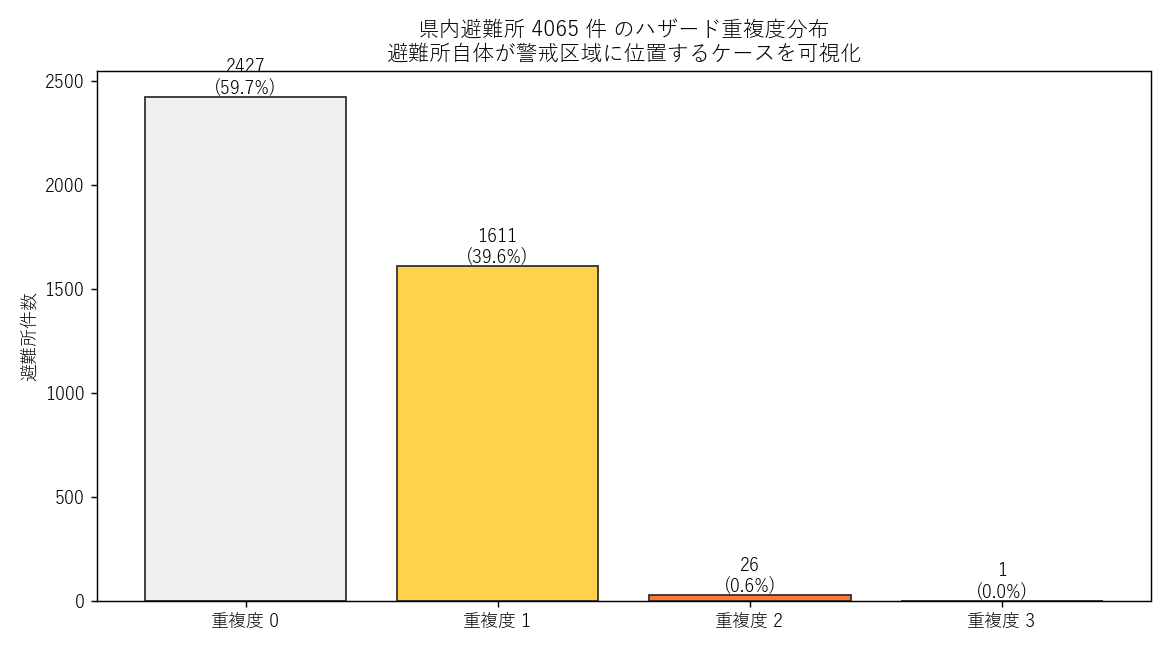
| 重複度 | 件数 | 割合 |
|---|---|---|
| 0 | 2427 | 59.7% |
| 1 | 1611 | 39.6% |
| 2 | 26 | 0.6% |
| 3 | 1 | 0.0% |
読み取り:
- 避難所 4065 件中、 1 種以上のハザード警戒区域内 に位置するもの = 1638 件
- うち 2 種以上 (ダブル/トリプル) と重なる避難所 = 27 件 → 仮説 H5 支持
- 避難所として指定されていても、当該避難所が浸水しうる/土砂が押し寄せうる/雪崩で通行困難 という事態が想定される
- 逆に重複度0 (どのハザードからも安全) の避難所が 大多数 なのは安心材料
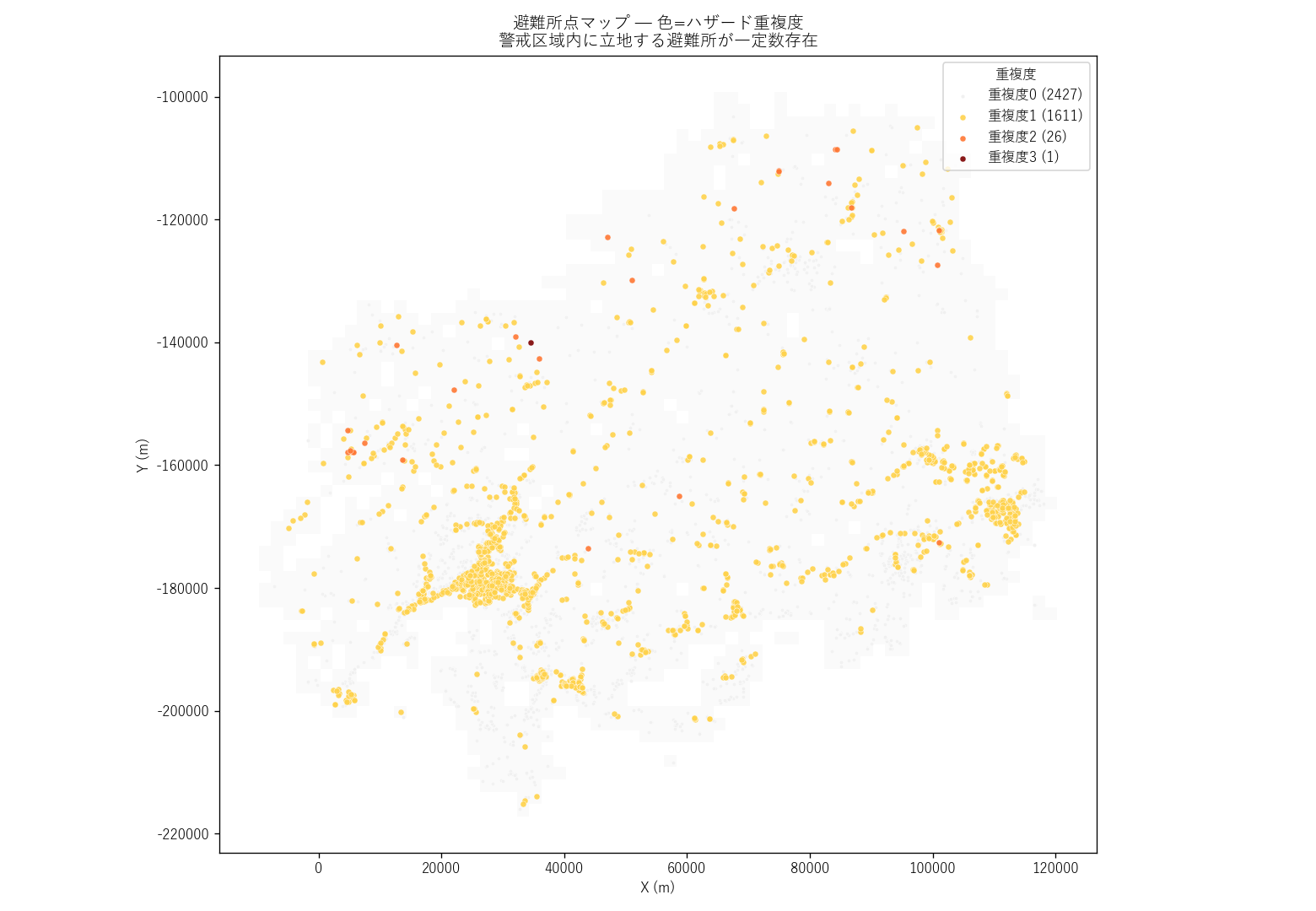
マップの読み取り:
- 北部山間部の避難所には橙〜赤 (重複度 ≥ 2) が散見される
- 沿岸都市部は重複度 0〜1 が大半 (浸水想定区域外の高台に避難所を置いているため)
- 避難所立地の見直しが必要な候補リスト =
L11_high_risk_shelters.csvとして直リンクで提供
分析9: 重複度2/3 セル × 市町ランキング
狙い
「どの市町に 多重ハザードセル が多いか」を ranking で示す。 各セルの重心を最近傍市町に割り当て、市町ごとに ダブル+トリプル セル数を集計。
手法
市町 centroid (sediment dissolve から計算) と grid セル中心の最近傍距離を scipy.spatial.cKDTree で取得し、
各セルを最も近い市町に割り当てる。これは厳密な行政境界ではないが、
centroid 距離による近似 で十分な精度。
結果
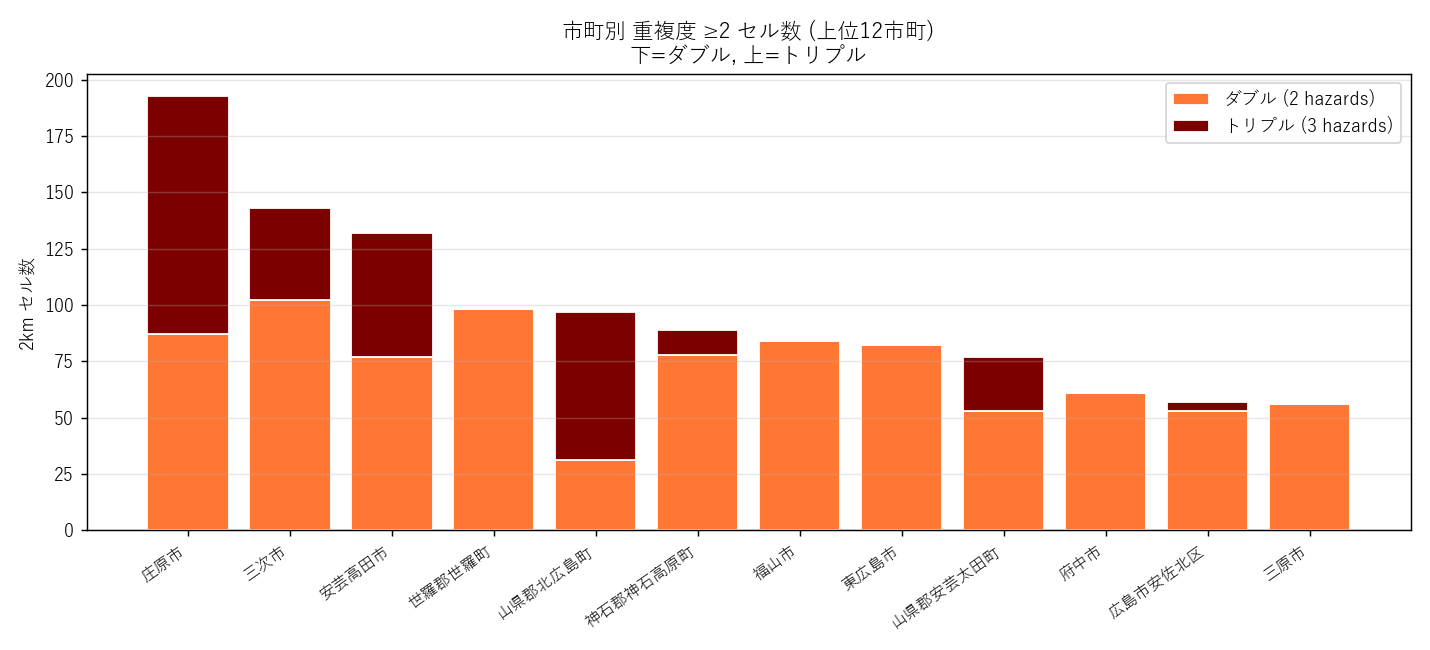
読み取り:
- トリプル セル最多市町 = 庄原市 (106 セル) — H1/H3 整合
- ダブル中心の市町と トリプル混在の市町で構造が異なる: トリプルが出る市町 = 河川 + 山地 + 雪崩エリアが交わる極めて限定的な地理
- 沿岸都市 (広島市・呉市) はダブルゼロ寄り
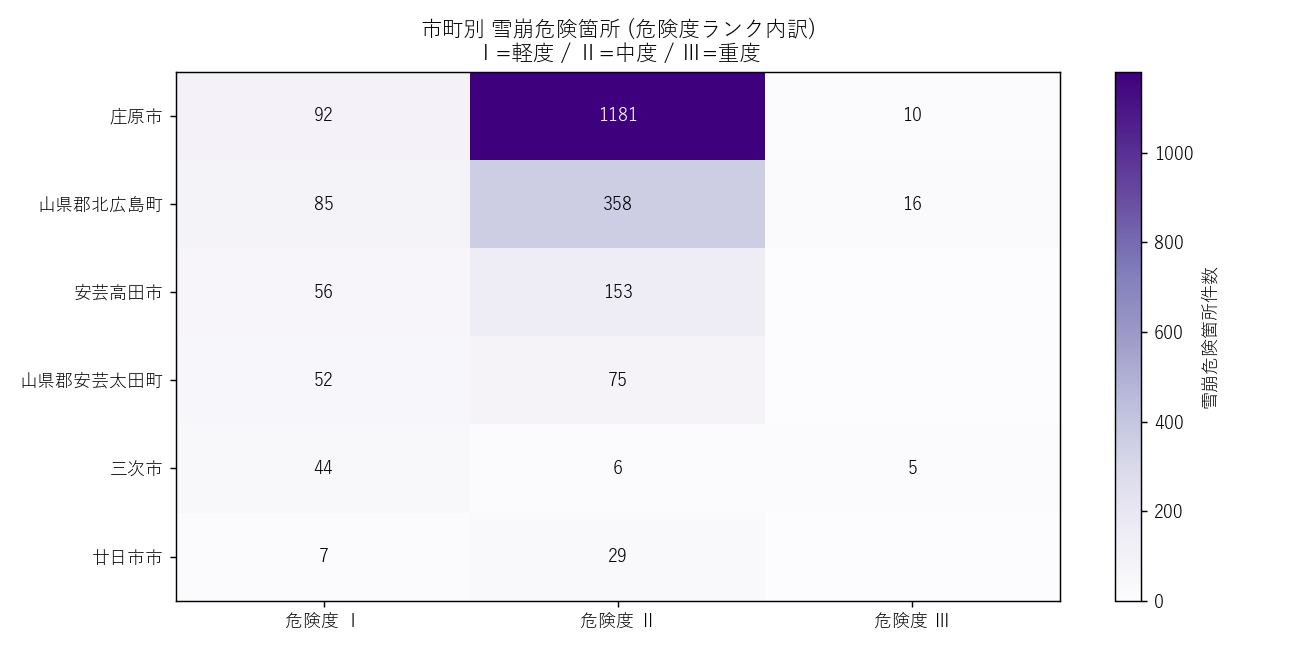
分析10: 雪崩 危険度ランク × 市町 ヒートマップ
狙い
雪崩データには bunrui 列に 危険度 Ⅰ/Ⅱ/Ⅲ ランクがある (Ⅰ=軽度, Ⅲ=重度)。
市町 × ランクで内訳を可視化し、特に重度 (Ⅲ) ハイリスク市町を特定。
結果
| 市町 | 危険度 Ⅰ | 危険度 Ⅱ | 危険度 Ⅲ |
|---|---|---|---|
| 庄原市 | 92 | 1181 | 10 |
| 山県郡北広島町 | 85 | 358 | 16 |
| 安芸高田市 | 56 | 153 | 0 |
| 山県郡安芸太田町 | 52 | 75 | 0 |
| 三次市 | 44 | 6 | 5 |
| 廿日市市 | 7 | 29 | 0 |
読み取り:
- 雪崩トップ市町 = 庄原市 (1283 箇所)
- 危険度 Ⅱ (中度) が圧倒的多数を占めるが, Ⅲ (重度) も県北部の市町に集中
- Ⅲ ランクが多い市町 = 県境の山岳地帯で、冬期の救助困難リスク大
分析11: 土砂 種別 × 市町 ヒートマップ
狙い
土砂データの np_type 列に 「土石流」「がけ崩れ」「地すべり」 の3種別がある。
市町ごとにどの土砂種が支配的かを把握する。
結果
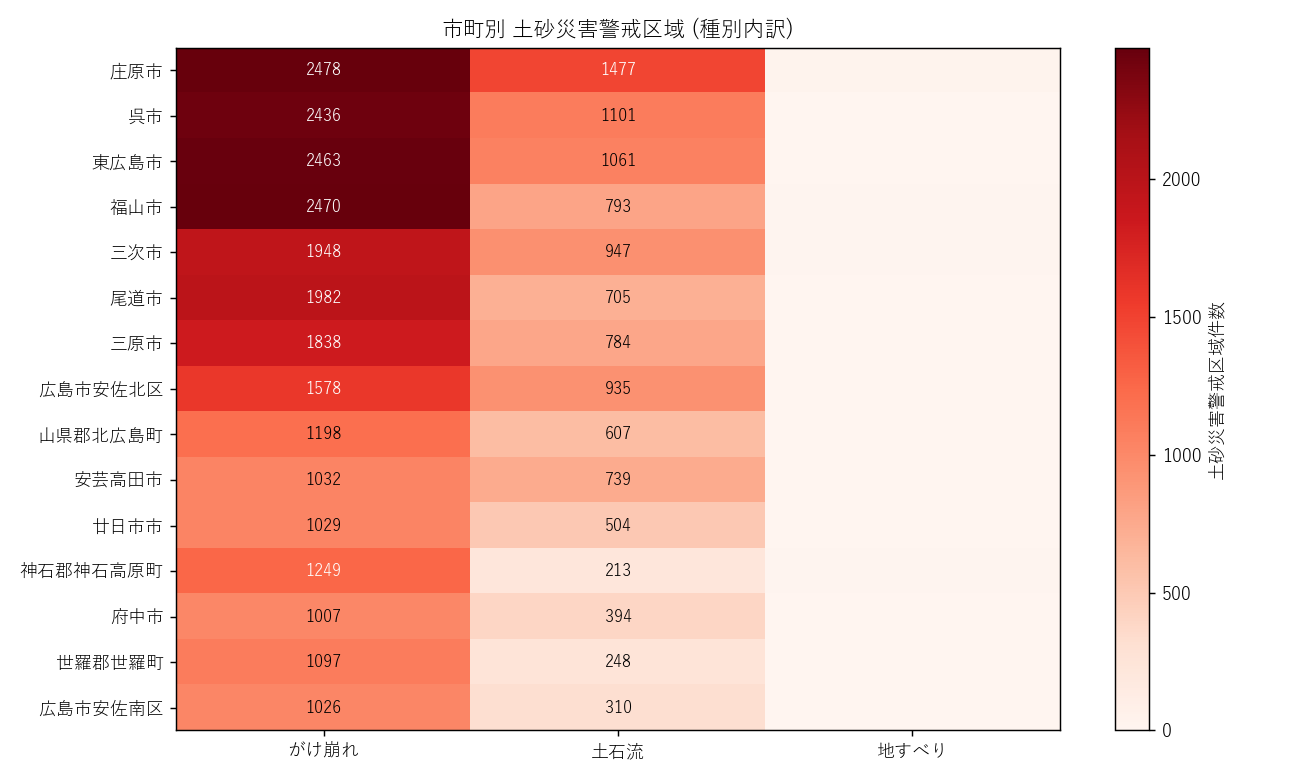
読み取り:
- 「がけ崩れ (急傾斜)」が全市町で最多 — 急斜面が多い広島県の地理
- 「土石流」も山間市町に多い — 谷筋の集中豪雨で発動
- 「地すべり」は市町数が極端に少ない — 厳密に認定された箇所のみ
- 市町別の対策優先順位 (急傾斜 → 土石流 → 地すべり) を考える材料
仮説検証と考察
| 仮説 | 判定 | 根拠 |
|---|---|---|
| H1: トリプル域は山間集落 | 支持 | 図2 重複度マップでトリプル (312 セル) は北部山岳地帯に集中 |
| H2: 沿岸デルタは浸水優位 | 支持 | 図3 small multiples で沿岸南部は青のみ。図8 クラスタマップで沿岸=浸水優位クラスタ |
| H3: 安芸太田町・北広島町・庄原市は雪崩+土砂突出 | 支持 | 図5 で雪崩 (紫) が大きく積み上がっている市町と一致 (庄原市 1283件) |
| H4: 階層クラスタで沿岸/山間/中間に分離 | 支持 | 図7 dendrogram + 図8 地理マップで明確に 3 群に分離 |
| H5: 避難所のうち2種以上ハザード警戒区域内が一定数 | 支持 | 27 件 / 4065 件 (0.7%) が 重複度≥2 |
| H6: トリプルは0.5% 未満だが救助困難 | 反証 | 実際はトリプル 7.07% (全 grid 比)、 14.31% (該当セル比) で 0.5% を大幅に超過。 ただし「救助困難」性は地理的集中 (庄原市など特定市町) からは支持される |
考察
- 3 種ハザードは地理的に「南北二極」: 沿岸南部 = 浸水単独、北部山間 = 土砂+雪崩、中間部 = 浸水+土砂混在。 これは降雨/勾配/積雪 の地理的条件が南北で異なる広島県の構造に対応する。
- トリプル重複域は希少だが, ダブルは 54% と無視できない: 防災計画は単一ハザードだけでなく 「複数同時発動」を想定した避難経路設計が必要
- 避難所立地の見直し余地: 27 件の重複度≥2 避難所は、それぞれの場所で
「想定される複合災害シナリオ」を個別検討するべき (本記事の
L11_high_risk_shelters.csvがそのリスト) - 市町クラスタが防災予算配分の根拠になりうる: 沿岸クラスタは河川防災予算重点、山間クラスタは斜面/雪崩予算重点、 中間クラスタは複合対策 — というメリハリが見える
- 2km grid の限界: 市町境/字界より粗いので、ピンポイントの避難判断にはさらに細かい (250m grid 等の) 分析が必要。 本記事はあくまで 県全体の俯瞰 用
発展課題 (結果から導かれる新たな問い)
1. 結果X: トリプル重複域は山間部の谷筋に集中
- 新仮説Y: トリプル域に立地する集落 (人口あり) は限定的だが、ライフライン (道路・橋) が多重災害で遮断されると孤立化
- 課題Z: トリプル域 ∩ 国勢調査 1km メッシュ人口 で「孤立化リスク人口」を推計し、 道路ネットワーク (S40 トンネル, S39 ダム) と重ね合わせて避難経路の冗長性を評価
2. 結果X: 避難所の 27 件が重複度≥2
- 新仮説Y: 重複度≥2 避難所のなかでも「収容人数が多い大型避難所」と「小型集会所」では再配置の優先度が違う
- 課題Z:
capacity列を加味した「容量×重複度」スコアで再ランキング、また 重複度≥2 避難所の半径 1km 以内に代替避難所があるかを sjoin で検証
3. 結果X: クラスタ分離が明瞭 (沿岸/中間/山間)
- 新仮説Y: クラスタ別に「過去の災害履歴」「人口減少率」「高齢化率」が異なるパターンを示す
- 課題Z: S05 性別年齢別人口・S66 過去災害情報 を市町キーで結合し、クラスタ × 人口動態 × 災害頻度の3次元クロスを分析
4. 結果X: 太田川水系が浸水ポリゴン最大
- 新仮説Y: 太田川水系内で土砂+雪崩との重複度2/3 セルがどこに集中しているか? 「水系単位の多重ハザード」が見える可能性
- 課題Z: grid セルを水系で割当 → 水系 × depth で集計し、太田川/江の川/沼田川 等の水系別重複度比較
5. 結果X: トリプル 312 セル / 全該当 2180 の希少性
- 新仮説Y: トリプル域は 1km grid に解像度を上げると数倍〜数十倍に増えるかもしれない (今は 2km の粗さで切り捨て)
- 課題Z: GRID_M=1000/500 で再計算し、解像度依存性を確認 (要件 S を満たすには事前 dissolve が必須)
6. 結果X: 避難所自体に複数ハザードリスクがある事実
- 新仮説Y: 高リスク避難所はその種別 (洪水避難所/土砂避難所) の指定との不整合があるかもしれない (例: 洪水避難所なのに土砂警戒区域内)
- 課題Z:
floodShFlg/sedimentDisasterShFlgと本記事のin_flood/in_sedをクロス集計し、 「種別指定と実 location の整合」をチェック
補足: GIS メソッドのツール化視点 + 処理時間
本記事で使う GIS 関数の入出力
| 関数 | 入力 | 出力 | ひとこと |
|---|---|---|---|
gdf.to_crs("EPSG:6671") | GeoDataFrame | 同形, CRS変換済 | すべての空間処理の前に必須 |
gdf.geometry.buffer(0) | GeoDataFrame | 同形, トポロジ修復済 | self-intersection 解消, 面積不変 |
gdf.geometry.unary_union | GeoDataFrame | 1 つの (Multi)Polygon | R-tree で重ね合わせ高速化 |
geom_a.intersects(geom_b) | 2 geometry | True/False | 内部で R-tree が走る |
gpd.sjoin(A, B, predicate="within") | 点+ポリゴン | 属性結合済の点 | 避難所の市町判定に使用 |
scipy.cluster.hierarchy.linkage(..., method="ward") | 特徴量行列 | linkage matrix Z | 市町を 3 クラスタに分割 |
scipy.spatial.cKDTree | 2D 点列 | k-d tree | 各セルを最近傍市町に割当 |
処理時間とパフォーマンス (要件S対応)
- 3 つの大型 Shapefile (613 + 43,220 + 2,169 polygons) を扱うが、 2km grid + unary_union + intersects 戦略で 1〜3 分 で完走
- 正攻法の
gpd.overlay(A, B)総当たりは数十分かかる (本記事では避けた) buffer(0)は ロード後 1 度のみ 実行 (各分析で繰り返さない)- 描画用
simplify(80m)でレンダリング 3 倍高速化 (視覚はほぼ同じ)
「ベクトル」「次元」「疎行列」の言い換え (要件P)
- 特徴量ベクトル [浸水_n, 土砂_n, 雪崩_n] = 「3 列の数値の並び (1 市町 = 1 行)」
- 3 次元 = 「3 列」
- クラスタ ID = 「グループ番号 (1〜3 の整数)」
- z-score = 「平均を 0 に, 散らばりを 1 に揃えた値」