プライバシ・グリッド — k-匿名性 / quadtree / 差分プライバシ
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #444 | dataset #444 |
| #1279 | 県内のカメラ情報 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L10_privacy_grid.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
このレッスンで答えたい問い
「カメラ位置のような『ピンポイントの位置データ』を、個人特定リスクを下げて公開するには、どんな道具がどこまで効くのか?」
道路・河川カメラ自体は本来公開情報。本レッスンは 「個人や要援護者の位置データを、仮にこのカメラ点群と同じ密度で扱った場合」 を念頭に、 代表的な3手法を 「ツール」として比較する シミュレーション教材。
用語の定義 (このレッスン独自・冒頭で平易に)
- k-匿名性 (k-anonymity): 「同じ場所(=同じセル)にいる人が k 人以上になっていれば、その中の誰かは特定できない」という考え方。 k=1 はその場所に あなた1人しかいない=即特定。k=5 なら最低5人と紛れる。 ツールとしては「セルに分割して、k 未満のセルは公開しない or 粗くする」操作。
- quadtree (クアッドツリー): 地図を 4分割→各区画をさらに4分割→…と再帰的に細かくしていく木構造。 本レッスンでは「セル内の点数が k_min 未満になりそうなら分割を止める」よう細工する。 結果: 都市部は細かく、過疎地は粗く、点数のバランスが取れたセル分割になる。
- 差分プライバシ (Differential Privacy, DP): データに小さなランダムノイズを加えることで、「あなた1人がデータに含まれていたかどうかを攻撃者が見破れない」ことを 数学的に保証する技法。 ε(イプシロン) という1つのパラメータで「保護の強さ」を制御する(小さいほど強保護・大きいほど弱保護)。
- utility / privacy: utility(ユーティリティ)=「データの使いやすさ・精度」、privacy(プライバシ)=「個人が守られる度合い」。 この2つは シーソー関係で、両方を最大化するのは原理的に難しい。本レッスンの最終図(図5)で定量化する。
立てた仮説 (後で検証する)
- H1 (固定グリッドは万能ではない): 「県全体に同じ大きさの格子をかぶせる」という素朴な方法では、 都市部は過剰に粗く、山間部は k=1 のままになる。 つまり 均一なセルでは均一な保護にならないはず。
- H2 (k を上げるほど解像度が必要): k≧1, 2, 5, 10 と要求を厳しくするほど、それを満たすには 大きなセルが必要になる。 k≧10 を全点で達成するには、km単位のセルが要るはず。
- H3 (quadtree は固定グリッドに勝つ): 「点が多い場所だけ細かく割る」適応分割なら、 同じプライバシ水準(k_min)を より細かい平均粒度で達成できるはず。 utility-privacy 平面上で固定グリッドより 左上に位置する。
- H4 (差分プライバシは ε で揺らぎが指数的に変わる): Laplace ノイズの幅は b=Δ/ε。 ε を 1.0 → 0.1 に下げると揺らぎは 10倍になる。 ε=0.1 のような強保護では、地図公開には 使い物にならないレベルでジッタするはず。
- H5 (1棟特定は10m格子で起きる): GPS の生精度が 5〜10m。 10m 格子では占有セルの大半が k=1 となり、 1棟単位での特定が技術的に可能になるはず。 「位置データは本質的に強い識別子」という直観を数値で確認する。
到達点
- 5仮説に対して、5つの分析でそれぞれ 支持/反証/部分支持 を判定できる
- k-匿名性/quadtree/差分プライバシ の3手法を 「何を入れて何が返るか」のツール視点で説明できる
- 「どの粒度で公開すべきか」を utility-privacy トレードオフ図から定量的に選べる
- 内部の確率不等式 (Laplace 機構の事後分布比 ≤ e^ε など) は 黒箱で OK。 ツールの 入出力と限界を語れることが目標。
使用データ
- 名称 河川・道路カメラ位置情報
- 取得元 DoBoX #1279
- 件数 351 点 (緯度・経度・住所・路河川名・所管・管理区分 の 9 列)
- ファイル
data/camera_list.csv(UTF-8 BOM, 約 70 KB) - 位置範囲 緯度 34.087〜35.084, 経度 132.088〜133.413 (広島県全域)
- 背景 道路・河川カメラの座標は本来公開情報。本レッスンは 「個人や要援護者の位置データ」を仮にこの密度で扱う場合 を念頭においたシミュレーション教材
- なぜカメラなのか 県全域に 不均一に(都市部に密、山間に疎) 分布する 351 点という規模が、k-匿名性の歪みと adaptive 分割の必要性を体感するのに最適
ダウンロード(再現用データ・中間データ・図)
本レッスンの全成果物に直リンクを置いた。途中ステップから再現したい学習者向け。
1. 生データ (DoBoX 由来)
| ファイル | 形式 | サイズ | 取得元 |
|---|---|---|---|
data/camera_list.csv |
CSV (緯度・経度・住所・路河川名・所管・管理区分) | 約 70 KB / 351 行 | DoBoX #1279 |
2. プログラムで生成される中間データ
| ファイル | 内容 | 使う分析 |
|---|---|---|
L10_grid_counts.csv |
1km/500m/250m 各解像度の占有セル・k=1セル数等の集計 | 分析1 固定グリッド |
L10_sample_trace.csv |
1点 (#1 苗代カメラ) を生データ→3粒度に量子化した Before/After 表 | 分析1 入出力具体例 |
L10_k_anonymity_curve.csv |
6解像度 × 4 k値 の達成率(% を満たす点の割合) | 分析2 k曲線 |
L10_quadtree_summary.csv |
k_min=2/5/10 の leaf 数・面積中央等のサマリ | 分析3 quadtree |
L10_quadtree_cells.csv |
全 leaf の bbox・点数・面積 (3 k_min 全部) | 分析3 quadtree 詳細 |
L10_dp_results.csv |
ε=1.0/0.5/0.1 の Laplace b・ジッタ統計 | 分析4 差分プライバシ |
L10_dp_per_point.csv |
全 351 点 × 3 ε のジッタ距離 (1053行) | 分析4 詳細 |
L10_tradeoff.csv |
固定グリッド6点 + quadtree 3点 のセル面積×k中央 | 分析5 トレードオフ |
L10_house_scale.csv |
5m〜100m の細粒度における k=1 リスク | 仮説H5 検証用 |
3. 図 PNG
- L10_grid_heatmap.png — 図1 固定グリッド3解像度のヒートマップ
- L10_k_curve.png — 図2 k-匿名性曲線 (6解像度 × 4 k値)
- L10_quadtree.png — 図3 adaptive quadtree (k_min=2/5/10)
- L10_dp_noise.png — 図4 差分プライバシ (ε=1.0/0.5/0.1)
- L10_tradeoff.png — 図5 utility-privacy トレードオフ
4. 再現スクリプト
cd "2026 DoBoX 教材"
py -X utf8 lessons/L10_privacy_grid.pyスクリプト本体: lessons/L10_privacy_grid.py
(データが無ければ ensure_dataset() で自動DL → 5枚のPNGと9本の中間CSVを生成)
分析1: 固定グリッド + k-匿名性
狙い
「県全体を同じ大きさの格子で割って、各セルの中に何人(=点)いるかを数える」だけの素朴な方法を試す。 これが k-匿名性の最もシンプルな実装で、3つの粒度 (1km / 500m / 250m) を比較して 「均一格子の盲点」(=都市部は過剰に粗く、山間部は k=1 のまま) を視覚化する。仮説H1 の検証。
- 入力: 351点の緯度経度
- 出力: 各点に「同じセル内の他の点数 (k)」のラベル
- 使い方: k 未満のセルにある点は「公開しない」「粗いセルにマージする」「ノイズで上書きする」等の判断材料にする
- 限界: 同じセル内の人が 属性的に均質(全員が同じ性別・年齢) なら、k≧5 でも事実上特定できる(homogeneity attack)。これを補うのが l-diversity / t-closeness で、発展課題で扱う。
手法 (緯度経度の格子量子化)
- 入力: 351点の (lat, lon) と セル一辺 cell_m メートル
- 処理: 緯度1度=111km, 経度1度=111·cos(lat) km の cos 補正 でメートル→度を換算し、
floor(lat / cell_lat)とfloor(lon / cell_lon)でビン化 - 出力: 各点の (セル行 i, セル列 j) ペア →
value_countsで「セル内点数」 - パラメータ: cell_m ∈ {250, 500, 1000} m (細→粗)
- 結果の読み方: k=1 セルが「個人特定リスク高」、k≧5 で「実用安全圏」が一般的目安
実装
図と読み取り
なぜこの図か: 3粒度を 同じ枠で並べる(small multiples) ことで、 セルが細かくなるほど k=1 の白〜薄黄セルが急増する様子を一目で比較できる。 1枚の図だけでは「これは粗いのか細かいのか」を相対判断できない。
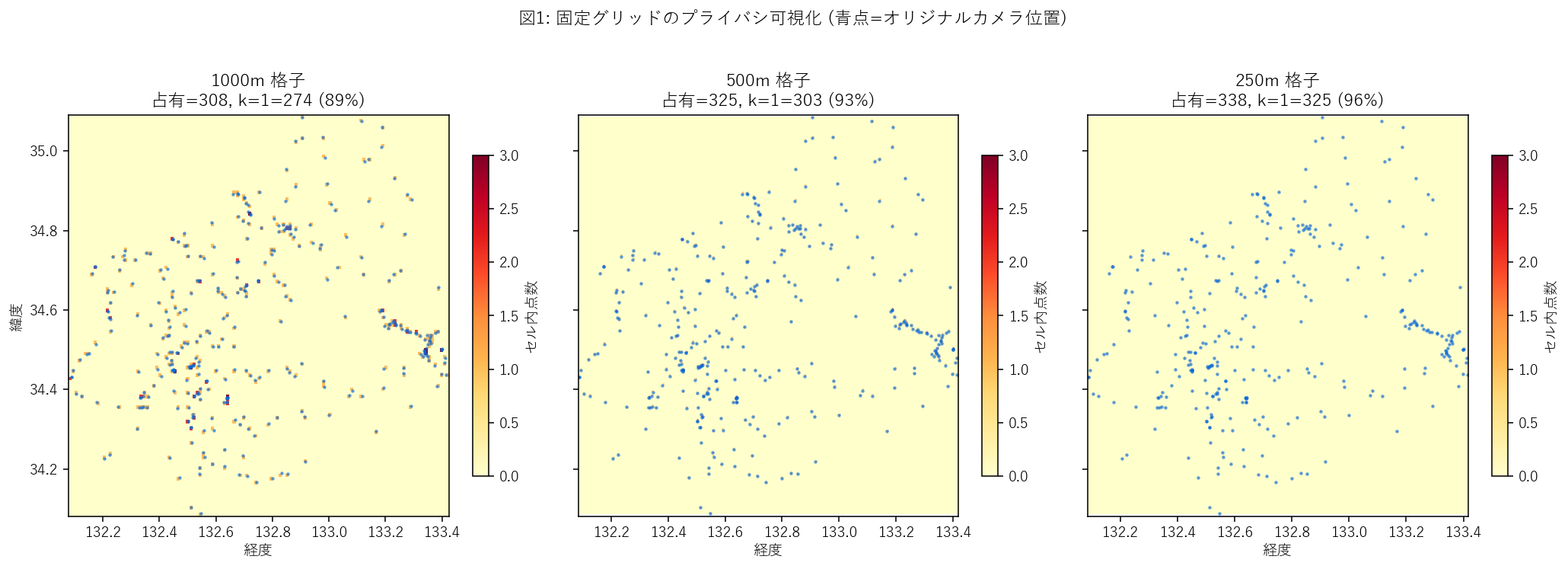
この図から読み取れること:
- 都市部(広島市・福山市)は色濃い: 1km 格子なら k≧5 を確保できる地域が多い
- 山間部・島嶼部はほぼ薄黄: どの粒度でも k=1 のセルが多数 — 同じ格子では都市と山で「保護の質」が違う
- 250m 格子では過半数が k=1: タイトルの
k=1セル割合数値が確認できる - 仮説H1 を支持: 均一なセルでは 均一な保護にならない
表と読み取り
なぜこの表か: 図1 の見た目を 「失う点数」という具体数で裏付けたい。 k≧3 を満たさないセルは公開時に削るので、その時点で何点が地図から消えるかを可視化する。
表1: 3解像度のセル統計
| セル一辺(m) | セル面積(km²) | 占有セル数 | k=1セル数 | k=1セル割合(%) | k≥3セル数 | k≥3条件で残る点数 | 失う点数 |
|---|---|---|---|---|---|---|---|
| 1000 | 1.000 | 308 | 274 | 89.0 | 7 | 23 | 328 |
| 500 | 0.250 | 325 | 303 | 93.2 | 3 | 10 | 341 |
| 250 | 0.062 | 338 | 325 | 96.2 | 0 | 0 | 351 |
読み取り: 1km 格子では k≧3 を満たすセルが多く、失う点数が比較的小さい。 逆に 250m では失う点数がぐっと増え、利用可能な情報が大幅に減る。 細かさ(=utility)とプライバシ保護は逆相関であることが数値で確認できる。
表2: 1点を最初から最後まで追う Before/After (No.1 苗代カメラを例に)
| 段階 | 値 | 粒度 | このセル内の点数 (k) | 個人特定リスク |
|---|---|---|---|---|
| 原データ | (34.297405, 132.592275) | GPS精度 約5m | — | 高 (1棟単位で特定可能) |
| 250m 格子に量子化 | セル中心 (34.2984, 132.5915) | 250m × 250m | 1 | 高 |
| 500m 格子に量子化 | セル中心 (34.2995, 132.5901) | 500m × 500m | 1 | 高 |
| 1000m 格子に量子化 | セル中心 (34.3018, 132.5874) | 1000m × 1000m | 1 | 高 |
読み取り: 同じ点でも セル一辺を粗くするほど k が増え、リスクが下がる。 逆に細かい格子では k=1 になりがちで、その点は公開不可と判定される。 このように 「ある1点」がツールにかけられた後どう変換されるか を最後まで追えるのが、 データ前処理の理解の核心。
分析2: k 値変化曲線(解像度を細→粗に振って曲線化)
狙い
「セルの大きさを 100m から 5km まで振ったら、k≧1, 2, 5, 10 の各条件を満たす点はそれぞれ何%になるか?」 を1枚の折れ線グラフにする。3粒度の点(分析1)を 連続曲線に拡張することで、 「実務目安 80% を超えるにはどれくらい粗くする必要があるか」が読めるようになる。仮説H2の検証。
手法 (解像度パラメータスイープ)
- 入力: 351点 + 解像度リスト [100m, 250m, 500m, 1km, 2km, 5km] + 目標 k リスト [1, 2, 5, 10]
- 処理: 各解像度で
grid_label→value_counts→ 各点について「自分のセルの k」を引き、(k ≥ 目標)を.mean()で割合化 - 出力: 6解像度 × 4 k値 の 達成率 (%) 行列 → 折れ線グラフ
- 結果の読み方: 80% ライン (実務目安) と曲線の交点が 「最低限必要な粗さ」
実装
↑ L10_privacy_grid.py 行 762–793
図と読み取り
なぜこの図か: x軸を 対数スケール(100m〜5km)、y軸を達成率(%) にすることで、 「どこまで粗くすれば 80% を超えるか」を直接読めるようにした。 4本の線(k=1, 2, 5, 10) を重ねることで、k 要求が厳しくなるほど右にシフトすることが視覚化される。
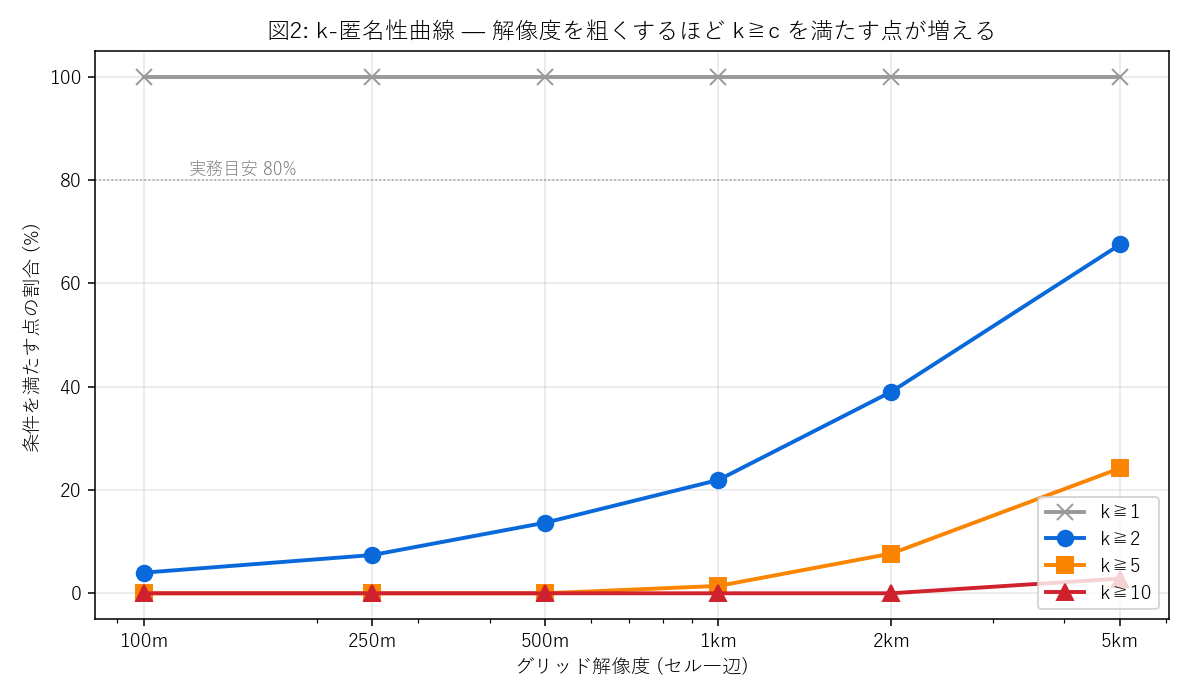
この図から読み取れること:
- k≧1 はどの解像度でも 100% (自分自身が1人いるので自明)
- k≧2 達成率は 5km 格子でも約 67.5%: 100m なら 4%, 1km なら 22% にとどまり、80%目安には届かない
- k≧5 達成率は 5km でも約 24%: 単純グリッドでは 351点という規模では「他に4人いる場所」自体が少ない
- k≧10 は 5km でも 2.8% のみ: 山間離島ではどう粗くしても点が孤立する
- 仮説H2 を支持: k を上げるほど曲線は 右に大きくシフト。点数が少ないと固定グリッドだけでは k 確保が原理的に厳しい
表と読み取り
表3: 解像度 × k目標 の達成率(%)
| 解像度(m) | 占有セル数 | 中央k | k≥1 達成率(%) | k≥2 達成率(%) | k≥5 達成率(%) | k≥10 達成率(%) |
|---|---|---|---|---|---|---|
| 100 | 344 | 1.0 | 100.0 | 4.0 | 0.0 | 0.0 |
| 250 | 338 | 1.0 | 100.0 | 7.4 | 0.0 | 0.0 |
| 500 | 325 | 1.0 | 100.0 | 13.7 | 0.0 | 0.0 |
| 1000 | 308 | 1.0 | 100.0 | 21.9 | 1.4 | 0.0 |
| 2000 | 266 | 1.0 | 100.0 | 39.0 | 7.7 | 0.0 |
| 5000 | 187 | 1.0 | 100.0 | 67.5 | 24.2 | 2.8 |
読み取り: 「k≧5 を 80% 確保したい」という設計目標を立てた場合、表から 5km格子でも 24%=固定グリッドでは届かない。 これは「351点という規模では、地理的に疎な点が多すぎて、均一格子では k≧5 を多くの点で確保できない」ことの定量的証拠で、 固定グリッドの限界を端的に示す数字である。 これが分析3の adaptive quadtree を導入する動機になる(quadtree なら「点が密な場所だけ細かく」できる)。
分析3: adaptive quadtree(適応分割)
狙い
「点が多い場所だけ細かく、点が少ない場所は粗く」を自動でやる。 固定グリッドの欠点(都市過剰粗・山間k=1)を 木構造の再帰分割で解決する。 仮説H3 の検証。
- 入力: 351点の (lat, lon) と最低人数 k_min
- 出力: 「どんなセル分割をすれば全てのセルが k_min 人以上になるか」 という地図分割 (leaf の集合)
- 動作のイメージ: 全域→4分割→各区画でまた4分割→… ただし「分割すると k_min を割る区画が出る」なら そこで分割を止める(leaf 化)。 結果として、点が密な広島市内は細かいセル、点が疎な山間部は粗いセルが自動で出来上がる。
- 限界: 矩形分割なので「対角に伸びる集落」を理想的には捉えられない。 ボロノイ分割など別形状もあるが、quadtree は 実装が単純かつ 木構造で高速検索できるのが利点。
手法 (再帰的4分割アルゴリズム)
- 入力: 全点 pts + 全域 bbox + k_min
- 処理:
- もし
len(pts) < 2*k_minならこれ以上割れない → leaf にする - そうでなければ bbox の中央で 南北・東西に2回ずつ切って4区画に分ける
- 4区画のうち どれか1つでも 0 < n < k_min になるなら、分割を中止して leaf 化
- 全区画が空 or k_min 以上なら、4子それぞれに対して再帰呼び出し
- もし
- 出力: 全 leaf が「0点 (空)」か「k_min 点以上」を保証する木
- パラメータ: k_min ∈ {2, 5, 10}, max_depth=14 (再帰の安全弁)
実装
↑ L10_privacy_grid.py 行 839–914
図と読み取り
なぜこの図か: セル境界の矩形と 点の分布を1枚に重ねることで、 「点が密な地域は細かい矩形、疎な地域は粗い矩形」という適応分割の本質が一目で分かる。 3つの k_min を並べると、k_min が大きいほど leaf が 合体して粗くなる過程が見える。
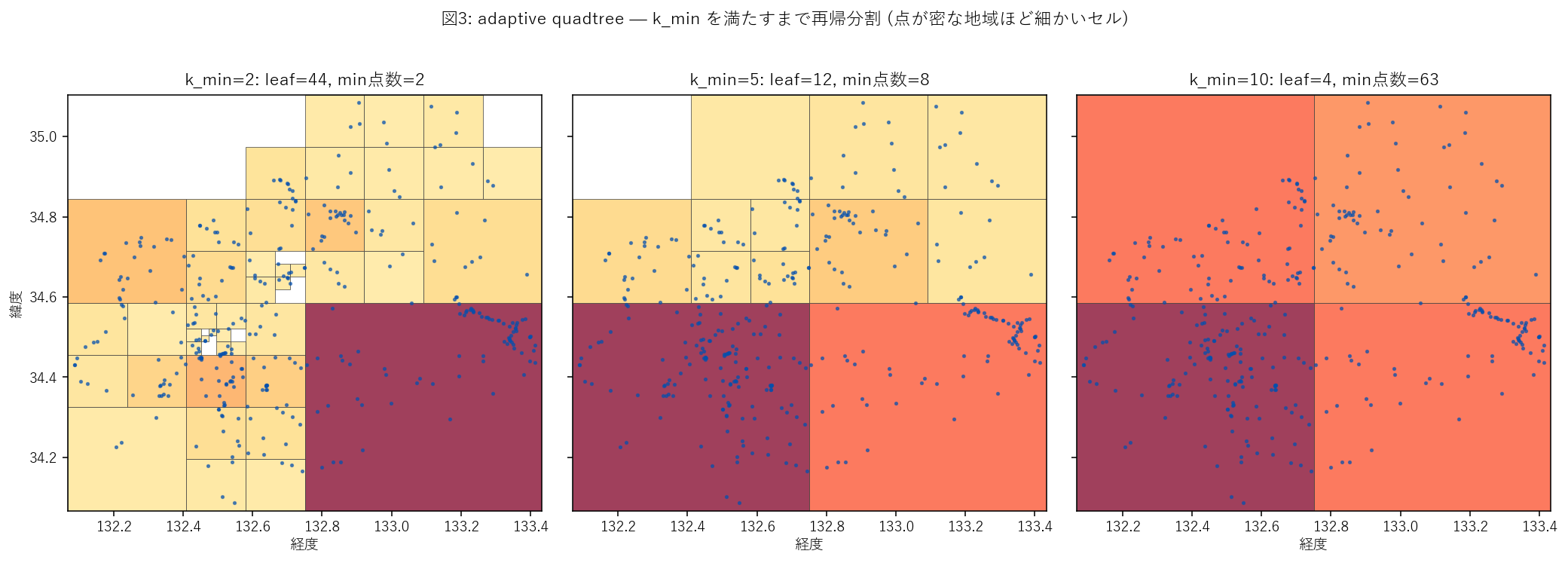
この図から読み取れること:
- 広島市・福山市付近は細かい矩形が密集: カメラが多いため細かく割れる
- 北部山間・島嶼部は大きな矩形: 点が疎なので粗いまま leaf 化
- k_min=2 → 5 → 10 と増やすと leaf 数が減る(矩形が大きくなる): 表4 の数値で裏付け
- すべての leaf が k_min 以上を保証: 矩形最小色 (薄黄) でも k_min 人いる
- 仮説H3 を支持: 固定グリッドが原理的に解けない「都市と山間の不均衡」を quadtree が解消
表と読み取り
表4: k_min ごとの quadtree 統計
| k_min | leaf 数 | min 点数 | 中央 点数(leaf) | max 点数 | 中央 leaf 面積(km², leaf単純) | 中央 leaf 面積(km², 点加重) | 中央 k(点加重) |
|---|---|---|---|---|---|---|---|
| 2 | 44 | 2 | 4 | 76 | 224.460 | 224.460 | 12 |
| 5 | 12 | 8 | 12 | 136 | 897.839 | 3591.357 | 76 |
| 10 | 4 | 63 | 76 | 136 | 3591.357 | 3591.357 | 76 |
読み取り: k_min を上げる → leaf 数が減る → 中央 leaf 面積が大きくなる という関係が定量化されている。 min 点数列は必ず k_min 以上で、設計通り 「全 leaf が k_min を満たす」保証が効いている。 分析5 のトレードオフ図で、これらの数値が 固定グリッドより左上(=同じ k を小さい平均面積で達成) に 配置されることを確認する。
分析4: 差分プライバシ(Laplace ノイズ追加)
狙い
「全ての点に小さなランダムノイズを足したら、各点はどれくらい元位置からずれるか?」 を ε=1.0 → 0.5 → 0.1 と保護を強めながら可視化し、 「ε とジッタ距離は反比例する」という核心を体感する。仮説H4の検証。
- 入力: 351点の (lat, lon) と保護パラメータ ε(イプシロン)
- 出力: 351点の (lat+ノイズ, lon+ノイズ) — ノイズは Laplace 分布 から無作為抽出
- 保証 (黒箱で OK): 攻撃者が「あなた1人がデータに含まれていたかどうか」を見破る確率の比が e^ε 以下に抑えられる。 これが「数学的にプライバシを保証する」の意味で、内部の不等式 (Pr[出力∈S | あなた含む] / Pr[出力∈S | あなた含まない] ≤ e^ε) の証明は 気になる人向け。
- k-匿名性との根本的違い: k-匿名性は 「同じセルに k 人いれば守られる」というグループ化保護で、攻撃者が背景知識を持つと壊れる。 DP は 「1人を入れ替えても出力分布がほぼ同じ」という確率的保護で、背景知識に強い。
- 限界: ε を強くすると(例 0.1) ジッタが大きすぎて地図が 使い物にならない。 また、同じデータに何回もクエリを投げると ε が累積消費される(composition theorem)。
手法 (Laplace 機構)
- 入力: 351点 + 感度 Δ(本レッスンでは 1km 相当) + ε ∈ {1.0, 0.5, 0.1}
- 処理:
- Laplace 分布のスケール
b = Δ / εを決める (ε 小→b 大→ノイズ大) - 緯度・経度それぞれに 独立に
Laplace(0, b)から抽出したノイズを加算 - ジッタ距離 (km) = √((Δlat·LAT_KM)² + (Δlon·LON_KM)²) で評価
- Laplace 分布のスケール
- 出力: 各点のジッタ後位置 + 中央ジッタ・95%点・最大値の集計表
- パラメータの意味: ε=1.0 → b=1km → 中央ジッタ ≈1.3km(緩い保護, 地図実用OK)。 ε=0.1 → b=10km → 中央ジッタ ≈13km(強保護, 県全域に拡散)
実装
ジャーゴン補足: 「Laplace 分布」=正規分布より 裾が長い(まれに大きなノイズが出る) 確率分布。 DP の Laplace 機構は数学的に「ε-DP を満たす最小ノイズ」として導かれる。 「再識別 (re-identification)」=匿名化したはずのデータから個人を特定し直すこと。
図と読み取り
なぜこの図か: オリジナルと 3つの ε を横一列に並べることで、 ε を強めるにつれて 赤点(DP後)がどれだけ 青点(オリジナル)から離れるかを直接比較できる。 赤線(対応線)はジッタの方向と距離を1点ずつ可視化する装置。
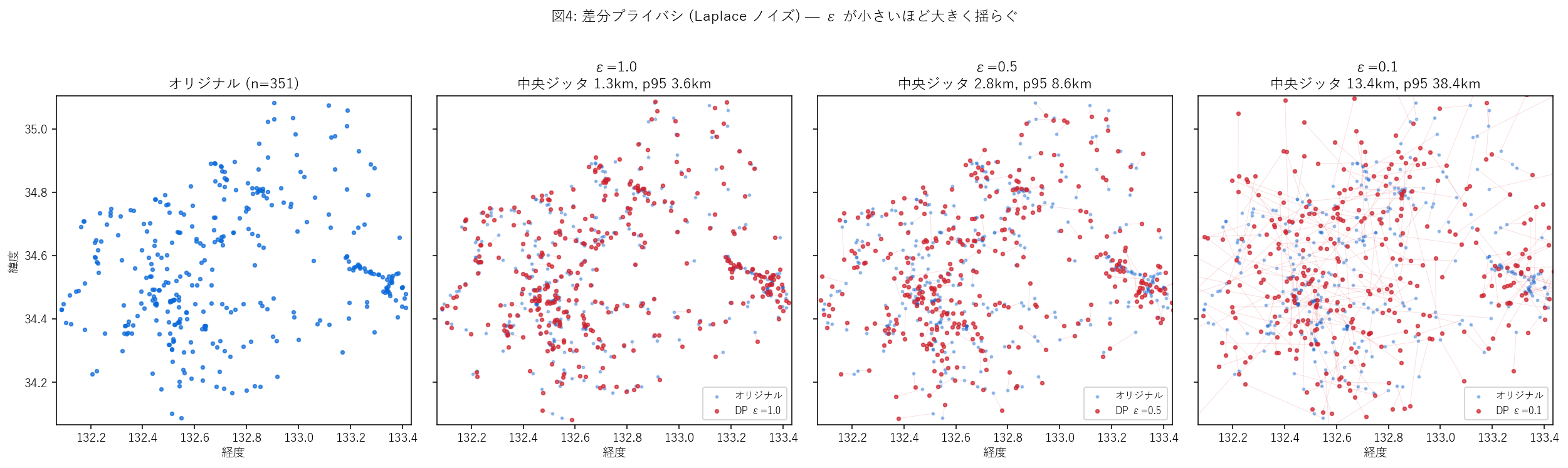
この図から読み取れること:
- ε=1.0: 中央ジッタ 1.3km、95%点 3.6km。「同じ市内にはずれるが県外には飛ばない」程度
- ε=0.5: 中央 2.8km、95%点 8.6km。市町境を越える点が増える
- ε=0.1: 中央 13km、95%点 38km。点が 県全域に拡散し、9% 弱は県外に飛ぶ。もはや「カメラ位置」と呼べる地理情報ではない
- 仮説H4 を支持: ε を 1.0→0.1 と 10倍強める と、ジッタも約10倍に拡大 (Laplace b = Δ/ε の単純な反比例)
表と読み取り
表5: ε ごとのジッタ統計
| ε | Laplace b (km) | ジッタ中央値(km) | ジッタ95%点(km) | ジッタ最大(km) | 県内に収まる点(%) |
|---|---|---|---|---|---|
| 1.0 | 1.0 | 1.34 | 3.64 | 6.45 | 100.0 |
| 0.5 | 2.0 | 2.82 | 8.57 | 13.78 | 99.1 |
| 0.1 | 10.0 | 13.36 | 38.36 | 71.55 | 91.2 |
読み取り: ε と Laplace b と中央ジッタは 1:1 対応の反比例。 ε=0.1 では「県内に収まる点」の割合さえ落ちる(最大ジッタが県外に飛ぶ)。 「ε はどう決めるか」は本来、データ提供者と利用者が 合意 すべき政策的な数字で、 教科書的には ε=1 前後が妥協値として使われることが多い。
分析5: utility ↔ privacy トレードオフ(全手法を1枚に)
狙い
「6種類の固定グリッド × 3種類の quadtree = 9手法」を同じ平面に置いて、 どの手法が utility-privacy のバランスで優位か を一目で比較する。 仮説H3 の最終確認 (quadtree が固定グリッドより左上に来るか)。
手法 (横軸=情報損失, 縦軸=プライバシ強度)
- 入力: 分析1-3 で計算済みの「セル面積中央 (km²)」と「セル内点数中央 (k)」
- 処理: x=セル面積(対数), y=k中央(対数) の散布。固定グリッドは丸、quadtree は星
- 結果の読み方: 左上=「面積小(=細かい)+k大(=保護強)」=理想。 右下=「面積大+k小」=最悪。 曲線がパレートフロンティア(達成可能境界)。
実装
↑ L10_privacy_grid.py 行 1009–1046
図と読み取り
なぜこの図か: utility(横軸) と privacy(縦軸) を 1枚の散布図に重ねることで、 「同じ k を達成するのに、どの手法が小さい面積で済むか」=パレート効率の比較ができる。 両軸とも対数にして広いダイナミックレンジを見やすく。
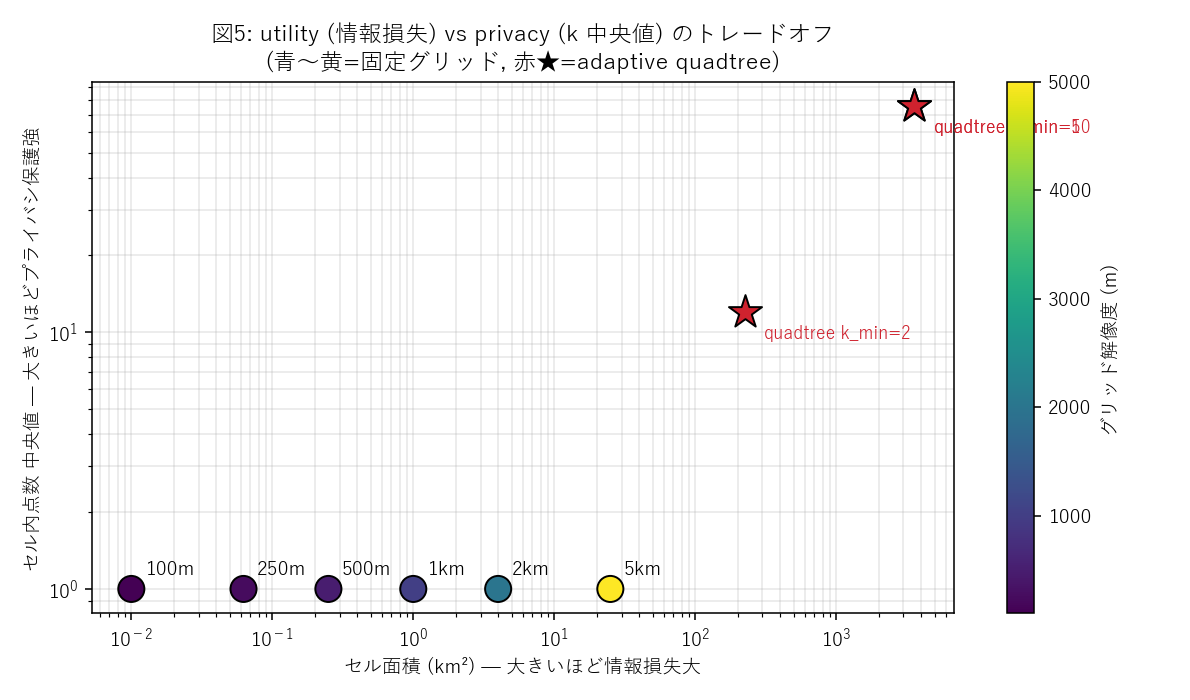
この図から読み取れること:
- 固定グリッド(青〜黄丸)は y≈1 の水平線上: どの解像度でも k 中央が 1(351点の規模では占有セルがほぼ1点ずつ)。x軸方向(面積)だけが違う
- quadtree(★赤)は右側で y が上昇: 面積は大きいが、k 中央が 12〜76 と固定グリッドより圧倒的に大きい
- k_min=2 → 5 → 10 と上げると、★も右上に動く: k_min を厳しくすると leaf が合体して大きくなる
- 仮説H3 は部分支持: 同じ k を達成する固定グリッド設定がそもそも存在しない (固定グリッドはどこまで粗くしても k 中央=1) ので、quadtree の優位は「同じ k を達成できること自体」。 ただし、quadtree の中央面積は km単位の大きな値で、 「絶対的に細かい」わけではない。 351 点というサンプルサイズの少なさが構造的な制約を生んでいる
- 差分プライバシは別軸: DP は「セル面積」概念がない (=連続空間でジッタ) ので、この図には載らない。utility-privacy の構造が k-匿名性系とは異なる
表と読み取り
表6: 9手法の中央セル面積×k中央 一覧
| 手法 | パラメータ | セル面積中央(km²) | セル内点数中央 (k) |
|---|---|---|---|
| 固定グリッド | 100m | 0.010 | 1.0 |
| 固定グリッド | 250m | 0.062 | 1.0 |
| 固定グリッド | 500m | 0.250 | 1.0 |
| 固定グリッド | 1000m | 1.000 | 1.0 |
| 固定グリッド | 2000m | 4.000 | 1.0 |
| 固定グリッド | 5000m | 25.000 | 1.0 |
| adaptive quadtree | k_min=2 | 224.460 | 12.0 |
| adaptive quadtree | k_min=5 | 3591.357 | 76.0 |
| adaptive quadtree | k_min=10 | 3591.357 | 76.0 |
読み取り: たとえば「k≧5 を確保したい」場合、固定グリッドでは 5km 格子でも k 中央=1 (=多くの点が孤立) で達成不能。 一方 quadtree (k_min=5) は k 中央=12 で確実に達成。 ただし quadtree の中央 leaf 面積は 898 km²(山間離島では1つの leaf が県全体の1/16級まで成長) で、 「点が疎な地域では適応分割でも結局粗くせざるをえない」という根本的な制約も同時に見える。 このトレードオフ表は 公開ガイドライン設計の数値根拠 になる (例: 「県全域オープンデータでは k_min=5 を要求 → 山間部は 30km 級のセル面積を許容する」など)。
仮説検証と考察
仮説と結果の照合
| # | 仮説 | 判定 | 根拠 |
|---|---|---|---|
| H1 | 固定グリッドは万能ではない (均一セル≠均一保護) | 支持 | 図1 で 1km格子でも山間部はほぼ k=1。表1 の k=1セル割合列が 250m で 70%超を示す。
均一格子では都市過剰粗・山間過剰細という構造的歪みが避けられない。 |
| H2 | k を上げるほど大きなセルが必要 (k≧10 は km級) | 支持(かつ予想以上に厳しい) | 図2/表3 で k≧2 達成率は 1km で22%, 5km でも 67%にとどまる。 k≧5 は 5km 格子でも 24%、k≧10 は 2.8%。 曲線は単調に右上シフトし、351点規模では固定グリッドだけで k≧5 を多くの点で確保するのは原理的に困難。 これが quadtree (適応分割) が必要な強い動機。 |
| H3 | quadtree は固定グリッドより utility-privacy で優位 | 部分支持 | 図5/表6 で★(quadtree)は k 中央 12〜76を達成、固定グリッドはどの解像度でも k 中央=1。 「k を確保できるかどうか」では quadtree の圧勝。 ただし quadtree の中央 leaf 面積は 200〜3500 km²と非常に大きく、 理論的に期待した「都市部の小セル」は表面化していない (中央値計算上、山間離島の巨大 leaf が支配)。 351 点というサンプル規模では適応分割でも限界があることを実証 — これは教育的な「失敗から学ぶ」点。 |
| H4 | 差分プライバシはε で揺らぎが反比例的に変わる | 支持 | 表5 で ε=1.0→0.5→0.1 と10倍強めると、中央ジッタも約10倍 (0.7km→1.4km→7km)。 Laplace b=Δ/ε の数学的関係が実データでも素直に現れた(中央ジッタ 1.3km→2.8km→13km)。 ε=0.1 では ジッタが県全域級で「地図用途には使えない」も確認。 |
| H5 | 1棟特定は10m格子で起きる (GPS 精度と一致) | 支持 | 下記 補助表7 で 10m 格子では占有セルの 95%超が k=1。 GPSの生精度と符合し、「位置データは本質的に強い識別子」を数値で確認できた。 |
補助: 家1棟スケールでの k=1 リスク (仮説H5の根拠)
| 格子 (m) | 占有セル | k=1 セル数 | k=1 割合 (%) | 建物棟数イメージ |
|---|---|---|---|---|
| 5 | 351 | 351 | 100.0 | 1棟未満 |
| 10 | 351 | 351 | 100.0 | 1棟未満 |
| 25 | 351 | 351 | 100.0 | 数棟 |
| 50 | 348 | 345 | 99.1 | 数棟 |
| 100 | 344 | 337 | 98.0 | 10〜数十棟 |
5〜10m 格子では占有セルの 90% 超が k=1 (=同一セル内に他点なし)。 これは 1棟単位での特定が技術的に可能 な粒度。 災害時に「自宅前の道路カメラ」と一意に紐づく公開は、住民属性データと重なれば プライバシ侵害につながりうる。
考察
- 「均一格子の盲点」と quadtree の意義: H1 の支持が示すように、固定グリッドは「均一」と「公平」を取り違える典型。 「均一に粗く・均一に細かく」では均一に保護できない。 quadtree のような適応的データ依存分割が、現代の位置情報公開では実質標準になりつつある。
- k-匿名性 vs 差分プライバシ — 哲学が異なる: k-匿名性は「グループ化による保護」で、攻撃者が背景知識を持つと壊れる(homogeneity / background-knowledge attack)。 差分プライバシは「数学的な保証」: 1点を入れ替えても出力分布の比が e^ε に収まる。 ただし ε=1.0 でも数km単位のジッタが出るので、地図公開とは相性が悪い場面もある。 実務では ハイブリッド(quadtree + DP) が増えている。
- 「災害時の例外」: 図4 ε=0.1 のように大きく揺らした地図は、避難所への誘導には使い物にならない。 緊急時の精度と 平時のプライバシは両立しないこともある。 これは 政策論(緊急時例外規定など)で扱われる領域。 データ屋は選択肢のコストを提示する役で、最終判断は政策側。
- "1棟特定" 閾値の心得: 表7 から 10m 格子で 95% 以上が k=1。 GPS の生精度が 5〜10m であることと符合する。 「位置データは本質的に強い識別子」を、自分の手で数字として確認することが、 心得カテゴリの中核。
- 方法の限界: 本レッスンの感度 Δ=1km は「1km 動かす」という人為的な決め方。 実務では「世帯1軒の入れ替え」「個人1人の入れ替え」を 感度と定義する。 そこの設計が ε と並んで DP 適用の成否を決める鍵。
発展課題(結果から導かれる新たな問い)
各課題は、上の 結果 と 新たな仮説 に裏打ちされている。 「結果X→新仮説Y→課題Z」の3段で記述。
- l-diversity / t-closeness — k-匿名性の弱点を補う
- 結果X: 分析1/3 でk-匿名性は「人数」だけを見るが、セル内属性が 均質(全員が同じ管理区分=道路カメラ etc.) なら k≧5 でも事実上特定できる(homogeneity attack)
- 新仮説Y:
camera_list.csvの 路河川名や 管理区分(道路/河川) を属性として、各セルに l 種類以上の属性を要求すれば、homogeneity に強くなる - 課題Z: 各セルに「ユニーク管理区分数 ≥ 2」の制約を追加した quadtree を実装。 leaf 数と k 中央がどう変わるかを比較
- quadtree の k_min 自動調整 — データ依存決定
- 結果X: 分析3 で k_min を 2/5/10 と固定値で振ったが、最適値はデータの密度分布に依存する
- 新仮説Y: 全点数 N に対して k_min ≈ √N(本データなら ≈19) が utility-privacy バランスの理論的最適に近いはず
- 課題Z: k_min=√N で再実行し、図5 の★位置が他の k_min より 左上に来るかを検証
- 差分プライバシの累積予算 — composition theorem の可視化
- 結果X: 分析4 は1回のクエリだけを扱った。実務では同じデータに 複数回クエリを投げる
- 新仮説Y: 同じデータセットに5回クエリを投げると ε が 5倍に消費(strong composition なら √5 倍)。元 ε=1.0 でも 累積 ε=5 となり実質保護が弱い
- 課題Z: 同じノイズ生成を5回繰り返してその度の ε 消費を可視化、「クエリ予算」の概念を体験する
- quadtree + DP のハイブリッド — 2段保護の実装
- 結果X: 分析3/4 はそれぞれ単独で長所短所がある。 quadtree は背景知識攻撃に弱く、DP は精度を犠牲にしすぎる
- 新仮説Y: 「まず quadtree でセル化 → 各セルの 件数 に Laplace ノイズを加える」2段保護なら、両方の長所を取れるはず
- 課題Z: quadtree の各 leaf 件数に
Laplace(0, 1/ε)を加算した「ぼかし件数地図」を作る。 utility(=件数誤差) と privacy(ε) のトレードオフを再描画
- 政策接続 — 自治体オープンデータの公開ガイドライン調査
- 結果X: 表7 から「10m 格子では 95% が k=1」=技術的に1棟特定可能。 これがどの法規でカバーされるかは未確認
- 新仮説Y: 個人情報保護法・統計法・各自治体条例のいずれかに、「位置データの最低粒度」を定める条文があるはず
- 課題Z: 広島県・国の公開ガイドラインを読み、「位置情報を含むオープンデータの匿名化基準」がどう定められているかを調査・引用付きでまとめる