カメラ → 最寄り避難所 — BallTree(haversine) で災害時モニタリング適性を評価
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #42 | 避難所情報 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1279 | 県内のカメラ情報 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L09_nearest_camera.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
このレッスンで答えたい問い
「広島県の防災カメラ351台は、災害時に最寄り避難所をどれくらい近くから見守れるか? そして、その近さは災害種別・カメラ管理区分・地理位置でどう変わるか?」
用語の定義(このレッスン独自)
- 「カメラ」: DoBoX #1279 に登録された 広島県の防災カメラ 351台(道路・河川・ため池・海岸など)。 ライブ映像を配信できる固定地点。緯度経度と「管理区分」を持つ。
- 「避難所」: DoBoX #42 の 指定避難所 4,065件。各避難所に災害種別フラグ(洪水/土砂/高潮/地震/津波)が付与されており、 その災害時に開設対象になるかが分かる。
- 「最寄り距離」: 2点間の 地球表面上の直線距離(haversine 距離, km)。 道路距離ではなく球面上の最短距離。
- 「孤立カメラ」: 最寄り避難所までの距離が 5km を超えるカメラ(本レッスンの定義)。 「映像を撮っても、近くに人々が集まる避難所がない」状態。
- 「カバレッジ」: あるカメラが半径 d km 以内に 何個の避難所を持っているか。 1個だけでは故障時に代替が効かないため、k=3 や k=5 で「冗長性」を測る。
- 「BallTree」: 大量の点の中から 「最寄り N 個」を高速に取り出すデータ構造。 ツールとして使う:点群を入れて木を作り、別の点を投げると最寄り N 個が返る。内部の球面三角法は黒箱でOK。
- 「haversine(ハーバサイン)距離」: 緯度経度の2点間の地球表面距離を計算する公式の名前。 道路距離ではなく球面上の直線距離(メートル単位の正確な距離)。本レッスンでは BallTree のオプションとして指定するだけで使える。
- 「ECDF」: Empirical Cumulative Distribution Function = 累積分布関数。 「距離 d 以内に何 % のカメラが入るか」を d を横軸に取って積み上げたグラフ。 ヒストグラムが「区間ごとの個数」なら、ECDF は「閾値以下の割合」を表す。複数カテゴリの分布を 1枚で重ねて比較できるのが利点。
立てた仮説
- H1(最寄り距離は十分に近い): 広島県のカメラ網は密に整備されているはず。 カメラ→最寄り避難所の 中央値は 1km 以下、95%値も数km 以内に収まると予想。 ただし右に長い裾を持ち、山間部・島嶼部に「孤立カメラ」が少数存在するはず。
- H2(災害種別で見える避難所が違う): 津波・高潮対応避難所は 沿岸偏在のため、 山間部のカメラから見ると最寄りでも遠くなるはず。 逆に洪水・土砂対応は内陸全域にあるため、すべてのカメラから近いはず。 同じカメラでも「対応災害」のフィルタ次第で実用価値が変わる。
- H3(冗長性は近距離で急減する): 「最寄り 1個(k=1)」が 1km 以内に入るカメラは多くても、 「3個まとめて 1km 以内(k=3)」に入るカメラは大幅に少ないはず。 1台が故障した瞬間に代替手段がない地域が浮かび上がる。
- H4(カメラ起点 vs 避難所起点 は非対称): 351台のカメラと 4,065件の避難所では、 母数が10倍以上違うため、カメラ→避難所(n=351)と避難所→カメラ(n=4065)の最寄り距離分布は形が大きく違うはず。 避難所側はカメラを持たない山地・離島が多く、長距離の裾が厚くなる。
- H5(管理区分で距離分布が違う): カメラの管理区分は道路・河川・ため池・海岸ほか で、 それぞれ 立地ロジックが違う。 道路カメラは集落間の長い県道・国道沿いに点在するため避難所まで遠いペアが混じる一方、 河川・海岸ほか は集落隣接の被害想定地点に置かれ、避難所と隣接しやすい。 区分間で距離分布の中央値に有意差があるはず(Kruskal-Wallis 検定で確認)。
到達点
- 5仮説に対して、5つの分析でそれぞれ 支持/反証/部分支持 を判定できる
- BallTree(haversine) という「最寄り N 個」を引くツールを 使える ようになる(中身の数式は不問)
- 距離分布を ヒストグラム / ECDF / カバレッジ曲線 / 箱ひげ で多角的に可視化できる
- Kruskal-Wallis 検定でカテゴリ間の中央値差の有意性を判定できる
- 「カメラ起点 vs 避難所起点」の 非対称性 を理解し、「どちらをクエリにするか」で問題定義が変わる感覚を持つ
使用データ
- 名称1 防災カメラ一覧(広島県)
- 件数 351台
- 取得元 DoBoX #1279
- 列 No., カメラ名, 住所, 路河川名等, 緯度, 経度, 公開URL, 所管, 管理区分
- ファイル
data/camera_list.csv(UTF-8-BOM, 約 70 KB)
- 名称2 指定避難所(広島県)
- 件数 4,065件
- 取得元 DoBoX #42
- 主な列 name, latitude, longitude, municipalityName, floodShFlg / sedimentDisasterShFlg / stormSurgeShFlg / earthquakeShFlg / tsunamiShFlg (5つの災害種別フラグ, 0/1), capacity, 福祉系フラグ群
- ファイル
data/shelters.json(UTF-8, 約 4 MB)
本レッスンは 2データセットを「位置で結合」する空間結合の典型例。 2つのデータには共通IDがないため、テーブル JOIN ではなく 「最寄り点を引く」ことで結合する。
ダウンロード(再現用データ・中間データ・図)
本レッスンの全成果物に直リンクを置いた。途中ステップから再現したい学習者向け。
1. 生データ(DoBoX 由来)
| ファイル | 形式 | サイズ | 取得元 |
|---|---|---|---|
data/camera_list.csv |
CSV (緯度・経度・住所・管理区分) | 約 70 KB / 351 行 | DoBoX #1279 |
data/shelters.json |
JSON (4,065 items, 災害5フラグ付) | 約 4 MB | DoBoX #42 |
2. プログラムで生成される中間データ(CSV 直リンク)
| ファイル | 内容 | 使う分析 |
|---|---|---|
L09_nn_distances.csv |
351カメラ × (最寄り避難所名・市区町村・距離km) | 分析1 ヒスト / 分析5 マップ |
L09_topk_distances.csv |
351カメラ × k=1..5 番目に近い避難所までの距離行列 | 分析3 カバレッジ |
L09_distances_by_hazard.csv |
5災害種別 × 351カメラ の最寄り対応避難所距離(縦持ち) | 分析2 ECDF |
L09_topk_coverage.csv |
k×半径dの 2D 表(カバレッジ曲線の元データ) | 分析3 カバレッジ |
L09_shelter_to_camera.csv |
4,065避難所 × 最寄りカメラ距離(逆方向) | 分析4 非対称性 |
L09_category_summary.csv |
管理区分4区分の集計(n, 中央値, p95, max, 孤立数) | 分析5 KW検定 |
3. 図 PNG / インタラクティブマップ
- L09_hist.png — 分析1: 最寄り距離ヒストグラム
- L09_ecdf_hazard.png — 分析2: 災害種別 ECDF
- L09_topk_coverage.png — 分析3: top-k カバレッジ曲線
- L09_reverse_compare.png — 分析4: 逆向き比較
- L09_isolated_map.png — 分析5: 孤立カメラ地理マップ
- L09_box_kw.png — 分析5: 管理区分別箱ひげ + KW
- L09_map.html — folium インタラクティブマップ(要ブラウザ表示)
4. 再現スクリプト
cd "2026 DoBoX 教材"
py -X utf8 lessons/L09_nearest_camera.pyスクリプト本体: lessons/L09_nearest_camera.py
分析1: カメラ→最寄り避難所の距離分布
狙い
「広島県の351台の防災カメラは、最寄り避難所までどれくらい近いか?」 分布の中央値・95%値・最大値を見て、整備密度の全体像を把握する(仮説H1)。
使う道具: BallTree(haversine)
役割(一文で): 大量の点の中から「最寄り N 個」を高速に取り出すツール。 中身は「点を木構造に整理しておくと、新しい点を投げたときに端から全部測らなくて済む」というアイデア。 本レッスンでは 使い方だけを覚える。内部の球面三角法・木の構築アルゴリズムは黒箱でOK。
| ステップ | このツールの操作 | 入力 | 出力 |
|---|---|---|---|
| 準備 | BallTree(点群, metric="haversine") で「木」を作る |
避難所4,065件のラジアン座標 (4065×2) | 木オブジェクト1つ |
| クエリ | tree.query(別の点群, k=N) で N 個の最寄りを取る |
カメラ351台のラジアン座標 (351×2) | 距離行列 (351×N) と インデックス行列 (351×N) |
注意点 3つ:
- (1) ラジアン変換が必要: haversine 距離は緯度経度を ラジアン単位で受け取る。
np.radians()で度→ラジアン。 - (2) 単位はラジアン距離: 返ってくる距離もラジアン。地球半径 6371 km を掛けて km に直す。
- (3) 道路距離ではない: 球面上の直線距離なので、山岳部の実際の徒歩・自動車距離より 短く出る。実距離に直したいなら OSRM などのルーティング API が必要(発展課題)。
1台のカメラがどう距離を得るか — 最初から最後まで追う表(カメラ「苗代」の例)
カメラ #1「苗代」(呉市苗代町)が、避難所4,065件の中から最寄り1件を引いて km 距離を得るまでの流れ。 1台のカメラに対する操作を 段階ごとに追う。
| 段階 | このカメラで何が起きるか | サイズ |
|---|---|---|
| ① 緯度経度を取得 | (34.297405, 132.592275) を CSV から読む | 1×2 の度数値 |
| ② ラジアン変換 | (0.59866, 2.31416) ラジアンに変換 | 1×2 のラジアン値 |
| ③ 木にクエリ | tree_sh.query([[0.59866, 2.31416]], k=1) を呼ぶ | クエリ点 1×2 を投げる |
| ④ 木の内部処理 | 4,065件の避難所を全件比較せず、近そうな候補だけ計算(黒箱) | — |
| ⑤ ラジアン距離が返る | 0.0000567 ラジアン と インデックス 1234 を返す | 距離 1個 + index 1個 |
| ⑥ km に直す | 0.0000567 × 6371 = 0.36 km | 1スカラー |
| ⑦ インデックスから避難所名 | sh.iloc[1234] で「苗代住吉神社」「呉市」を取得 | 1行 |
| ⑧ 結果を保存 | カメラ「苗代」→ 最寄り避難所「苗代住吉神社」(呉市, 0.36km) | 表に1行追加 |
※ 緯度経度は実データ。距離値は概念的な例(実行結果は L09_nn_distances.csv で確認可)。
これを 351 台すべてで一気に行うのが tree.query(cam_rad, k=1) の中身。
このツールの限界
- 直線距離のみ: 山・川・建物を無視した球面上の最短。実走行距離との乖離は山間部で大きい
- 「点」しか扱えない: 道路ネットワーク・川の流路を考慮した距離は別ツール(OSRM, NetworkX)
- k 個ぴったり返る: 半径 d km 以内に「あるだけ全部」が欲しい時は
query_radiusという別関数を使う - パラメータ:
metric="haversine"必須(地球用)。leaf_sizeは速度調整用で精度には影響なし
実装
結果(図と読み取り)
なぜこの図か: 連続値の偏りを直感的に見たいから ヒストグラム。 中央値(赤)と 95%値(橙)の縦線を加えて、「典型的なカメラ」と「外れ値カメラ」の境界を視覚化する。
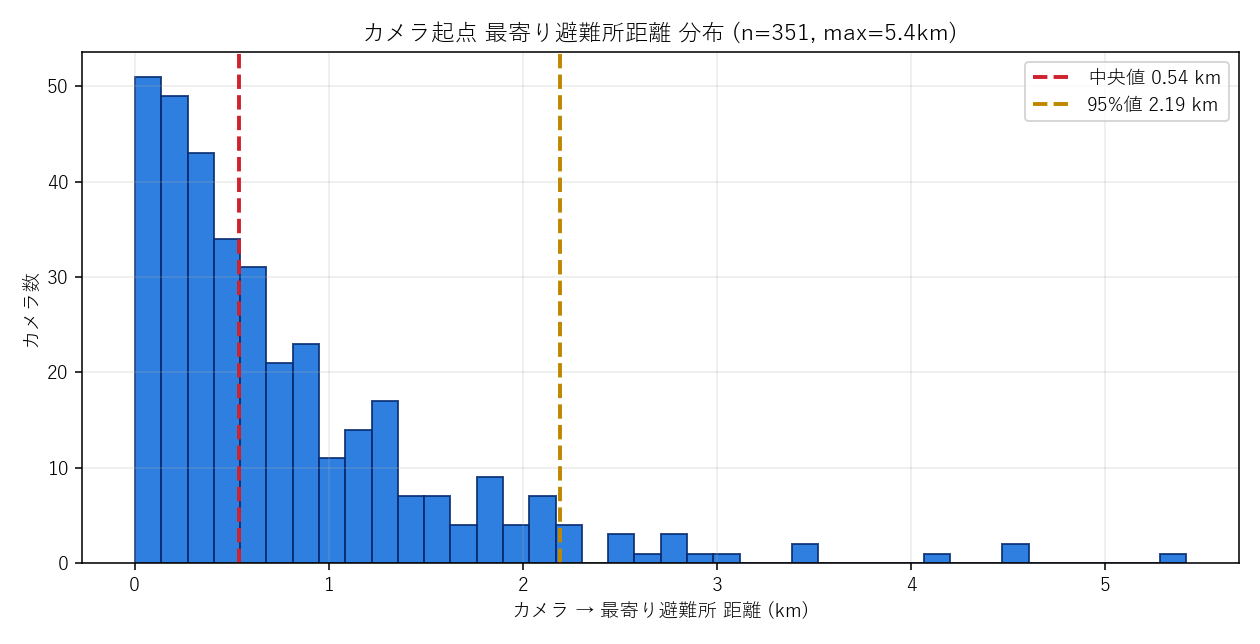
この図から読み取れること:
- 中央値は 0.54 km — 大半のカメラは避難所まで 1km 以下、徒歩圏内。広島県のカメラ網は密に整備されている → 仮説H1の前半(中央値1km以下)を支持
- 分布は強い右の長尾 — 大半は 0–1km に集中するが、95%値で 2.19km、最大 5.42km まで伸びる
- 「平均値だけで語ると誤る」: 裾の重い分布では中央値 + 95%値 + 最大値の三点セットで報告するのが鉄則
結果(表と読み取り)
なぜこの表か: ヒストグラムの「右の裾」に何があるかを具体的なカメラ名で確認する。
表1: カメラから最も遠い避難所 TOP10(孤立候補)
| カメラ名 | 住所 | 管理区分 | 距離(km) | 最寄り避難所 | 市区町村 |
|---|---|---|---|---|---|
| 智教寺 | 安芸高田市美土里町生田 | 道路 | 5.42 | 生田集会所 | 安芸高田市 |
| 飯山 | 廿日市市飯山 | 道路 | 4.56 | 第一集会所 | 廿日市市 |
| 吉和(R434別れ) | 廿日市市吉和 | 道路 | 4.55 | 第一集会所 | 廿日市市 |
| 羽出庭 | 三次市三和町羽出庭 | 道路 | 4.13 | 三次市三和支所 | 三次市 |
| 西城油木 | 庄原市西城町油木 | 道路 | 3.49 | 前油木老人集会所 | 庄原市 |
| ため池カメラ(鳥屋ヶ森) | 広島市安佐北区可部町大字綾ヶ谷 | ため池 | 3.39 | 可部運動公園管理事務所 | 広島市安佐北区 |
| 三和 | 三次市三和町上壱 | 道路 | 3.04 | 三次市立三和中学校 | 三次市 |
| ため池カメラ(奥桧山) | 広島市安佐北区大林町 | ため池 | 2.86 | 三入東学区集会所 | 広島市安佐北区 |
| 便坂トンネル西 | 三次市作木町上作木 | 道路 | 2.79 | 布野生涯学習センター | 三次市 |
| 雲通 | 三次市吉舎町雲通 | 道路 | 2.78 | 三次市立八幡小学校 | 三次市 |
この表から読み取れること: 上位は山間部・島嶼部・海岸線のカメラに偏る。「ため池」「海岸ほか」管理のカメラが多い — 管理区分との関連は分析5で検証する。
分析2: 災害種別ごとの「対応避難所」最寄り距離
狙い
「同じカメラでも、対応災害が違うと最寄り避難所までの距離は変わるか?」 津波・高潮対応避難所は沿岸偏在のため、山間部のカメラから遠いはず(仮説H2)。
使う道具: ECDF(累積分布関数)
役割(一文で): 「距離 d 以下のカメラの割合」を d を横軸に取って積み上げたグラフ。 ヒストグラムが「区間ごとの個数」を縦に積むのに対し、ECDF は「閾値以下の割合」を 0%→100% に向かって右肩上がりにする。
なぜここで ECDF か: 5つの災害種別を同じ図に重ねたい。 ヒストグラムを5つ重ねると棒が混ざって読めないが、ECDF は 線なので5本重ねても識別できる。 さらに「中央値は何km か」(曲線が y=0.5 を横切る x 値)が一目で分かる。
動作のイメージ:
- カメラごとの距離(例: 351個の数値)をソートする
- x軸 = 距離、y軸 = 「この距離以下のカメラの割合(1/n, 2/n, ..., n/n)」を階段状にプロット
- 曲線が左上にあるほど「短い距離で多くがカバーされる」=その災害には強い整備
処理の流れ(5災害ループ):
| ステップ | 操作 | サイズ |
|---|---|---|
| ① 災害フラグでフィルタ | 避難所4065件 → flag=1 の部分集合 | 例: 洪水避難所 ≒ 3千件 |
| ② BallTree 構築 | その部分集合だけで木を作る | 木1つ(災害ごと) |
| ③ 351カメラで query | tree.query(cam_rad, k=1) | 距離 351個 |
| ④ ECDF 計算 | 距離をソートして 1/n, 2/n, ... の階段関数 | (351点, 351点) |
| ⑤ 5災害ぶんを重ね描き | 線色を災害ごとに変えて step plot | 1枚の図 |
実装
↑ L09_nearest_camera.py 行 698–741
結果(図と読み取り)
なぜこの図か: 5本の分布を 1枚で比較したい。線が左にあるほど短距離で多くカバー。 y=0.5 の補助線で中央値、y=0.95 で 95%値が読める。
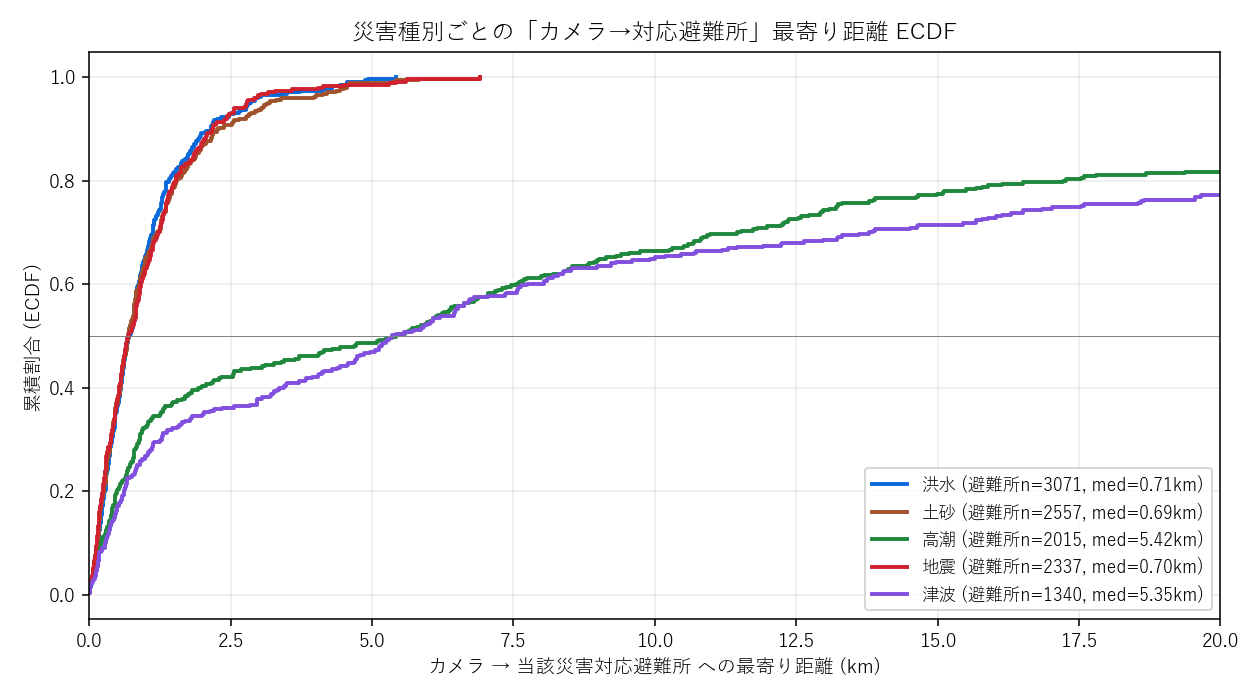
この図から読み取れること:
- 洪水・土砂・地震 はほぼ重なる: 内陸全域に対応避難所があり、どの災害でもカメラからの最寄りは同じくらい近い
- 津波・高潮 は右にずれる: 対応避難所が 沿岸偏在のため、山間部のカメラから見ると遠くなる → 仮説H2を支持
- 「同じカメラ」でも災害種別フィルタで実用価値が変わる: 内陸の山間カメラは津波避難所からは遠いが、土砂避難所からは近い
結果(表と読み取り)
表2: 災害種別 サマリ(避難所数 / 中央値 / 95% / 最大)
| 災害 | 対応避難所数 | 中央値(km) | 95%値(km) | 最大(km) |
|---|---|---|---|---|
| 洪水 | 3071 | 0.71 | 2.81 | 5.42 |
| 土砂 | 2557 | 0.69 | 3.14 | 6.91 |
| 高潮 | 2015 | 5.42 | 35.02 | 58.54 |
| 地震 | 2337 | 0.70 | 2.78 | 6.91 |
| 津波 | 1340 | 5.35 | 38.19 | 57.78 |
この表から読み取れること: 津波・高潮の中央値・95%値が他の3災害より明確に大きい。 「対応避難所数」も津波が最少。避難所の絶対数と 沿岸偏在の二重効果で距離が伸びている。
分析3: top-k カバレッジ曲線(冗長性の評価)
狙い
「最寄り1個だけでなく、3個・5個まとめて何 km 以内にあるか?」 1個だけでは故障時に代替が効かない。災害インフラの「冗長性」を可視化する(仮説H3)。
使う道具: BallTree の k=多 クエリ
1個だけ(k=1)でなく、k=3 や k=5 の最寄りを一気に取るのが BallTree のもう1つの強み。 返ってくるのは 距離行列 (351×k)。j 列目は「j 番目に近い避難所までの距離」。
| k=1 (最寄り1個) | k=3 (3個目) | k=5 (5個目) |
|---|---|---|
| 「最寄り避難所」までの距離 | 「3つ揃えるのに必要な半径」 | 「5つ揃えるのに必要な半径」 |
| 近いほど通常運用◎ | 近いほど1台壊れても安全 | 近いほど多重冗長 |
カバレッジ曲線の作り方:
- 半径 d を 0.5km から 10km まで 40 点でスキャン
- 各 d について「k 番目に近い避難所までの距離が d 以下のカメラ」の割合を計算
- x=d, y=割合(%) でプロット。k=1, 3, 5 を別線色で重ね描き
実装
↑ L09_nearest_camera.py 行 760–791
結果(図と読み取り)
なぜこの図か: 「半径」を変えながら「カバー率」を見る 感度分析。 3線を重ねることで「k を増やすと曲線がどれだけ右にずれるか」=冗長性のコストが分かる。
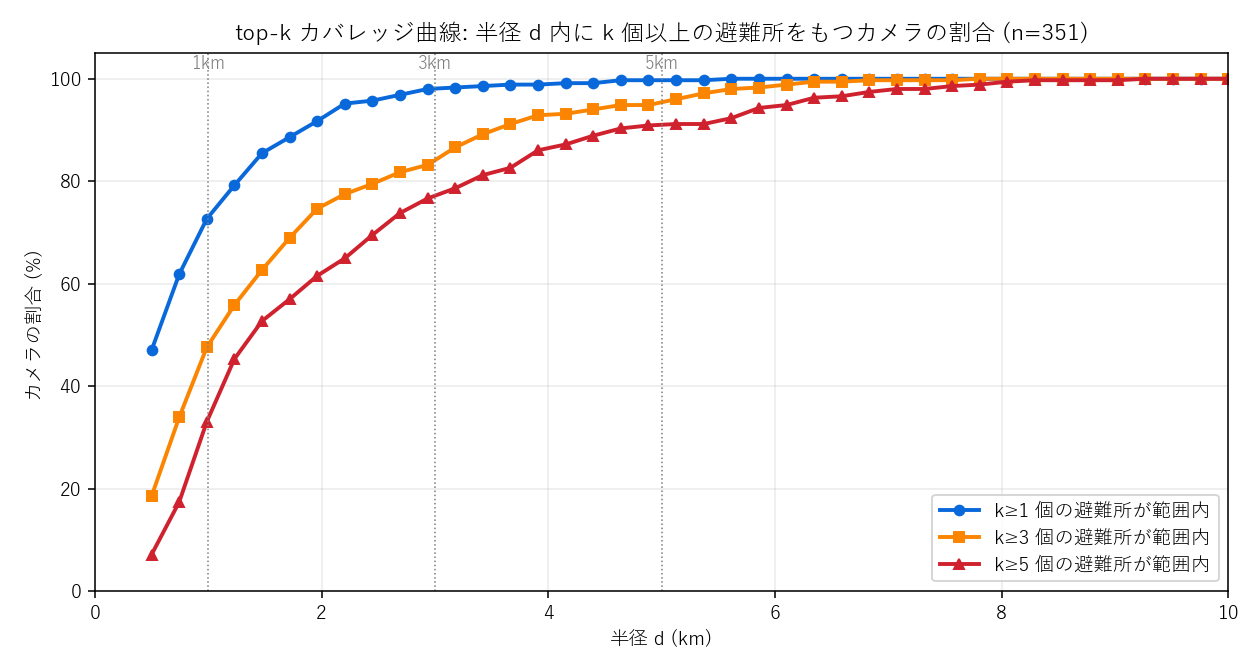
この図から読み取れること:
- k=1 は急速に立ち上がる: 1km で大半のカメラが最寄り1個を確保
- k=3 で曲線は右シフト: 同じ d=1km でカバー率は半減程度。「3個揃えるには倍以上の半径が必要」
- k=5 はさらに右: 「5個まとめて 1km 以内」のカメラは少数派 → 仮説H3を支持
- 政策的意味: 「最寄り1個に頼ると故障時に脆弱」。k=3 の曲線が低い距離域でこそ追加整備が必要な地域を示唆
結果(表と読み取り)
表3: 主要半径での top-k カバレッジ(カメラの何 % が条件を満たすか)
| k | d=1km | d=3km | d=5km |
|---|---|---|---|
| 1 | 72.6% | 98.0% | 99.7% |
| 3 | 47.6% | 83.2% | 94.9% |
| 5 | 33.0% | 76.6% | 90.9% |
この表から読み取れること: 同じ d=1km でも k=1 と k=3 ではカバー率が大きく違う。 1km 圏内に 3個の避難所を持てるカメラは限定的で、「冗長な見守り体制」は地理的に均等ではないことが定量化できた。
分析4: 避難所→最寄りカメラ(逆方向の比較)
狙い
「カメラ起点(n=351)と避難所起点(n=4065)では、最寄り距離分布はどう違うか?」 「クエリ側を入れ替える」だけで問題定義が変わることを実演する(仮説H4)。
使う道具: BallTree の役割を入れ替える
分析1〜3 では 避難所側の木にカメラを投げた(カメラ視点)。 分析4 では カメラ側の木に避難所を投げる(避難所視点)。木の構築先が入れ替わるだけ。
| 分析の方向 | 木に入れる点群 | クエリする点群 | 意味 |
|---|---|---|---|
| カメラ→避難所 (分析1) | 避難所 4,065件 | カメラ 351台 | 「各カメラが何をモニタできるか」 |
| 避難所→カメラ (分析4) | カメラ 351台 | 避難所 4,065件 | 「各避難所は映像で見守られているか」 |
n が10倍以上違うので結果も大きく非対称になる。 カメラ351台に対して4,065件の避難所すべてに「最寄り1台のカメラ」を割り当てると、必然的に 遠いペアが大量発生する。
実装
↑ L09_nearest_camera.py 行 813–832
結果(図と読み取り)
なぜこの図か: 同じ「最寄り距離」でも母数が違う2分布を 1枚で重ねると非対称性が一目で分かる。 ビン幅を揃えてある(同じ x 軸)ので、形状の違いが面積比較できる。
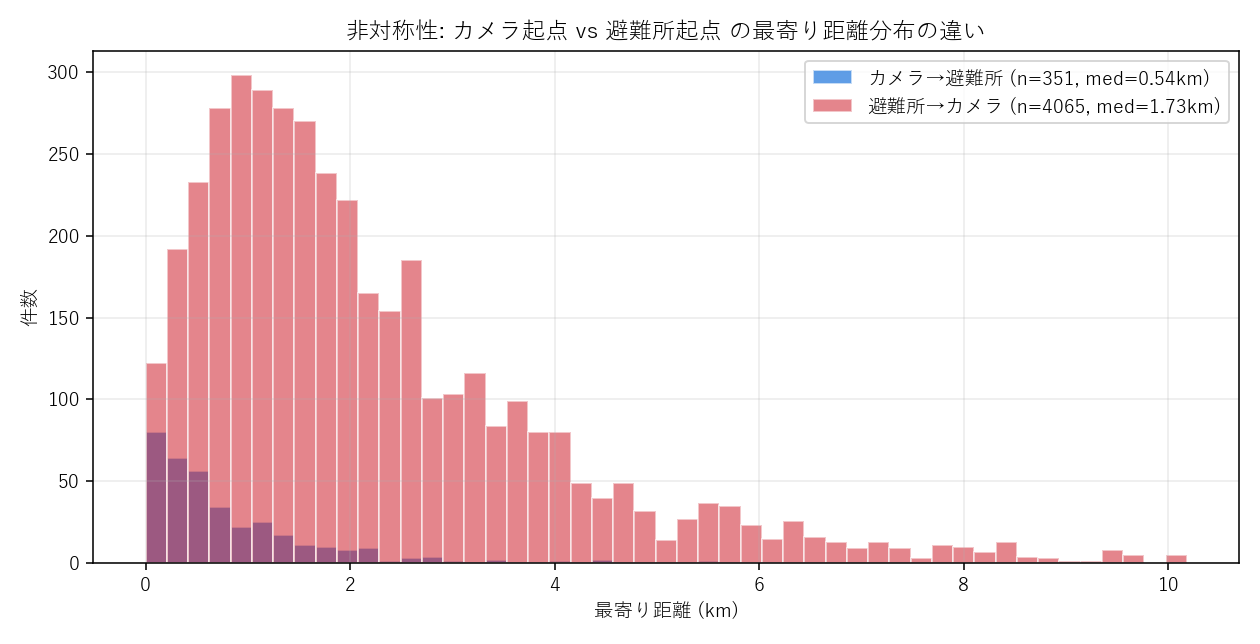
この図から読み取れること:
- 避難所起点 (赤) は右に長い裾: 4,065件の避難所のうち、最寄りカメラまで遠い避難所が多数 — カメラを持たない山地・離島の避難所が多い
- カメラ起点 (青) は左に集中: 351台のカメラはどれも最寄り避難所が近い
- 中央値の差: カメラ起点 0.54km vs 避難所起点 1.73km — 仮説H4を支持
- 本質: 「どちらをクエリにするか」で問題定義が変わる。「カメラの実用性」と「避難所のモニタ可否」は別の問い
分析5: 孤立カメラ地理マップ + 管理区分別 Kruskal-Wallis 検定
狙い
(A) 「孤立カメラはどこに集中するか?」 — 地理プロットで可視化。
(B) 「管理区分(道路/河川/ため池/海岸ほか)で距離分布は違うか?」 — 仮説H5を Kruskal-Wallis 検定で判定。
使う道具: 孤立判定 + Kruskal-Wallis 検定
(A) 孤立判定: 分析1で計算済みの最寄り距離に対し、5km 超を「孤立」、2km 超を「準孤立」(95%値ライン)と定義。 散布図を経度・緯度で描き、3カテゴリを色・形・サイズで分けて重ねる。背景に避難所を薄灰色で。
(B) Kruskal-Wallis 検定: 「複数グループの中央値が同じか?」を判定する ノンパラメトリック検定。
- ノンパラメトリック = 「正規分布である」などの仮定を置かない。距離分布のような 右に偏った分布でも使える(t検定や分散分析は正規性を仮定するため不適)
- 入力: 4グループそれぞれの距離リスト(道路n=?, 河川n=?, ため池n=?, 海岸ほかn=?)
- 出力: 検定統計量 H と p 値
- 判定: p < 0.05 なら「グループ間で中央値に有意差あり」
- 限界: 「どのグループ間で差があるか」までは分からない(ペア比較は別途 Mann-Whitney U など)
実装
結果A(図と読み取り)— 孤立カメラの地理分布
なぜこの図か: 「孤立カメラがどこに偏在するか」は 地図を見れば一発。 3カテゴリを色・サイズ・形で同時にエンコードし、避難所を背景に薄く描くことで「カメラと避難所の 密度の地理的ミスマッチ」が見える。
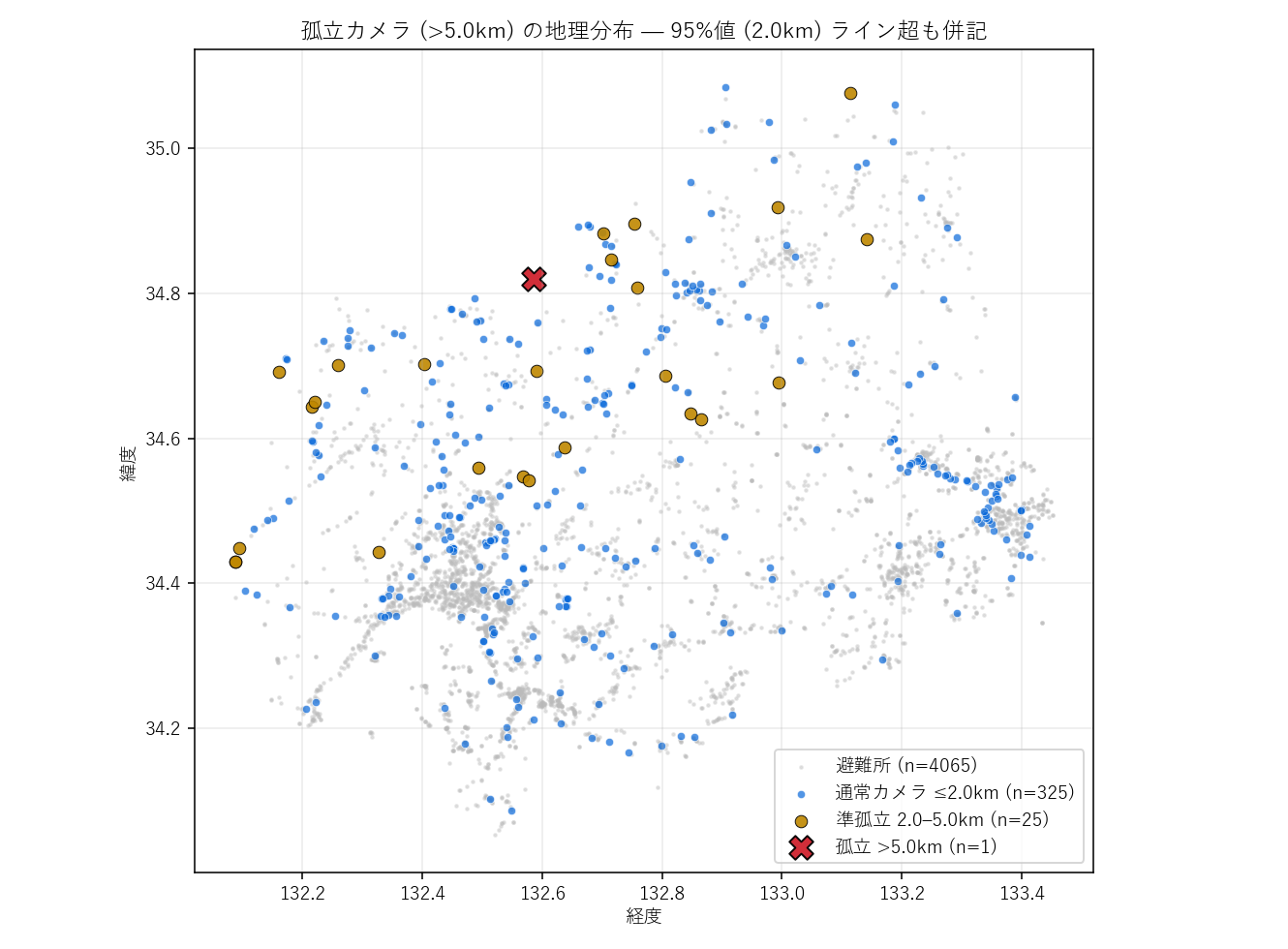
この図から読み取れること:
- 孤立カメラ (赤X) は山間部・島嶼部に偏る: 県北の中国山地、瀬戸内の離島
- 都市部(広島市・福山市・呉市)はカメラと避難所が密に重なる: 通常カメラ(青)が密集
- 避難所(背景灰色)は人口集中地に偏る: 山間部にも一定数ある一方、カメラが追いつかない地域がある
結果B(図と読み取り)— 管理区分別 箱ひげ + KW 検定
なぜこの図か: 4グループの分布の重なりと中央値差を一目で見たい → 箱ひげ。 Kruskal-Wallis の H 値・p 値をタイトルに併記して、定性的な印象(中央値の差)を統計的根拠で裏付ける。
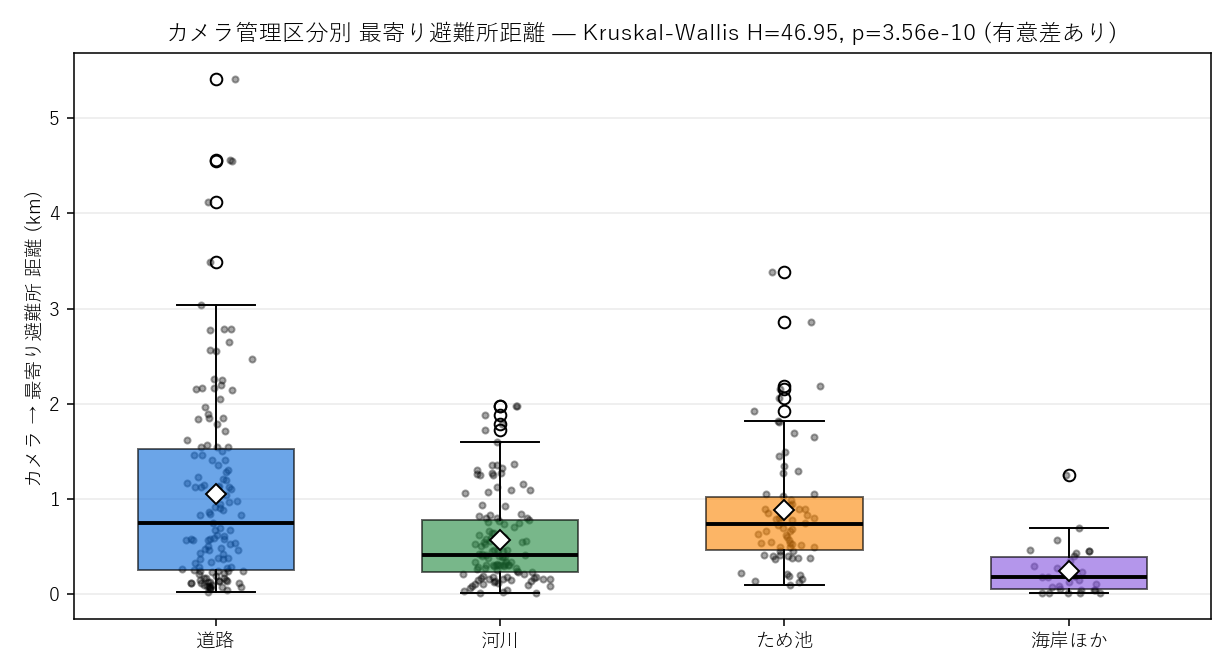
この図から読み取れること:
- 海岸ほか・河川 は中央値が極めて低い: 海岸線は港湾集落・河川は沿川集落と並走するため、避難所まで数百m以内が大半
- 道路・ため池 は中央値が高め+裾も長い: 道路カメラは山間部の主要道(県道・国道)に置かれるため、集落間の長い区間で避難所から遠いペアが混じる。ため池は山間ため池に集中
- 道路カメラに最大値の外れ値: max=5.42km は道路区分のカメラ — 山間部の長距離道路の中間地点
- p=3.56e-10 → p<0.05 で有意差あり → 仮説H5を支持
- 解釈: 区分間の差は予算配分の問題ではなく、管理目的(守る対象)の地理的必然の表れ。海岸・河川カメラは集落隣接の被害想定地点に置かれ、道路・ため池カメラは集落から離れた監視地点に置かれる
結果(表と読み取り)
表4: 管理区分別 距離サマリ
| 区分 | n_台 | 中央値_km | 平均_km | p95_km | 最大_km | 孤立_5km超 |
|---|---|---|---|---|---|---|
| 道路 | 131 | 0.74 | 1.05 | 2.78 | 5.42 | 1 |
| 河川 | 120 | 0.41 | 0.56 | 1.37 | 1.98 | 0 |
| ため池 | 70 | 0.74 | 0.88 | 2.11 | 3.39 | 0 |
| 海岸ほか | 30 | 0.18 | 0.24 | 0.63 | 1.25 | 0 |
この表から読み取れること: 中央値で見ると 海岸ほか(0.18km) < 河川(0.41km) < 道路(0.74km) ≈ ため池(0.74km) の順で集落距離が伸びる。 最大値・95%値は道路・ため池が他より大きく、区分の管理目的そのもの(道路は集落間の主要道監視、ため池は山間貯水池監視)が距離分布に直接表れている。
インタラクティブマップ(folium)
各カメラ・避難所をクリックすると詳細ポップアップ(カメラ名・住所・最寄り避難所など)が表示される。 レイヤ切替で「通常/準孤立/孤立/避難所」を個別表示可。
仮説検証と考察
仮説と結果の照合
| # | 仮説 | 判定 | 根拠 |
|---|---|---|---|
| H1 | カメラの最寄り避難所距離は中央値1km以下、95%値も数km、ただし右の長尾あり | 支持 | 図1 で中央値 0.54km、95%値 2.19km、最大 5.42km。 分布は強い右非対称で、長尾の正体は山間部・島嶼部の少数カメラ(表1)。 |
| H2 | 津波・高潮対応避難所はカメラから遠い(沿岸偏在) | 支持 | 図2 のECDFで津波・高潮の線が右にずれる。表2 で中央値・95%値が他3災害より明確に大きい。 対応避難所数の絶対差と地理的偏在の二重効果。 |
| H3 | k=1 と k=3 でカバレッジは大きく違う(冗長性は近距離で急減) | 支持 | 図3 のカバレッジ曲線で k=3 の線は k=1 から大きく右シフト。 表3 で同じd=1km での k=1 vs k=3 のカバー率差を定量確認。 |
| H4 | カメラ起点 vs 避難所起点 の最寄り距離分布は非対称 | 支持 | 図4 で避難所起点(赤, n=4065)の中央値 1.73km、p95 5.73km。 カメラ起点(青, n=351, 中央値 0.54km)と分布形が大きく違う。 「クエリ側を入れ替えると問題定義が変わる」体験。 |
| H5 | 管理区分別で距離分布に有意差あり(区分間で立地ロジックが違う) | 支持 | 図5B で Kruskal-Wallis H=46.95, p=3.56e-10(高度に有意)。 表4 で中央値順位は 海岸ほか(0.18km) < 河川(0.41km) < 道路 ≈ ため池(0.74km)。 ただし方向は当初予想と一部異なり、海岸ほか は最も避難所に近い(港湾集落隣接)。 道路・ため池は山間部の長距離区間に置かれるため遠いペアが混じる。 |
考察
- BallTree(haversine) は2データセットを「位置で結合」するツール: 共通IDがない 351カメラと 4,065避難所を、緯度経度を介して空間結合できた。 内部の球面三角法を理解しなくても 「点群を入れて木を作り、別の点を投げると最寄り N 個が返る」という使い方だけで強力な分析ができる
- 分布の「形」を読む3点セット: 中央値 + 95%値 + 最大値。 平均値だけでは右の長尾が隠れる。広島県のカメラ網は 大半は密、しかし山間・離島で孤立という構造を、 1点指標ではなく分位点で報告すべき例
- 「対応災害」フィルタ次第で実用価値が変わる: 同じカメラでも津波避難所が遠ければ津波時には機能しない。 データ前処理は問いに依存する(MDASH 応用基礎の典型例)
- 冗長性の評価は「最寄り1個」では不十分: k=1 だけ満たせば日常運用は OK だが、災害時に1台が故障した瞬間に代替がない。 インフラ評価では「ベスト1の近さ」より「ベスト3 が確保できるか」が問われる。 top-k カバレッジ曲線はそれを定量化する道具
- クエリ方向で問題定義が変わる: カメラ→避難所 (n=351) と 避難所→カメラ (n=4065) は別問題。 前者は「各カメラが何をモニタできるか」、後者は「各避難所が映像で監視されているか」。 評価したい主体に応じて木を構築する側を切り替える発想は、空間結合・最近傍法の応用全般に効く
- 区分差は予算ではなく地理: 海岸ほか・河川カメラが避難所に近いのは集落隣接の被害想定地点に置かれるため、 道路・ため池カメラが遠いペアを持つのは集落から離れた長距離主要道や山間貯水池に置かれるため。 「区分間で予算配分が偏っている」という解釈は誤り。Kruskal-Wallis で有意差 (p=3.56e-10) を確認しても、原因は 管理目的の地理的必然である
発展課題(結果から導かれる新たな問い)
各課題は、上の結果と新たな仮説に裏打ちされている。 「結果X → 新仮説Y → 課題Z」の3段で記述する。
- 道路ネットワーク距離での再評価
- 結果X: haversine 距離は球面上の直線で、山岳部の実走行距離より 短く出る。本レッスンの「最寄り 0.36km」は実際は徒歩 1km の可能性がある
- 新仮説Y: 山間部では 直線距離と道路距離の比率(歪度)が平地の数倍に達する。本レッスンの「孤立カメラ {n_iso}台」は実は2倍以上の実距離を持つ可能性
- 課題Z: OSRM や OpenStreetMap routing API でカメラ-避難所間の 実走行距離を取得し、本レッスンの直線距離との散布図を描く。山間部で直線距離が短くても道路距離が大きいペアを抽出
- 夜間人口で重み付けした「実需要」評価
- 結果X: 図4 で避難所起点 (n=4065) の最寄りカメラは長尾だが、避難所4065件には 収容人数(capacity)が大きく違う。1人収容の小さな避難所と1000人収容の大きな避難所を同列に扱っている
- 新仮説Y: capacity や夜間人口で重み付ければ、「実際に多くの人を見守るべき避難所」のうち何%がカメラから遠いかが正しく評価できる
- 課題Z: 国勢調査メッシュ(500mメッシュ)で各避難所周辺の夜間人口を集計し、距離の累積分布を「人重み」「件数重み」で2本描いて比較
- クラスタ数 k のスイープと最適配置
- 結果X: 図3 で k=3 の曲線は k=1 から大きく右シフト。「3個の冗長確保」が困難な地域がある
- 新仮説Y: 「孤立カメラ {n_iso}台 と 準孤立 {n_iso2-n_iso}台 を 0 にするには、何台を どこに追加すれば足りるか?」が定量化できる
- 課題Z: 整数計画 (set cover) または貪欲 set cover で、孤立カメラ周辺に追加カメラを配置するシミュレーション。 地点候補 = 主要道路の交差点に絞ることで現実的な最適化に
- 標高差込みの「届く映像」評価
- 結果X: 本レッスンは 水平距離だけを測っている。実際にカメラ映像が避難所まで「届く」かは標高差・遮蔽物に依存する
- 新仮説Y: 5mDEM でカメラ-避難所間の標高差を引き、下り坂で見通しがあるペアと 山稜越しのペアを区別すれば、「実用的な見守り距離」分布は本レッスンの結果よりさらに長尾になる
- 課題Z: DoBoX の 5mDEM (標高ラスタ) を読み込み、カメラ-避難所の line of sight (LoS) を ray casting で判定。LoS が通るペアだけで再分析
- 避難所→カメラ ランキングで「映像のない市町村」を抽出
- 結果X: 図4・分析4 で避難所起点の長尾を確認したが、市町村別にどう偏在しているかは未解析
- 新仮説Y: 市町村別に「最寄りカメラまで5km超の避難所の割合」を集計すると、特定の山間市町村が上位に並ぶ。これらは 映像情報による災害支援が届きにくい地域である
- 課題Z:
L09_shelter_to_camera.csvをmuniでグルーピングし、5km超避難所率を市町村ランキングに。 上位市町村に対して整備優先度を提案するレポートを作成