PCA で雨域構造を読み解く — 時間モード vs 空間モード
学習目標
- 多変量データを行列化する 視点を持つ: 観測所×時間 と 観測所×日 のどちらの軸を取るかで何が見えるかが変わる
- PCA を生雨量フィールドに適用し、寄与率・loading・スコアを 独立した3つの可視化 で読み解く
- 主成分が 「時間モード」(全県共通の降雨タイミング) と 「空間モード」(地域差) のどちらに寄っているかを、η²(分散比)で定量化する
- 再構成誤差曲線から「上位 k 個で何 % のシグナルを再現できるか」を測り、有効次元を判断できる
- NMF (非負行列因子分解) と比較し、符号制約の違いが解釈にどう影響するかを理解する
使用データ
- 1) 雨量 10分値 (14日分) — DoBoX #1275 (観測情報_雨量日集計)。2024-06-29 〜 07-12, 約 280 観測所 × 144 時刻/日 × 14日 = 約 2016 列。
- 2) 雨量 年集計 — DoBoX #1276。本レッスンでは観測所→事務所/水系の名前マッピングのみ利用。
14日窓には 2024年7月豪雨の前駆〜本格降雨 (7/1, 7/10〜7/12) が含まれており、PCA で時間モードが立ちやすい好題材。
データ取得手順
| 論題 | データセット | DL | 保存先 | 形式 | サイズ |
|---|---|---|---|---|---|
| 雨量10分値 14日分 (各日別 CSV) | DoBoX #1275 | ページから DL ボタン | data/rain_2024/rain_2024-MM-DD.csv (×14) | CSV (5段ヘッダ, 10分値, UTF-8 BOM) | 1.0〜1.4 MB / 日 |
| 雨量 年集計 (観測所→事務所/水系) | DoBoX #1276 | ページから DL ボタン | data/extras/rainfall_annual.csv | CSV (多段ヘッダ) | 約 500 KB |
一括取得(全レッスン共通, 推奨):
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.pyfetch_all.py はカタログ・追加データを data/ と data/extras/ に再現可能ダウンロード。DoBoX のオープンデータは申請不要、商用・非商用とも利用可。本レッスンの .py スクリプトは、データが無ければ自動取得してから処理を始めるよう実装されています(ensure_dataset() ヘルパ)。
スクリプト(全体ソースコード)
cd "2026 DoBoX 教材"
python -X utf8 lessons/L08_pca_rain.py方法 — 行列化の選択
14日分の10分雨量を PCA で解析するために、行と列をどう割り当てるかがまず最大の意思決定になる。
| 選択肢 | 形状 | 主成分が捉えるもの | 欠点 |
|---|---|---|---|
| (A) 観測所 × 時間 (10分粒度) | ≈ 280 × 2016 | 時間モード (県全体に共通する降雨イベント) と 地域差 の両方 | 列数 >> 行数 → 共分散の安定性に注意 |
| (B) 観測所 × 日 (14日) | ≈ 280 × 14 | 日単位の粗い時間モード | 14列では分散が薄まり、降雨イベントの形状が潰れる (旧 v1 教材の限界) |
| (C) 時間 × 観測所 (転置) | ≈ 2016 × 280 | 各時刻の "雨域パターン" の主成分 | サンプル間が時系列依存で独立性仮定が崩れる |
本教材では (A) 観測所 × 時間 (2016列) を採用する。理由:
- 降雨イベントの形 (10分単位の立ち上がり/減衰) を保存できる → 第1主成分が「7月豪雨イベントそのもの」として現れることを確認できる
- n=280 と p=2016 は p>n だが、PCA は SVD で安定計算可能 (rank ≤ min(n,p)−1 = 279)
- 各観測所を row-center + row-scale で標準化 → 「降雨の総量」ではなく「降雨パターンの形」を比較する
- 14ファイル統合:
parse_rain_csv()で 14 日分を tidy 化し転置 - 欠損 5% 超 / 全期間ゼロの観測所を除外
- 各行 (観測所) を z-score 化: パターン比較のため
- PCA(n_components=10): scree plot, loadings, scores, 再構成誤差 を計算
- 事務所名を空間プロキシとして scatter を色分け、η²(分散比) で空間構造の強さを定量化
- NMF(n_components=3): 非負入力で同じデータを分解し、PCA との解釈差を比較
コード解説
↑ L08_pca_rain.py 行 416–536
結果
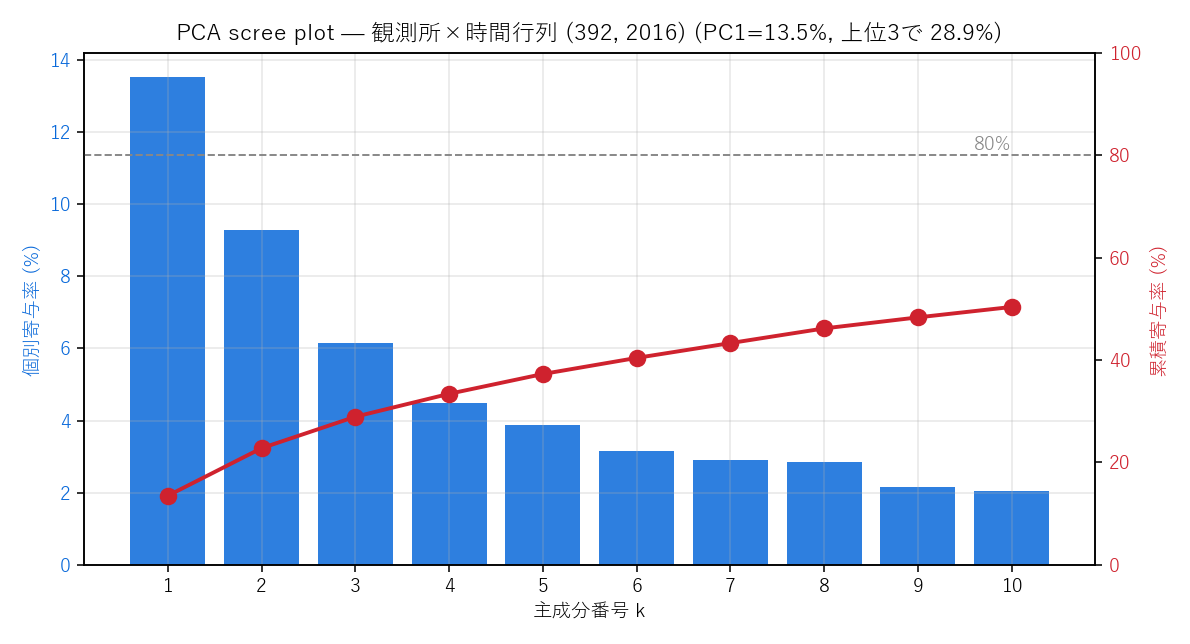
scree plot — PC1=13.5%, 上位3で 28.9%, 上位5で 37.3%, 上位10で 50.4%。1モードに集中する豪雨期間ながら、空間多様性ゆえ累積80%には10成分前後を要する。
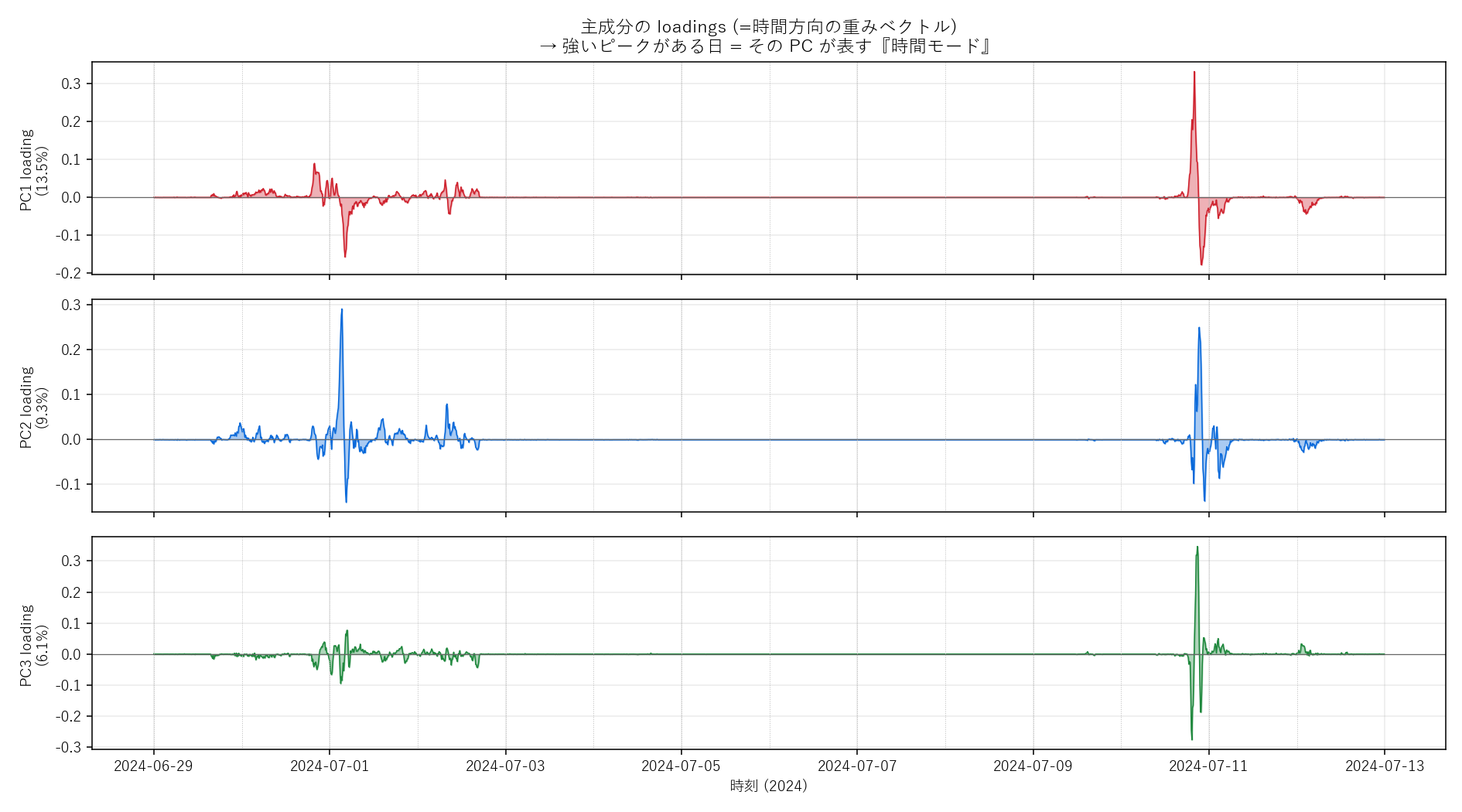
PC1〜PC3 の loadings を時間軸でプロット。点線は日付境界。loading が強くピークする時刻 = その PC が表す時間モード。
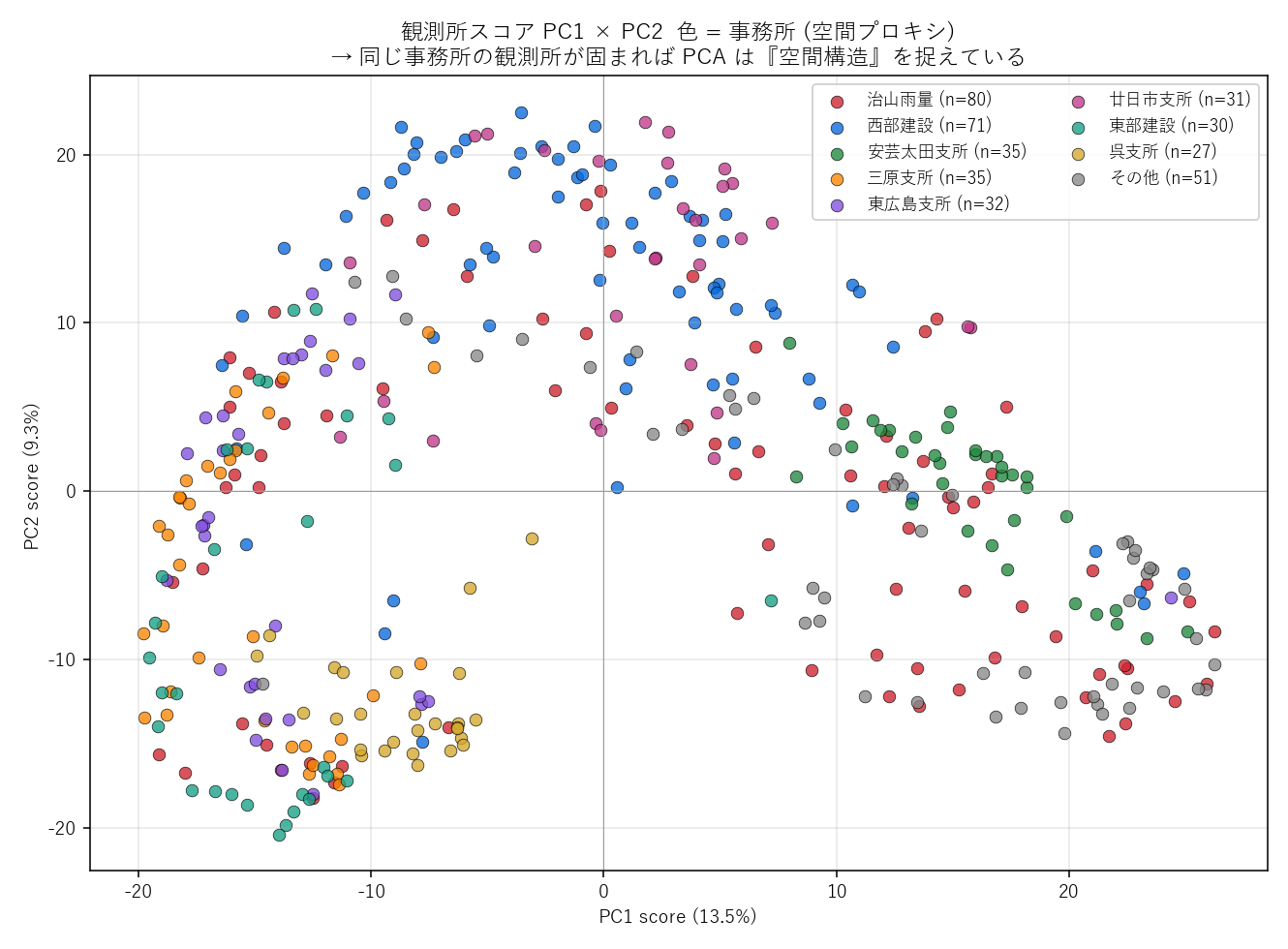
PC1×PC2 観測所スコアの散布図。色 = 事務所 (空間プロキシ)。同じ事務所が固まって見えれば PCA は『空間構造』も捉えている。
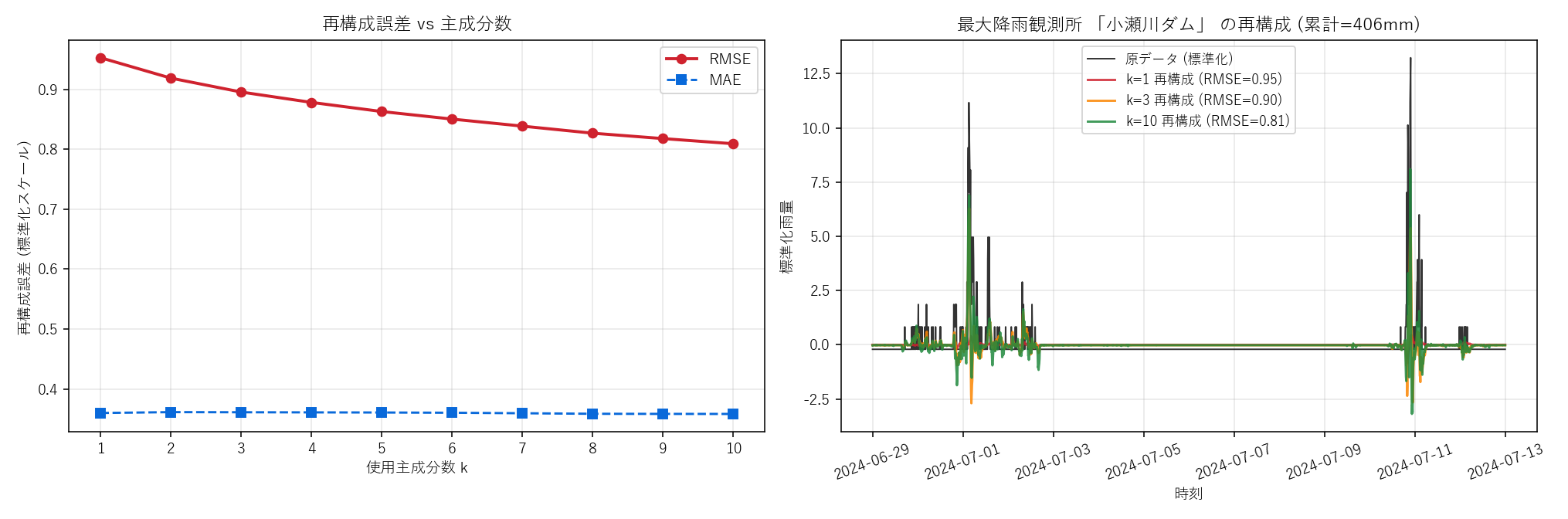
(左) RMSE/MAE と k の関係。(右) 最大降雨観測所の波形を k=1,3,10 で再構成。k=3 でピークの位置を、k=10 で細部の波形を概ね再現。
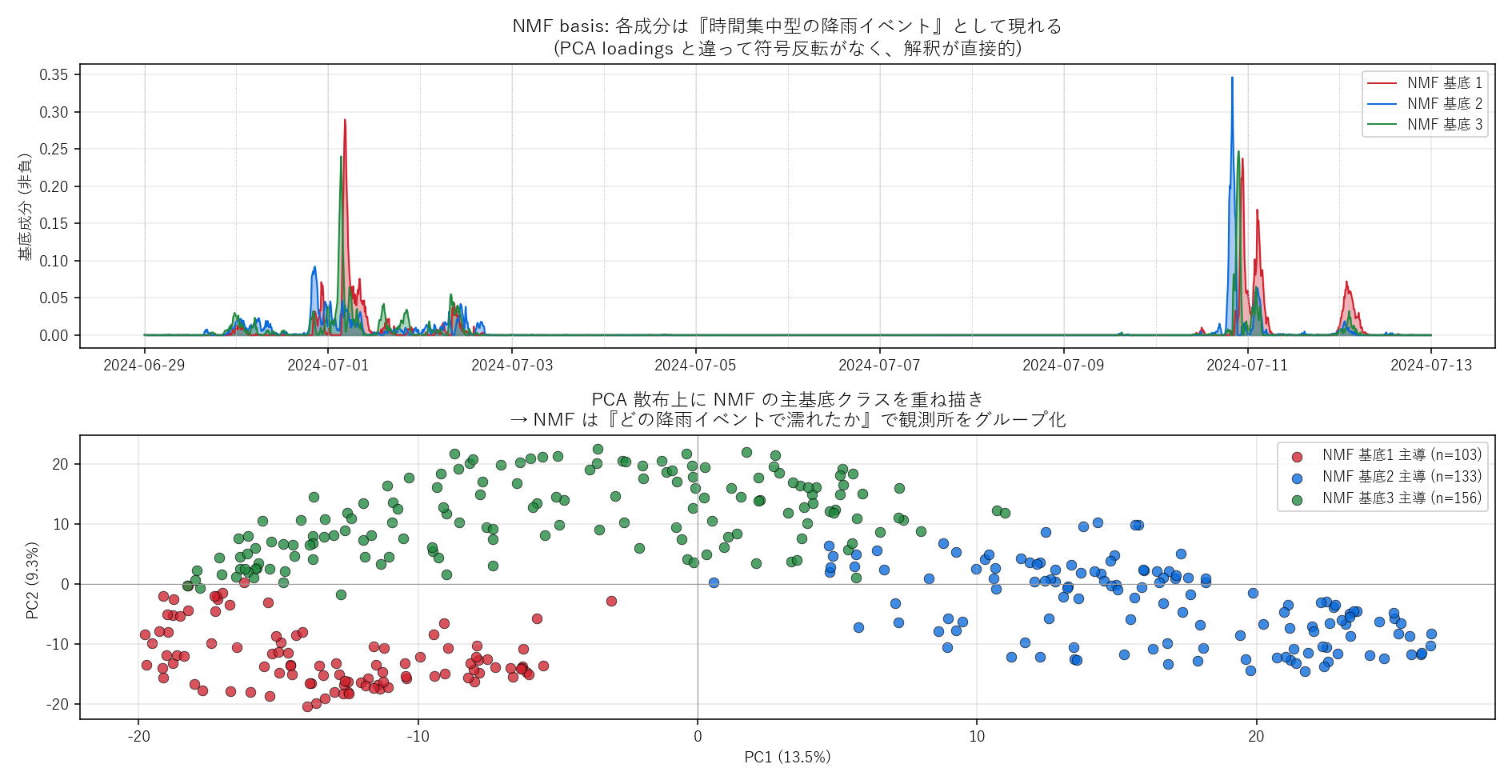
(上) NMF が抽出した3つの非負基底 = 異なるタイミングの降雨イベント。(下) 各観測所をその主導 NMF 基底でラベル付けし PCA 散布上に重ね描き。
PC ごとのサマリ (寄与率 + 空間構造の強さ η²)
| PC | 寄与率(%) | 累積(%) | loading ピーク時刻 | η² 事務所(空間) | η² 水系(空間) |
|---|---|---|---|---|---|
| PC1 | 13.51 | 13.51 | 2024-07-10 20:00 | 0.551 | 0.463 |
| PC2 | 9.29 | 22.80 | 2024-07-01 03:20 | 0.471 | 0.370 |
| PC3 | 6.14 | 28.95 | 2024-07-10 20:50 | 0.065 | 0.084 |
| PC4 | 4.47 | 33.42 | 2024-07-10 21:50 | 0.235 | 0.422 |
| PC5 | 3.87 | 37.29 | 2024-07-01 04:10 | 0.262 | 0.191 |
再構成誤差 vs k
| k | 累積寄与率(%) | RMSE | MAE |
|---|---|---|---|
| 1 | 13.51 | 0.9526 | 0.3601 |
| 2 | 22.80 | 0.9186 | 0.3616 |
| 3 | 28.95 | 0.8954 | 0.3614 |
| 5 | 37.29 | 0.8629 | 0.3609 |
| 10 | 50.39 | 0.8092 | 0.3585 |
考察
- 主成分は「時間モード」と「空間モード」を 同時に 捉える: PC1 の loadings は 2024-07-10 20:00 付近に鋭くピークし (=「7月10日夜の豪雨イベント」)、 さらに観測所スコアの事務所別 η² は PC1=0.55, PC2=0.47 と非常に大きい。 つまり「どの観測所が 7/10 イベントで最も濡れたか」が事務所単位 (=地理的にひとかたまりの地域) で揃っている。 PCA は "いつ降ったか" と "どこが濡れたか" を同時に説明する単一の軸として PC1 を選んだ。 これは降雨が 時空間で分離不可能 (non-separable) なフィールドであることの数学的反映である。
- PC1 と PC2 の役割は「異なる豪雨イベント」: PC1 ピークは 2024-07-10、PC2 ピークは 2024-07-01。 loading パターンを見ると、PC2 が正の観測所は「7/1 派 (前駆豪雨)」、負は「7/10 派 (本格豪雨)」に分かれる傾向。 つまり PCA は 「どちらのイベントで強く濡れたか」を観測所ごとに対比させる軸を 2 番目に立てている。 PC2 の事務所 η²=0.47 → これも空間構造を強く反映 (前線の通過位置・地形効果による地域差)。
- PC3 以降は時空間が「混ざる」: PC3 (η²=0.07) は空間構造がほぼ消え、ピークも 7/10 20:50 (PC1 と近接)。 PC3 は 同イベント内の細部 (10分単位の波形差)を表す可能性が高い。「主成分が立つほど解釈が難しくなる」典型例。
- 累積寄与率は緩やか — n << p の効果: 上位3で 28.9%、上位10で 50.4%。 RMSE は k=1 で 0.95 → k=10 で 0.81 と緩やかに減る。 これは p=2016 の自由度に対し n=392 観測所の振る舞いが多様なため。 気象フィールドでは 「上位数モードで主要イベントは説明できるが、ローカルな細部は高次成分にしか現れない」のが普通。
- NMF はイベント分解としてより直接的: NMF の各基底はそのまま「7/1 豪雨」「7/10 豪雨」などの 非負の時間集中パターンとして現れ、 観測所ごとの重み W[s,i] は「観測所 s が i 番目イベントでどれだけ濡れたか」と直読できる。 PCA の符号反転 (PC2 で正/負に分かれる) は数学的に必然だが解釈を一段複雑にする。「データが本来非負なら NMF を試す」は応用基礎の鉄則。
- 行列化の選択が結果を決める: もし観測所×日 (14列) で PCA したら、PC1 は単に「総雨量」を捉えるだけで時間構造は潰れる (旧 v1 教材の限界)。 今回 2016 列を保ったことで「PC1 = 7/10 イベント × 西部・廿日市の地域強雨」という 時空間が結びついた強い解釈ができた。 「集約のタイミングが情報構造を決める」はデータサイエンスの普遍則。
発展課題
- 観測所緯度経度を結合 (DoBoX 別データセットや観測所マスタを別途取得) して、PC2/PC3 のスコアを地図にカラーマップする。 本教材では事務所名を空間プロキシとしたが、緯度経度があれば 北東-南西の降雨グラデーション が可視化できる。
- 列を中心化のみ・行は中心化のみ・両方の3条件で PCA を再実行し、結果がどう変わるかを比較する (前処理の影響学習)。
- EOF (Empirical Orthogonal Function) 解析: 気象学で使われる時空間PCAの呼称。本教材の手順と全く同じだが、地球流体力学の文脈での解釈を学ぶ。
- ICA (Independent Component Analysis) を試す: PCA の「直交性」より「統計的独立性」を優先する分解。降雨イベントが独立な 'ソース' から来ていると仮定するなら ICA の方が物理的に合う。
- テンソル分解 (Tucker / CP): (観測所, 日, 時刻) の3階テンソルとして直接分解すれば、日内パターンと日間パターンを同時に分離できる。
- PCA で外れ値検出: 再構成誤差が他観測所より大きい観測所は「特異な雨域」「センサ異常」「地形効果」のいずれか。本データで誰が外れ値かを調べる。