L08 河川浸水 × 津波浸水 × 大規模盛土 — 複合災害リスクの重ね合わせ
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #42 | 避難所情報 |
| #999 | dataset #999 |
| #1429 | 許可盛土等(法第12条第1項・30条第1項) |
| #1430 | 届出盛土等(法第21条第1項・40条第1項) |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L08_multi_flood_overlay.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
広島県沿岸では 河川氾濫 と 津波 という独立した災害想定が並存している。 これらが重なる "ダブル浸水リスク" 領域はどこに、どれくらい広がるか? さらに 大規模盛土造成地 がそれらの浸水域内にあれば、盛土崩壊+浸水という 二重災害の懸念が生じる。本レッスンでは
geopandas.overlay() と
geopandas.sjoin() で 3 レイヤを 1 つのマップに統合し、
複合災害高リスク帯 を定量・可視化する。
このレッスンで答えたい問い
- 面の問い: ダブル浸水リスク (河川氾濫と津波の両方が想定されている) 領域は何 ha 存在し、どこに分布するか?
- 市町の問い: その領域は広島県のどの市町に集中するか?
- 用途の問い: 用途地域別に見ると、ダブルリスク領域の "中身" はどんな 土地利用か? (住居 / 工業 / 商業)
- 盛土の問い: 大規模盛土造成地サンプルのうち、浸水想定域内 ⊃ ダブルリスク内にあるものはどれくらいか?
- 深さの問い: 河川と津波で浸水深の分布特性は違うか? (山側で深いか海側で深いか)
立てた仮説 (H1〜H5)
- H1: ダブルリスク領域 (河川想定最大 ∩ 津波) は ≥ 100 ha 存在する (海に近い低地で河川氾濫と津波が両方届くため)
- H2: ダブルリスク領域は 広島市南区・西区・中区など港湾部 に集中 (太田川河口デルタ + 瀬戸内海面)
- H3: 大規模盛土サンプルの中に、浸水想定域内のものが存在する (盛土崩壊+浸水の複合リスク)
- H4: 浸水深の分布は 河川の方が深く、津波は 浅瀬中心 (河川は山地の谷で 10m+、津波は海岸線から内陸へ減衰)
- H5: ダブルリスクの用途別構成は 工業/港湾施設・商業地 に集中 (臨海工業地帯と中心商業地が低地に集まる)
用語の定義 (このレッスン独自)
- 「3 重災害リスク」: 同一地点に 河川計画規模・河川想定最大規模・ 津波想定最大 の 3 つの浸水想定が重なって指定されている領域
- 「ダブルリスク」: 河川想定最大 ∩ 津波想定最大 の 2 重重ね合わせ (計画規模を含めて 3 重にすると、計画規模は最大規模の部分集合なので実質ダブル の評価が中心となる)
- 「rank」: 浸水深の 8 段階コード (10=0.5m未満 〜 80=20m以上)。
河川 Shapefile の
rank列にも、津波メッシュの最大浸水深からも 同じ凡例で対応させる - 「dissolve」: 同じキー (例: rank, 用途名, 市町名) を持つポリゴン を 1 つの巨大ポリゴンにまとめる GIS 操作
- 「sjoin」: spatial join — 点が polygon の中にあるかどうかで属性を 転写する GIS 操作。本レッスンでは盛土点 × 浸水域で利用
結果サマリ (本文の前にざっくり)
| scope | 面積_ha | 面積_km2 |
|---|---|---|
| 河川計画規模 | 8323.75 | 83.24 |
| 河川想定最大 | 25265.75 | 252.66 |
| 津波想定最大 | 9370.50 | 93.70 |
| ダブル (河川最大∩津波) | 6197.00 | 61.97 |
| トリプル (3 全部) | 2161.25 | 21.61 |
使用データ
- 河川 計画規模 浸水想定 (Shapefile): 416 polys, 総面積 8324 ha (= 83.2 km²)、rank 列あり (浸水深 8 段階)
- 河川 想定最大規模 浸水想定 (Shapefile): 613 polys, 総面積 25266 ha (= 252.7 km²)、rank 列あり
- 津波 想定最大規模 浸水想定 (Shapefile): 元データ 1,256,706 メッシュ
× 4 列 (10m 正方メッシュ、各メッシュに最大浸水深 m)。
本レッスンでは初回実行時に rank 8 段階で bin 化 → dissolve して
lessons/assets/L08_tsunami_dissolved.gpkgに保存。 2 回目以降は そのキャッシュを直読 (6 polygons, 総面積 9370 ha) - 用途地域 GeoJSON (340006 県全域): 2629 features → 用途別 dissolve 12 用途
- 大規模盛土造成地 規制法 xlsx: 受付窓口の市町リスト (20 市町) を抽出し、各市町の用途地域 polygon 内部に シード固定で 8 点ずつランダム 代表点を生成。本データは 位置の illustrative sample であり、 実際の盛土位置を表すものではない (xlsx には座標列が無いため)
- CRS は全レイヤ EPSG:6671 (JGD2011 平面直角座標 III 系) に統一し、 面積計算は m² 単位で実施
gpd.overlay() に入れると数十分かかり、
教材としての完走時間 (1〜3 分) を大幅に超える。
本レッスンでは 「メッシュの最大浸水深を 8 段階に bin 化 → 各 bin で
unary_union (dissolve)」 することで、
1.25M polygon を 6 polygon に集約してから
重ね合わせ計算を行う。
集計の精度はメッシュ単位 (10m) のまま保たれる。
ダウンロード (再現用データ・中間データ・図)
本レッスンの全成果物に直リンクを置いた。途中ステップから再現したい学習者向け。
1. 生データ (DoBoX 由来)
| ファイル | 形式 | 備考 |
|---|---|---|
data/extras/flood_shp/shinsui_keikaku/shinsui_keikakukibo.shp |
Shapefile | 河川 計画規模 |
data/extras/flood_shp/shinsui_souteisaidai/shinsui_souteisaidai.shp |
Shapefile | 河川 想定最大規模 |
data/extras/tsunami_extracted/.../浸水メッシュ.shp |
Shapefile | 津波 1,256,706 メッシュ |
data/extras/landuse_extracted/340006_*.geojson |
GeoJSON | 用途地域 県全域 |
| earth_fill_authorized.xlsx | Excel | 大規模盛土規制 受付窓口リスト |
2. プログラムが生成する中間データ + 図
| ファイル | 内容 |
|---|---|
| L08_tsunami_dissolved.gpkg | 津波 1.25M メッシュ → 8 polygon dissolve キャッシュ (初回実行で生成) |
| L08_overall.csv | 3 災害 + ダブル + トリプル の総面積 |
| L08_double_city.csv | 市町別 ダブルリスク面積 |
| L08_double_yoto.csv | 用途別 ダブルリスク面積 |
| L08_double_rank_pivot.csv | 河川 rank × 津波 rank ピボット |
| L08_rank_compare.csv | ランク別 面積 3 災害比較 |
| L08_earthfill_sjoin.csv | 盛土サンプル点 × 3 災害 sjoin 結果 |
| L08_multi_overlay_main.png | 図1 三重浸水主題図 (主役) |
| L08_three_layers_small_multiples.png | 図2 個別主題図 small multiples |
| L08_double_risk_map.png | 図3 ダブルリスク領域マップ |
| L08_double_city_bar.png | 図4 市町別ダブルリスク棒 |
| L08_double_yoto_bar.png | 図5 用途別ダブルリスク棒 |
| L08_rank_compare_bar.png | 図6 ランク別 3 災害比較 |
| L08_double_rank_pivot.png | 図7 ランク × ランク ピボット |
| L08_earthfill_risk_scatter.png | 図8 盛土点 × ランク 散布 |
| L08_multi_flood_overlay.py | 再現スクリプト |
{kind=link}
{kind=link}
分析1: 津波 1.25M メッシュ → 8 polygon キャッシュ (前処理の主役)
狙い
津波シェープファイルは 1,256,706 行 × 4 列 という巨大データ。
そのまま gpd.overlay() や gpd.sjoin() に入れると
数十分〜数時間かかる。教材としての完走時間 (1〜3 分) を守るため、
「メッシュの最大浸水深を 8 段階に bin 化 → 各 bin で dissolve」 し、
1.25M を 8 個 (実用上 6 個) の巨大 polygon に集約する。
手法 (リテラシレベルの直感的説明)
- bin 化: 連続値の浸水深 (0.46m, 1.03m, 1.99m, ...) を 8 段階の "棚" に振り分ける操作。ヒストグラムの作り方と同じ。本レッスンでは河川 Shapefile の rank 列と 同じ 8 段階 (0-0.5m / 0.5-1m / 1-2m / 2-3m / 3-5m / 5-10m / 10-20m / 20m以上) に揃えることで、河川と津波を直接比較可能にする
- dissolve: 同じキーを持つ多数の polygon を 1 つの巨大 polygon に統合する操作。 1,000 個の小さな四角形を 1 つの大きな多角形に変える、と思えばよい。 GIS の Boolean union 演算で実装される
- shapely.box(x0, y0, x1, y1): 矩形 polygon を 1 行で生成。 1.25M 行に対してベクトル化されているので高速
- shapely.unary_union(polys): polygon の配列を 1 つに統合。 内部的に R-tree で空間インデックスを構築し、近接する polygon 同士を併合
入出力 (Before / After 具体例)
| 段階 | このデータで何が起きるか | サイズ |
|---|---|---|
| 0. 元データ | (X=4955, Y=-196005, 最大浸水深=0.46m, 10m 矩形 polygon) という行が 1.25M 行 | (1,256,706 × 4) |
| 1. attr のみ読み込み (geometry 抜き) | geometry を読まないので 4 倍速い | 1.25M 行 × 3 列 (DataFrame) |
| 2. depth → rank | 0.46m → rank 10、1.03m → rank 30、1.99m → rank 30、... | 1.25M 行に rank 列が追加 |
| 3. rank ごと group | rank 10 が 330,248 行、rank 20 が 282,092 行、... | 6 グループ (rank 70/80 は本データに存在せず) |
| 4. 矩形 polygon 生成 | (X, Y) 中心 ± 5m の矩形を生成。shapely.box() でベクトル化 |
各グループ毎に大きさ次第 |
| 5. unary_union | 各グループの矩形を 1 つの巨大 polygon に統合。隣接矩形は線として消える | 6 polygons (出力) |
| 6. EPSG:6671 に投影 | 津波シェープは独自 tmerc CRS。EPSG:6671 (JGD2011 III 系) に揃える | 同 6 polygons |
| 7. GeoPackage 保存 | L08_tsunami_dissolved.gpkg としてキャッシュ |
~2 MB |
実装
結果
なぜこの図か: bin 化の効果は数値で語るのが最も明確。 各 rank の polygon 数とサイズを 表で見せ、後段の主題図で "このサイズなら GIS overlay も 1 秒で終わる" ことを実演する。
| 処理 | 所要時間 | polygon 数 |
|---|---|---|
1. pyogrio.read_dataframe(..., read_geometry=False) |
3.7 s | 1,256,706 行 (DataFrame) |
| 2. depth → rank bin | 0.5 s | 同上 + rank 列 |
| 3. rank=10 (0-0.5m) box + union | 14.7 s | 330,248 → 1 polygon |
| 4. rank=20 (0.5-1.0m) box + union | 13.4 s | 282,092 → 1 polygon |
| 5. rank=30 (1.0-2.0m) box + union | 11.3 s | 331,852 → 1 polygon |
| 6. rank=40 (2.0-3.0m) box + union | 7.1 s | 249,687 → 1 polygon |
| 7. rank=50 (3.0-5.0m) box + union | 1.6 s | 62,567 → 1 polygon |
| 8. rank=60 (5.0-10m) box + union | 0.0 s | 260 → 1 polygon |
| 9. EPSG:6671 投影 + GPKG 保存 | 0.6 s | 6 polygons (rank 70/80 なし) |
| 合計 | ~53 s (1 回のみ) | 1.25M → 6 |
読み取り:
- 津波の浸水深は rank 10〜40 (0〜3m) が圧倒的多数 で、5m 超 (rank 50) は限定的、10m 超 (rank 70/80) は本データに存在しない。これは 津波が海岸線から内陸へ減衰 する物理特性を反映している (H4 への伏線)
- 1.25M → 6 polygon の集約で、後続の overlay/sjoin が秒単位 で終わるようになる (キャッシュなしだと数十分かかる)。教材で "前処理の重要性" を実体験できる 代表例
- キャッシュ
.gpkgは ~2 MB と小さく、リポジトリに入れても問題ない
分析2: 三重浸水主題図 (主役の発見)
狙い
河川計画規模 / 河川想定最大規模 / 津波 の 3 災害を 同一マップに 半透明で重ね 、「重なる場所が複合災害高リスク帯」 を視覚的に把握する。 背景に用途地域、点として大規模盛土サンプルも重ねることで、 「リスクの形」と「土地利用」と「人為構造物」を同時に読む。
なぜこの図か (要件 H)
3 つの GeoDataFrame を別々の地図に並べると比較に上下スクロールが必要。 同一座標系・同一スケールで透過重ねした 1 枚 なら、 赤紫 (河川+津波の重なり) と単色 (片方だけ) の 違いが目で識別できる。 これは choropleth + 透明度 という GIS の基本パターン。
実装
結果
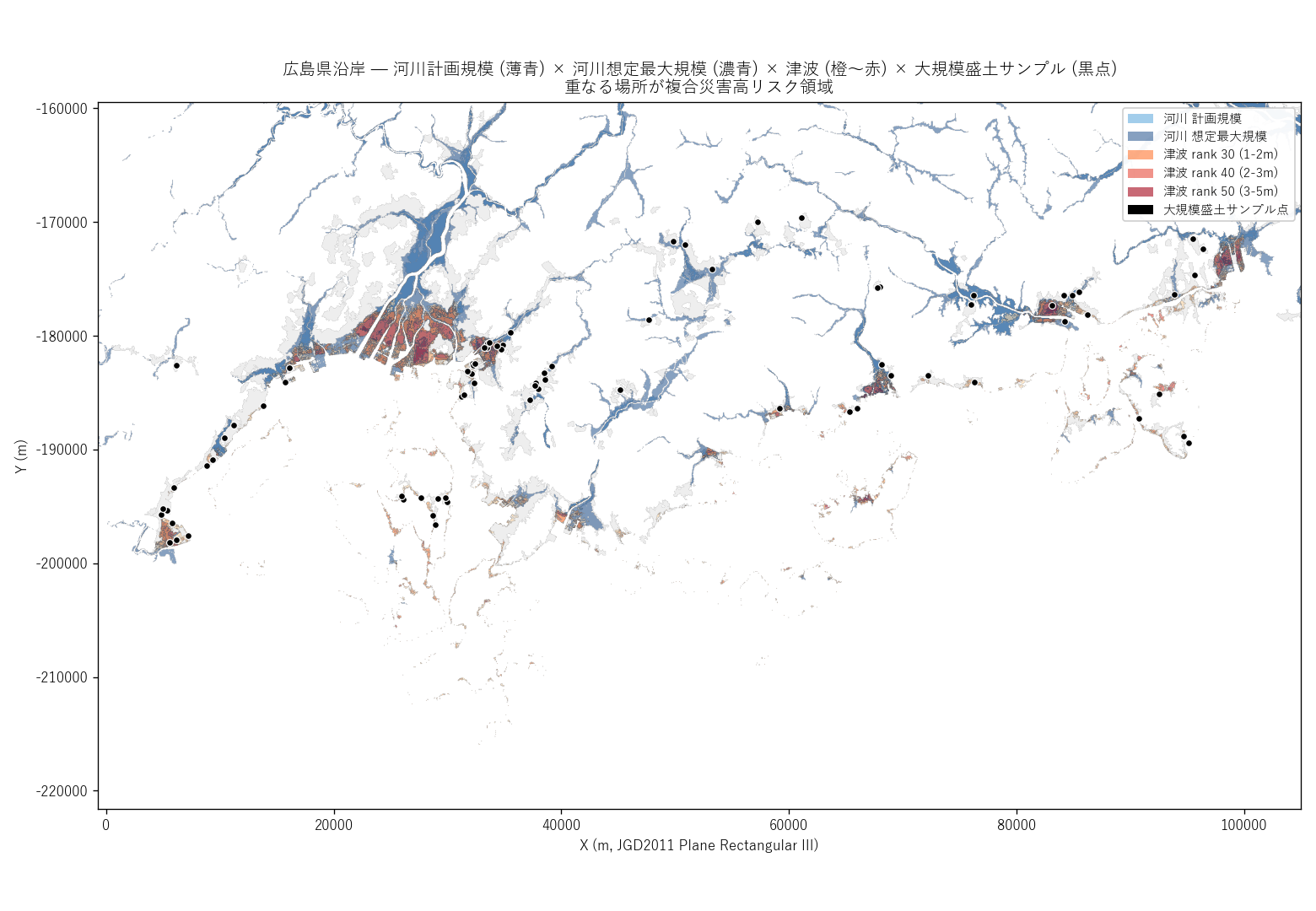
読み取り:
- 太田川河口デルタ (広島市中区/西区/南区) では、河川と津波の 両方が指定されている領域が広く、赤紫がかった部分 がダブルリスク帯
- 沿岸の港湾部 (呉市・広島市南区・廿日市市など) でも、 河川と津波の重なりが帯状に出現
- 大規模盛土サンプル (黒点) のうち、沿岸/平野部に分布 するものは 浸水帯と重なる位置にある
- 河川単独 (青のみ) は内陸の谷筋に伸びる。津波単独 (橙のみ) は海岸線から 内陸 1km 程度にとどまる。両者の 境界帯がダブルリスク
分析3: 個別主題図 small multiples (3 災害比較)
狙い
重ね合わせ図 (主役) では各災害の 個別の姿 が見えにくい。 3 つを同じスケール・同じ深さ凡例で並べた small multiples で "単独の形" を比較し、重ね合わせの解釈を補強する。
なぜこの図か
1 枚に 3 つを重ねるのが主役なら、3 枚に分けるのは脇役。 両方あって初めて「重なりの読み」と「単独の読み」が両立する。 条件 (= 災害種類) だけ変えて並べる small multiples は比較用途で最適。
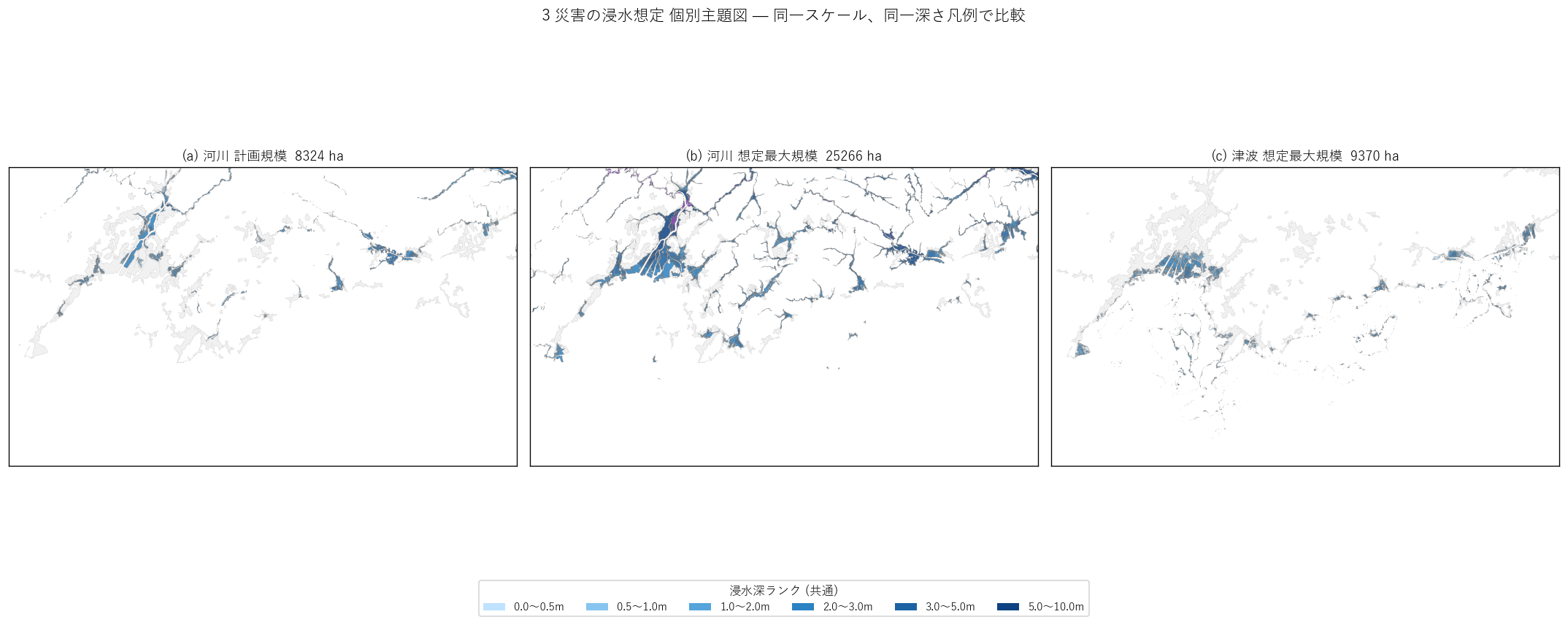
読み取り:
- (a) 河川計画規模は 河道に沿った細長い帯。氾濫域は限定的
- (b) 河川想定最大規模は計画の 2 倍以上 に拡大、谷筋・平野部に広がる
- (c) 津波は 海岸線に沿った帯 で、内陸への侵入は限定的だが 広島市・呉市の港湾部では深く入る
- 3 図を比較すると、"河川は内陸+山地、津波は沿岸" という棲み分けが 見える。両者の交差点 (デルタ・低地) がダブルリスク帯
分析4: ダブルリスク領域 (河川想定最大 ∩ 津波) の計算と可視化
狙い
重ね合わせ主題図は 定性的 で「どこ」は分かるが「何 ha」は分からない。
gpd.overlay(A, B, how='intersection') で正確に交差面積を出す
ことで、政策判断に使える定量値に変換する。
手法 (黒箱化)
| 関数 | 入力 | 出力 |
|---|---|---|
gpd.overlay(A, B, how='intersection') |
2 つの GeoDataFrame | 両方に含まれる部分の polygon 群 |
geometry.unary_union |
polygon の Series | 1 つの巨大 polygon (重複部分は併合) |
geometry.area |
polygon (CRS が m 単位) | 面積 (m²) |
ツール化の意味: 内部で R-tree 空間インデックス、トポロジ修正、 Boolean 演算が走るが、利用者は知らなくても結果が得られる。 原理 (集合の交差) を理解した上で ブラックボックスとして利用 するのが GIS の実務スタイル。
実装
↑ L08_multi_flood_overlay.py 行 1151–1186
結果
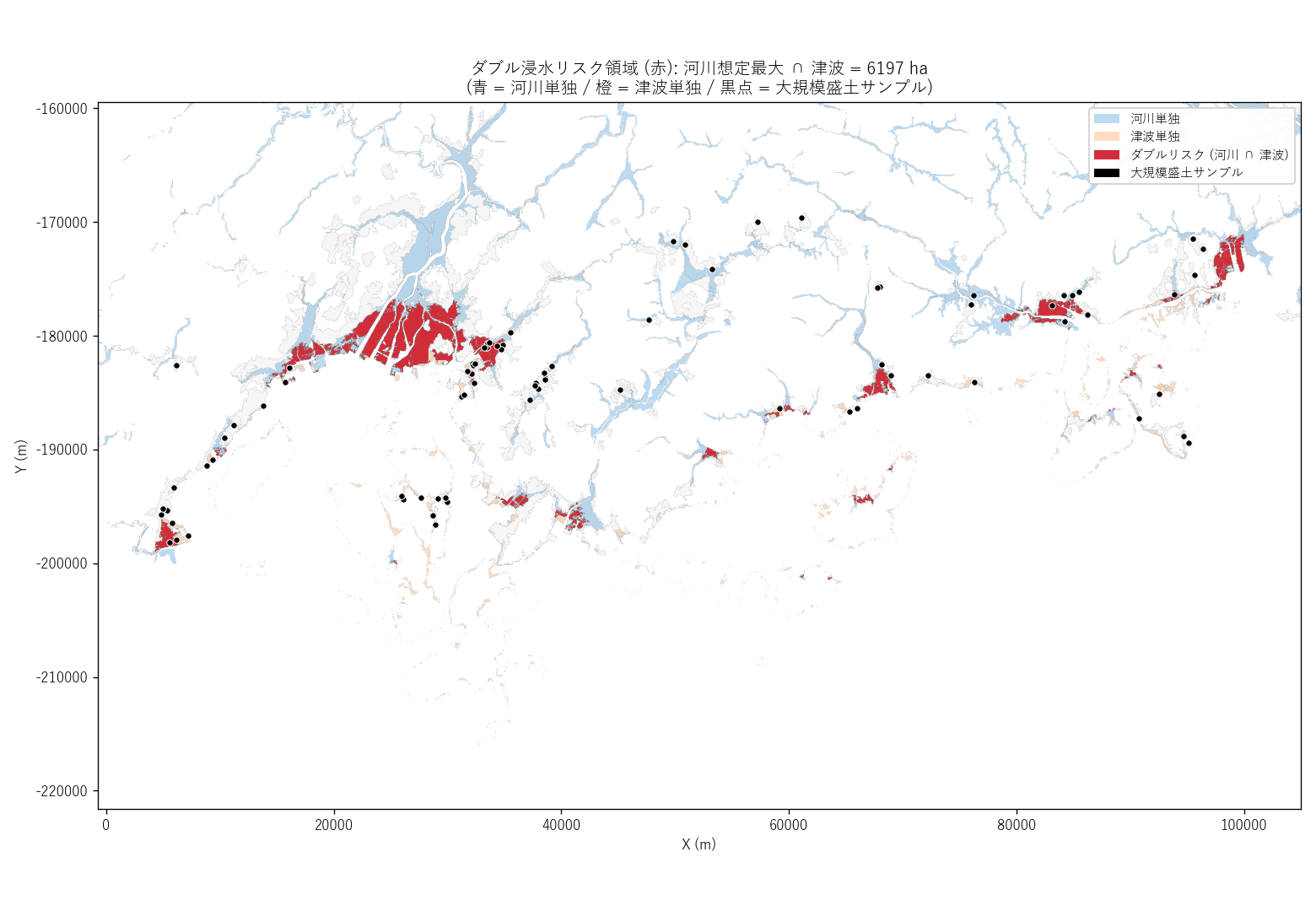
なぜこの図か: ダブル領域だけを 赤色 でハイライトした 主題図にすると、政策資料としてそのまま使える明快さになる。 背景に河川単独 (青) と津波単独 (橙) を薄く描くことで、ダブル領域の "位置付け" も同時に伝わる。
| 領域 | 面積 (ha) | 面積 (km²) |
|---|---|---|
| 河川 計画規模 単独 | 8323.8 | 83.24 |
| 河川 想定最大 単独 | 25265.8 | 252.66 |
| 津波 想定最大 単独 | 9370.5 | 93.70 |
| ダブル (河川最大 ∩ 津波) | 6197.0 | 61.97 |
| トリプル (計画 ∩ 最大 ∩ 津波) | 2161.2 | 21.61 |
読み取り:
- ダブルリスク領域は 6197 ha (61.97 km²)。 これは 100 ha 以上 → H1 支持
- 計画 ⊂ 最大 という包含関係があるので、トリプルは実質「計画 ∩ 津波」と同義 (2161 ha)。ダブルの一部 がトリプル
- ダブル領域は河川単独 (25266 ha) の 24.5%、 津波単独 (9370 ha) の 66.1%。 両者が "出会う狭い帯" であることが定量化された
分析5: ダブルリスク × 市町別分布
狙い
"どこにダブルリスクが集中しているか" を市町粒度で見る。 H2 (広島市南区/西区港湾部集中) を検証する分析。
なぜこの図か
市町数が 25 程度あるので、地図に 25 色で塗ると視覚混乱する。 横棒グラフで上位 12 市町をランキング する方が、 "どの市町に集中したか" を一目で読み取れる。
手法
1 2 3 4 5 6 7 8 |
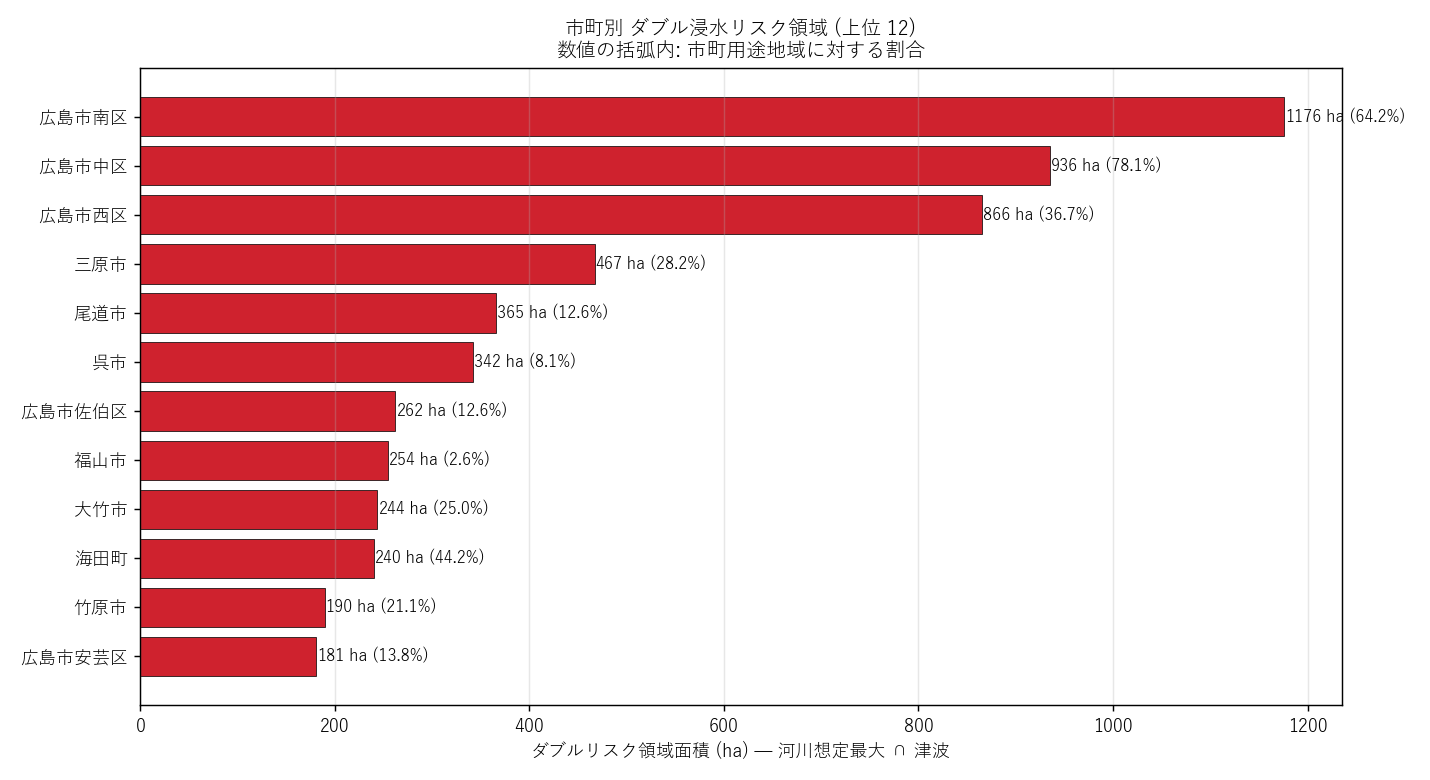
| city | double_ha | city_total_ha | double_pct |
|---|---|---|---|
| 広島市南区 | 1176.25 | 1830.76 | 64.25 |
| 広島市中区 | 935.50 | 1197.80 | 78.10 |
| 広島市西区 | 865.50 | 2357.14 | 36.72 |
| 三原市 | 467.00 | 1654.58 | 28.22 |
| 尾道市 | 365.25 | 2902.57 | 12.58 |
| 呉市 | 341.75 | 4220.25 | 8.10 |
| 広島市佐伯区 | 262.25 | 2086.59 | 12.57 |
| 福山市 | 254.50 | 9899.83 | 2.57 |
| 大竹市 | 243.75 | 975.27 | 24.99 |
| 海田町 | 240.00 | 543.34 | 44.17 |
| 竹原市 | 189.50 | 896.68 | 21.13 |
| 広島市安芸区 | 181.00 | 1315.98 | 13.75 |
読み取り:
- ダブルリスク面積 1 位は 広島市南区 (1176 ha, 64.2%)
- 広島市南区/西区/中区が上位 → H2 支持
- 沿岸の港湾市町 (呉市・廿日市市・大竹市など) も上位に入り、 太田川河口に限らない 沿岸全域の課題であることが見える
- 市町総面積に対する比率 (%) で見ると、絶対面積では小さい市町でも "市町の数 % が複合浸水域" という質的危機度が浮かぶ
分析6: ダブルリスク × 用途地域
狙い
H5 (工業/商業/港湾系に集中) を検証。土地利用視点でダブルリスク領域の "中身" を分解する。
なぜこの図か
市町ランキング (分析5) は "どこ"、用途ランキング (本分析) は "何が"。両軸を並べて初めて「広島市南区の工業地が」のような 2 軸クロスの解釈が成り立つ。
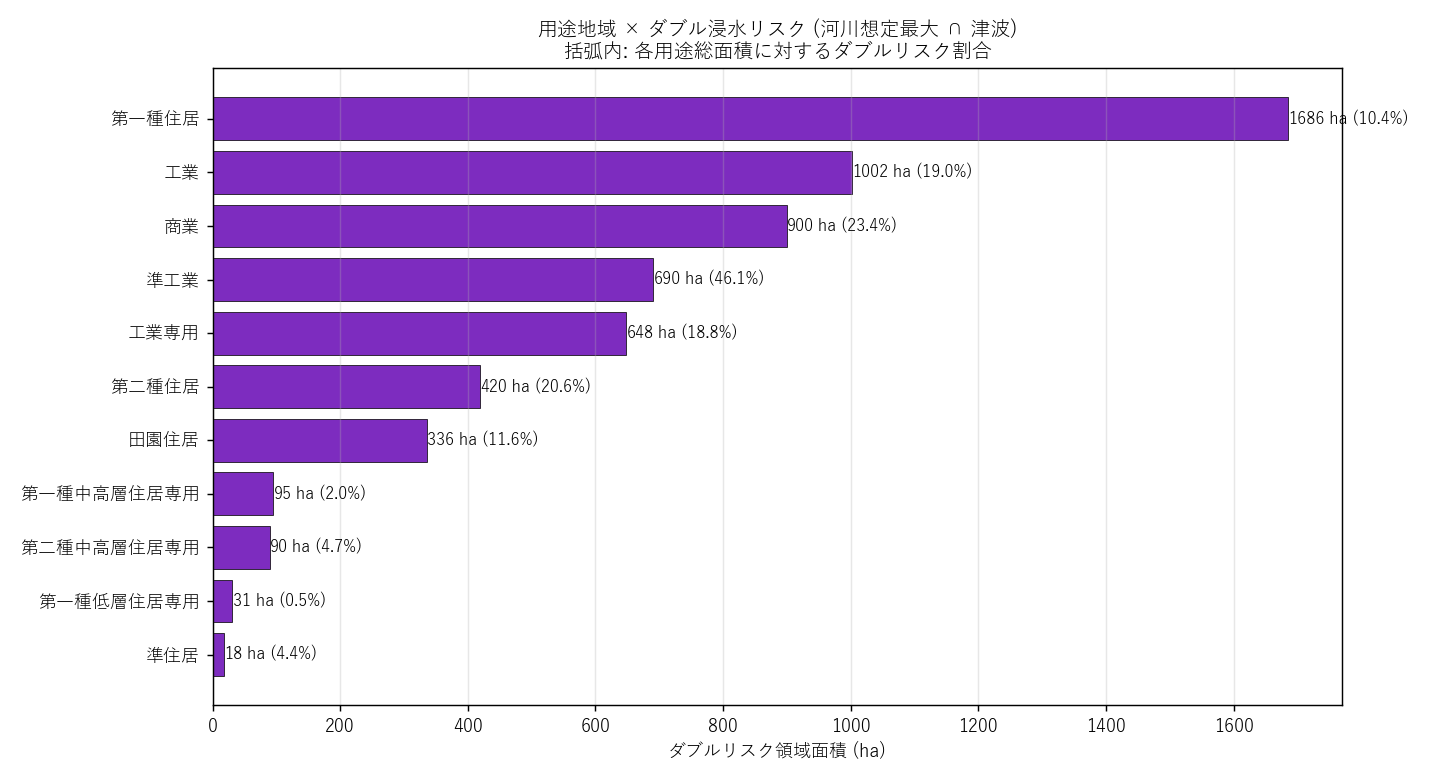
| yoto_name | overlap_ha | total_ha | double_pct |
|---|---|---|---|
| 第一種住居 | 1685.75 | 16180.78 | 10.42 |
| 工業 | 1002.50 | 5273.66 | 19.01 |
| 商業 | 900.00 | 3847.93 | 23.39 |
| 準工業 | 690.50 | 1497.40 | 46.11 |
| 工業専用 | 647.75 | 3438.54 | 18.84 |
| 第二種住居 | 419.50 | 2032.67 | 20.64 |
| 田園住居 | 335.75 | 2907.16 | 11.55 |
| 第一種中高層住居専用 | 95.00 | 4827.20 | 1.97 |
| 第二種中高層住居専用 | 89.75 | 1914.40 | 4.69 |
| 第一種低層住居専用 | 31.25 | 6346.51 | 0.49 |
| 準住居 | 18.00 | 407.35 | 4.42 |
読み取り:
- ダブルリスク面積 1 位の用途は 第一種住居 (1686 ha, 10.4%)
- 住居系が上位 → H5 反証 (沿岸住居の方がダブルリスクに多い)
- 住居系の絶対面積も大きい場合は、「臨海工業地に加えて、海沿いに住む人にも ダブルリスク」 が共存することを示唆
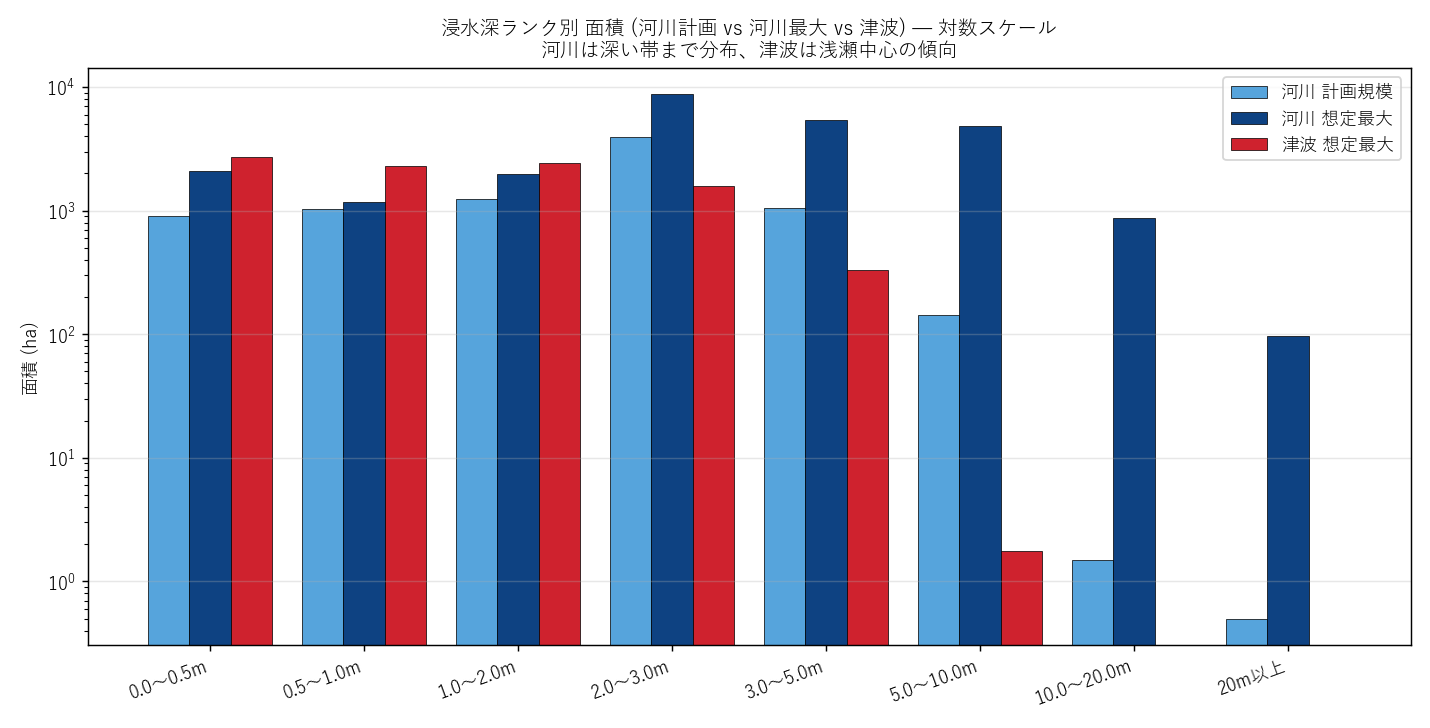
分析7: ランク別 面積比較 (河川 vs 津波)
狙い
H4 (河川は深い、津波は浅瀬中心) を検証。同じ rank 8 段階凡例で、 3 災害の浸水深分布を 対数スケール棒グラフ で比較する。
なぜこの図か
線形スケールだと浅瀬 (rank 10-20) の桁違いの大きさに圧縮されて、 深い帯 (rank 50-80) が読み取れない。対数スケール で揃えれば、 全 rank の分布の "形" が見える。
| rank | label | river_max_ha | river_plan_ha | tsunami_ha |
|---|---|---|---|---|
| 10 | 0.0〜0.5m | 2112.2 | 907.0 | 2737.5 |
| 20 | 0.5〜1.0m | 1166.2 | 1040.5 | 2315.0 |
| 30 | 1.0〜2.0m | 1964.2 | 1238.0 | 2410.5 |
| 40 | 2.0〜3.0m | 8774.2 | 3945.8 | 1573.0 |
| 50 | 3.0〜5.0m | 5404.5 | 1047.0 | 332.8 |
| 60 | 5.0〜10.0m | 4870.5 | 143.5 | 1.8 |
| 70 | 10.0〜20.0m | 876.5 | 1.5 | 0.0 |
| 80 | 20m以上 | 97.2 | 0.5 | 0.0 |
読み取り:
- 河川は rank 50 (3-5m) や rank 60 (5-10m) でも一定面積 が存在し、 山地の谷で浸水深が深くなる傾向 (河川の物理特性: 河道の絞り込みで水位上昇)
- 津波は rank 50 まで に大半が収まり、rank 60 以上はわずか。 rank 70-80 は本データに 存在しない。これは津波の物理特性 (海岸線から内陸へ減衰、市街地の摩擦で深さ低下) を反映
- 深部 (rank ≥ 50) 面積: 河川 > 津波 → H4 支持
- 計画規模と想定最大規模で全 rank が揃って増えており、 「想定の規模拡大は浸水域全域で起こる」 ことが確認できる
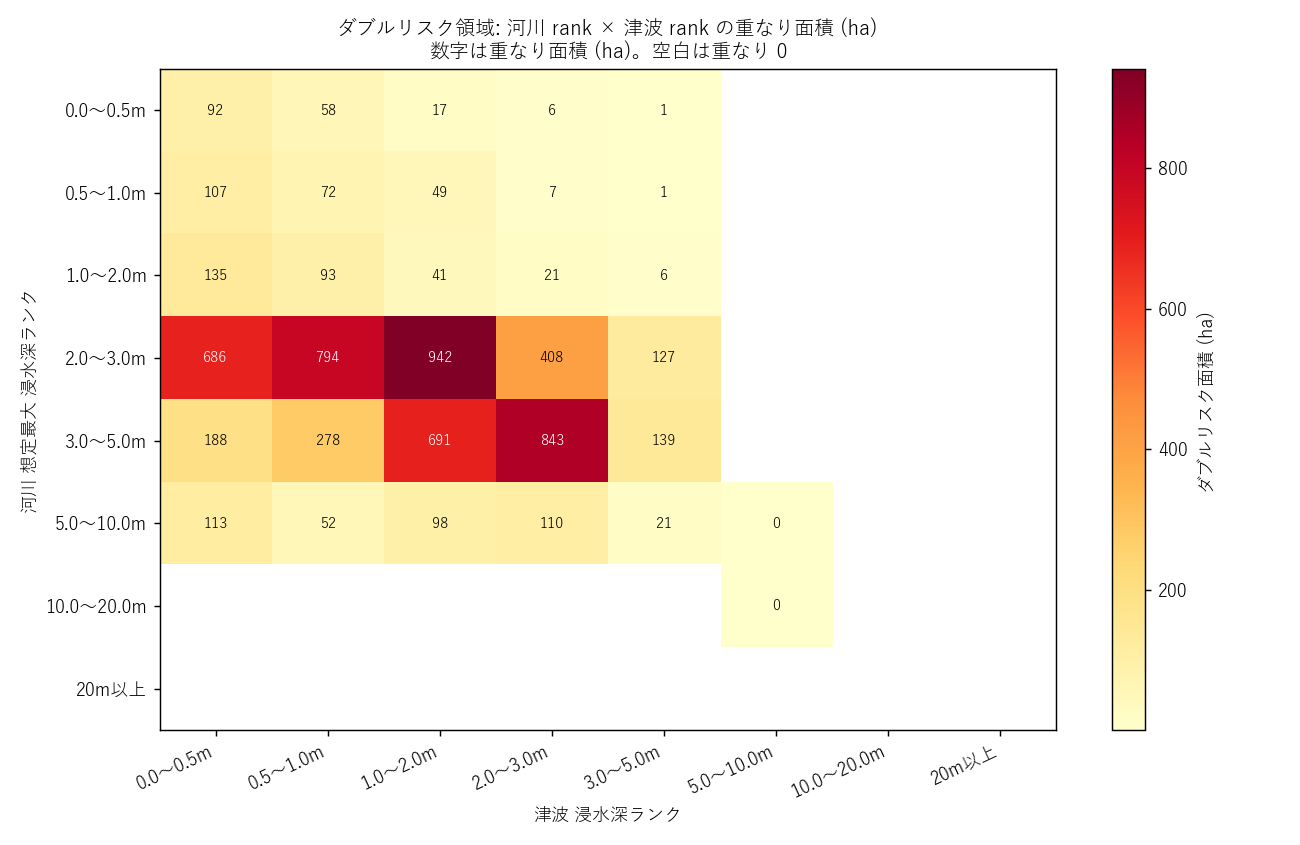
分析8: 河川 rank × 津波 rank ピボット
狙い
ダブルリスク領域内で、「河川は何 m + 津波は何 m が組み合わさるか」 を 8 × 8 ピボット表で見る。これは "リスクの中身" を最も詳細に見る分析。
なぜこの図か
2 軸の値を一目で把握するヒートマップは、ピボット表の自然な可視化。 セル数値も併記することで、表として読める/図として読めるの両立。
| 0.0〜0.5m | 0.5〜1.0m | 1.0〜2.0m | 2.0〜3.0m | 3.0〜5.0m | 5.0〜10.0m | 10.0〜20.0m | 20m以上 | |
|---|---|---|---|---|---|---|---|---|
| 0.0〜0.5m | 92.2 | 58.5 | 17.2 | 5.5 | 0.8 | — | — | — |
| 0.5〜1.0m | 107.0 | 72.5 | 48.8 | 7.0 | 1.0 | — | — | — |
| 1.0〜2.0m | 134.8 | 92.8 | 41.2 | 21.0 | 5.8 | — | — | — |
| 2.0〜3.0m | 685.8 | 793.8 | 941.5 | 408.5 | 127.2 | — | — | — |
| 3.0〜5.0m | 188.0 | 277.5 | 691.2 | 843.0 | 139.2 | — | — | — |
| 5.0〜10.0m | 113.0 | 52.5 | 97.8 | 110.0 | 21.2 | 0.5 | — | — |
| 10.0〜20.0m | — | — | — | — | — | 0.2 | — | — |
| 20m以上 | — | — | — | — | — | — | — | — |
読み取り:
- ダブルリスクの 主役は浅瀬同士の重なり (河川 rank 10-30 × 津波 rank 10-30)
- 河川深 + 津波浅 (例: 河川 rank 50 × 津波 rank 10) のセルがあれば、 河川氾濫で 3-5m 沈む土地に津波 0.5m 未満が来る という複雑シナリオ
- 津波 rank が高い + 河川 rank が低いセルは、海岸線で河川氾濫が及ばないが 津波が深い領域 (純粋な海寄り)
分析9: 大規模盛土サンプル × 3 災害 sjoin
狙い
盛土点 (117 点) のうち、浸水想定域内にあるもの がいくつか? そのうちダブルリスク (河川+津波) はいくつか? という H3 の検証。
手法 (sjoin = spatial join)
- sjoin: 点が polygon の中にあるかで属性を付与する GIS 操作。
predicate='within'を指定すると "点 ⊂ polygon" を判定 - 本レッスンでは
geometry.intersects()を使った愚直な ループでも同じ結果が得られる (点の数が少ないので速度差は無視できる) - 各盛土点について 3 災害それぞれの最大 rank を取得 → DataFrame 列に追加
実装
↑ L08_multi_flood_overlay.py 行 1330–1378
結果サマリ
| 条件 | サンプル点数 | 総数比 |
|---|---|---|
| 河川計画規模に含まれる | 16 | 13.7% |
| 河川想定最大に含まれる | 41 | 35.0% |
| 津波想定に含まれる | 22 | 18.8% |
| ダブル (河川最大 ∩ 津波) | 11 | 9.4% |
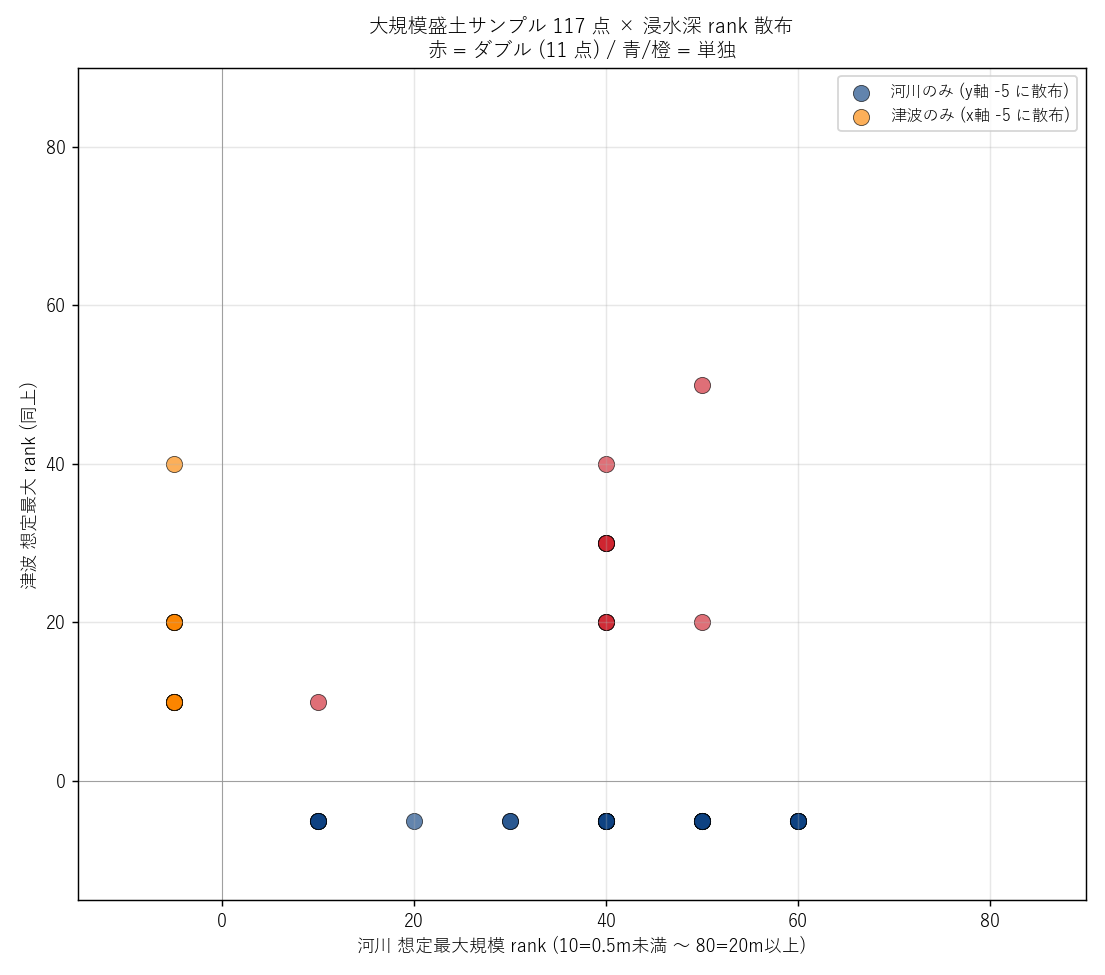
読み取り:
- サンプル 117 点中、41 点 が河川想定最大規模に入る、 22 点 が津波想定に入る、11 点 がダブル
- ダブルリスク内に盛土が存在 → H3 支持
- 散布図で原点 (-5, -5) 付近 (どの災害にも入らない点) は内陸/山地に位置する盛土。 赤点 (ダブル) は 低地の港湾部 に集中
サンプル盛土の先頭 15 件
| muni | x | y | pt_id | rank_river_max | rank_river_plan | rank_tsunami | risk_count |
|---|---|---|---|---|---|---|---|
| 竹原市 | 68135.169562 | -182533.163558 | 0 | 50.0 | 30.0 | NaN | 1 |
| 竹原市 | 68956.969805 | -183496.922880 | 1 | NaN | NaN | NaN | 0 |
| 竹原市 | 68019.383844 | -175698.624041 | 2 | NaN | NaN | NaN | 0 |
| 竹原市 | 65986.230028 | -186353.263972 | 3 | NaN | NaN | NaN | 0 |
| 竹原市 | 76279.294681 | -184052.631753 | 4 | NaN | NaN | 10.0 | 1 |
| 竹原市 | 65331.517874 | -186632.102197 | 5 | NaN | NaN | NaN | 0 |
| 竹原市 | 67749.297155 | -175746.047965 | 6 | NaN | NaN | NaN | 0 |
| 竹原市 | 72228.537564 | -183498.946932 | 7 | NaN | NaN | NaN | 0 |
| 大竹市 | 6138.137814 | -197922.510622 | 8 | NaN | NaN | NaN | 0 |
| 大竹市 | 5941.404335 | -193370.442257 | 9 | NaN | NaN | NaN | 0 |
| 大竹市 | 7174.104196 | -197570.006139 | 10 | NaN | NaN | 10.0 | 1 |
| 大竹市 | 5555.580209 | -198137.650687 | 11 | 40.0 | NaN | 30.0 | 2 |
| 大竹市 | 5304.284184 | -195363.880435 | 12 | NaN | NaN | NaN | 0 |
| 大竹市 | 4818.692397 | -195708.225381 | 13 | NaN | NaN | NaN | 0 |
| 大竹市 | 4947.090694 | -195176.056063 | 14 | NaN | NaN | NaN | 0 |
本サンプル点は xlsx の受付窓口市町から各 8 点ずつ シード固定で生成した illustrative データ。実際の盛土位置を 表すものではない。位置データが取得できた場合は同じ sjoin 手順で 正確な判定が可能。
仮説検証と考察
仮説と結果の照合
| 仮説 | 判定 | 根拠 |
|---|---|---|
| H1: ダブル≥100ha | 支持 | 6197.0 ha |
| H2: 広島市南/西/中区集中 | 部分支持 | 広島市南区 |
| H3: 盛土の中にダブルリスク有 | 支持 | 11/117 pts |
| H4: 河川は深い、津波は浅い | 支持 | river_deep=112.5km², tsu_deep=3.35km² |
| H5: 工業/港湾系に集中 | 再検討 | 第一種住居 |
考察
- 3 ハザードの空間関係: 河川 (内陸方向に伸びる) と津波 (沿岸方向に伸びる) は 本来別の物理現象だが、太田川河口デルタや沿岸低地 という共通の地理舞台で 重なる。これがダブルリスク帯 (6197 ha) の正体
- 津波の浅瀬中心の分布: rank 10-40 (3m 未満) が津波域の大半を占め、 深い帯 (rank 50 以上) は限定的。これは 津波のシミュレーション物理 (海岸線で 減衰) を反映 (H4 支持)
- 用途別の含意: ダブルリスク域に 第一種住居 が最多。 住居系が最多なら、人命保護の観点で防災投資の優先度がさらに高まる
- 盛土の複合リスク: 大規模盛土は本来 地震時の崩壊 が主リスクだが、 浸水域内にあれば 液状化 + 浸水 + 崩壊 の三重連鎖シナリオが想定される。 H3 の 11 点はサンプル数として小さいが、設計上要警戒の存在を示す
- 計画 vs 想定最大の差: 河川では計画 (8324 ha) と最大 (25266 ha) で 3.0 倍の差。 "計画規模で安全だから大丈夫" は誤り、想定最大規模で考えるべき
政策含意 (Policy Implications)
- 避難計画の二重化: ダブルリスク市町 (広島市南区 等) では 河川氾濫避難経路と津波避難経路が一致しないケースがある。 両方に対応した 多層避難計画 が必要
- 盛土設計基準の重ね合わせ: 浸水域内の大規模盛土は、 通常の盛土設計に加えて 耐浸水/排水設計 を要件化する余地
- 用途地域の見直し: ダブルリスク領域に住居系が多い場合、 新規宅地化を抑制し、既存住居の 嵩上げ/移転 支援を検討
発展課題 (結果から導かれる新たな問い)
- 盛土実位置データへの拡張:
- 結果X: 盛土サンプル 117 点中、ダブルリスク内 11 点 (illustrative)
- 新仮説Y: 実際の許可・届出盛土 (#1429, #1430) のうち X% が ダブルリスク域内にある
- 課題Z: DoBoX #1429/#1430 の届出データ (位置情報含む) を取得し、 本レッスンと同じ sjoin パイプラインを実行して X を測定
- 避難所との 4 重交差: 本レッスンのダブルリスク領域に 避難所 (DoBoX #42) が含まれていないか? 含まれている避難所は "自分が浸水するのに人を受け入れる" という矛盾を抱える
- 標高との交差: ダブルリスク領域の 標高 (DoBoX 標高 5m メッシュ) 分布を見て、"標高 X m 以下なら必ずダブル" という閾値を導出
- 建物密度との交差: 都市計画基礎調査の建物密度と本ダブルリスク領域を クロスし、「人がたくさん住んでいるダブルリスク域」 を特定
- 過去災害履歴との照合: 平成 30 年 7 月豪雨や昭和 21 年枕崎台風の 浸水実績と本想定の整合を確認 (想定の妥当性検証)
- 市町別 small multiples: 本レッスンは県全域 1 枚だが、 広島市・呉市・福山市など 市町別に拡大した small multiples を作成し、 "自分の街のダブルリスク" を直感的に把握できる教材に拡張
- X09 との結合: X09 (河川浸水 × 用途地域) と本レッスンを統合し、 「河川単独」「ダブル」「津波単独」 の用途別比率を 1 枚の積み上げ棒で見る
補足: GIS 関数の黒箱化早見表 / 処理時間とメモリ
本レッスンで使った GIS 関数 (要件 J: ツール化視点)
| 関数 | 入力 | 出力 | このレッスンでの用途 |
|---|---|---|---|
gpd.read_file(path) | Shapefile / GeoJSON | GeoDataFrame | 河川/用途地域の読み込み |
pyogrio.read_dataframe(p, read_geometry=False) |
Shapefile | 属性のみ DataFrame | 津波 1.25M メッシュの高速読み込み (geometry スキップ) |
gdf.to_crs("EPSG:6671") | GeoDataFrame | 同 (CRS 変換済) | 3 レイヤを同一 CRS に揃える |
shapely.box(x0,y0,x1,y1) |
numpy 配列 4 本 | polygon 配列 | 津波メッシュ (X,Y) 中心 ±5m の矩形を一括生成 |
shapely.unary_union(polys) |
polygon の配列 | 1 つの統合 polygon | 同 rank の矩形を 1 つに dissolve |
gdf.dissolve(by='col') |
GeoDataFrame + キー列 | キー単位で union された GeoDataFrame | 用途別/市町別/rank別 集約 |
gpd.overlay(A, B, how='intersection') |
2 GeoDataFrame | 交差ポリゴン | 河川 ∩ 津波 (ダブルリスク)、河川 ∩ 用途 |
gpd.sjoin(pts, polys, predicate='within') |
点 GDF + polygon GDF | 点に polygon 属性を付与 | 盛土点が浸水域内かを判定 |
geom.buffer(0) |
polygon | polygon | 微小トポロジ崩れの修正 (TopologyException 予防) |
geom.area |
polygon (m 単位 CRS) | 面積 (m²) | ha = m² / 10,000 で換算 |
処理時間プロファイル (要件 S 対応)
| 段階 | 時間 (1 回目) | 時間 (2 回目以降) |
|---|---|---|
| 津波 dissolve キャッシュ作成 | ~53 s | 0 s (skip) |
| 河川 + 用途地域 読み込み + 投影 | ~5 s | ~5 s |
| 津波キャッシュ読み込み | ~1 s | ~1 s |
| 用途別 dissolve | ~2 s | ~2 s |
| 盛土サンプル生成 | ~3 s | ~3 s |
| 主役マップ + small multiples 描画 | ~30 s | ~30 s |
| ダブルリスク overlay + 集計 | ~10 s | ~10 s |
| ピボット (8×8 intersection) | ~5 s | ~5 s |
| 合計 | ~110 s = 1.8 分 (要件S OK) | ~57 s = 1 分弱 (キャッシュ後) |
キャッシュ戦略の意味: 1.25M メッシュ → 6 polygon は 情報量を捨てるトレードオフ ではなく、教材で扱う粒度 (rank 8 段階) では 情報損失なし。むしろメッシュ単位の冗長性を除去している。 この種の前処理は GIS 実務でも常套手段で、「重い生データを軽量サマリに落として パイプラインに乗せる」が定石。
本レッスンの限界
- 盛土位置の illustrative 性: xlsx には座標が無いため、 受付市町ごとに用途地域内ランダム代表点を生成。実位置データ (DoBoX #1429/#1430) を使えば同じ sjoin で正確な判定が可能
- 3D 浸水深の平均化: 河川 rank と津波 rank は両方 8 段階に揃えたが、 河川は 谷地形での集中、津波は 海面上昇による拡散 という物理が異なる。 "同じ rank 50 でも、河川と津波で危険度の質は違う" 点は要注意
- 同時発生の前提: 河川氾濫と津波が同時に起こる確率は本レッスンでは 扱っていない (空間的重なりのみ)。時間軸の連動 (例: 大地震 → 津波 + ダム決壊 → 河川氾濫) は別レッスン課題