k-means による雨量観測所のクラスタリング — 時間プロファイル × 地理分布
学習目標
- 多変量データを 標準化 → k-means で教師なし分類できる
- 特徴量エンジニアリング (合計・最大・分散・ピーク時刻・雨日数 + lat/lon) で 観測所を 7 次元ベクトルに翻訳する
- エルボー法 と シルエットスコア の両方で k を選ぶ
- クラスタ重心の 時間プロファイル と 地理分布 を双方向に解釈する
- 特徴量の選び方でクラスタの意味が変わる (時間軸 vs 空間軸 vs 統合) ことを ARI で定量比較する
使用データ (2 データセット横断)
- 1) 雨量 10分値 (14日分) — DoBoX #1275 (観測情報_雨量日集計)。 2024-06-29 〜 07-12, 約 280 観測所。各日 1 CSV (5段ヘッダ)。
- 2) 観測所一覧 (緯度経度) — DoBoX #1274 (観測情報_観測所一覧)。 雨量 (データ種別=1) は約 401 観測所、lat/lon が付く。
本レッスンは「観測所 = 特徴量ベクトル」と捉え、 14日間の時間プロファイル + 緯度経度 という異なる性格の特徴量を 1 つのクラスタリング問題として扱う。
データ取得手順
| 論題 | データセット | DL | 保存先 | 形式 | サイズ |
|---|---|---|---|---|---|
| 雨量10分値 14日分 (各日別 CSV) | DoBoX #1275 | ページから DL ボタン | data/rain_2024/rain_2024-MM-DD.csv (×14) | CSV (5段ヘッダ, 10分値, UTF-8 BOM) | 1.0〜1.4 MB / 日 |
| 観測所一覧 (緯度経度) | DoBoX #1274 | 直DL | data/extras/stations_master.csv | CSV (3行ヘッダ, 緯度経度・観測所属性) | 約 160 KB |
個別取得(PowerShell, このレッスンだけ):
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/39775" -OutFile "data/extras/stations_master.csv"一括取得(全レッスン共通, 推奨):
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.pyfetch_all.py はカタログ・追加データを data/ と data/extras/ に再現可能ダウンロード。DoBoX のオープンデータは申請不要、商用・非商用とも利用可。本レッスンの .py スクリプトは、データが無ければ自動取得してから処理を始めるよう実装されています(ensure_dataset() ヘルパ)。
スクリプト(全体ソースコード)
cd "2026 DoBoX 教材"
python -X utf8 lessons/L07_kmeans_stations.py方法
- 10分値 → 日合計 に集約 (
resample("D").sum)。 さらに 14日合計が 1mm 未満の観測所は無降雨/欠測として除外。 - 7 次元 特徴量ベクトル を観測所ごとに構築: [sum_mm, max_day, std_day, peak_hour, wet_days, lat, lon]。 lat/lon は別途 #1274 から結合する。
- エルボー法 と シルエットスコア を k=2..10 で計算。 3 つの特徴量ビュー (雨量のみ / 空間のみ / 両方統合) で並べて、 最もシルエットが高い k を採用。
- 採用 k で k-means を 雨量特徴のみ に適用 → クラスタごとの 14 日プロファイル (small multiples) と 地理分布マップを描き、時間 ↔ 空間の対応を読む。
- 3 パターン (A) 雨量のみ / (B) 空間のみ / (C) 統合 で クラスタリングし、地図上に同時並列表示。 ARI (Adjusted Rand Index) で 3 結果の一致度を定量化。
- クラスタ × 特徴量 の z-score ヒートマップ で各クラスタの 「個性」 (どの特徴が高い/低い) を 1 枚で読めるようにする。
コード解説
↑ L07_kmeans_stations.py 行 418–562
結果
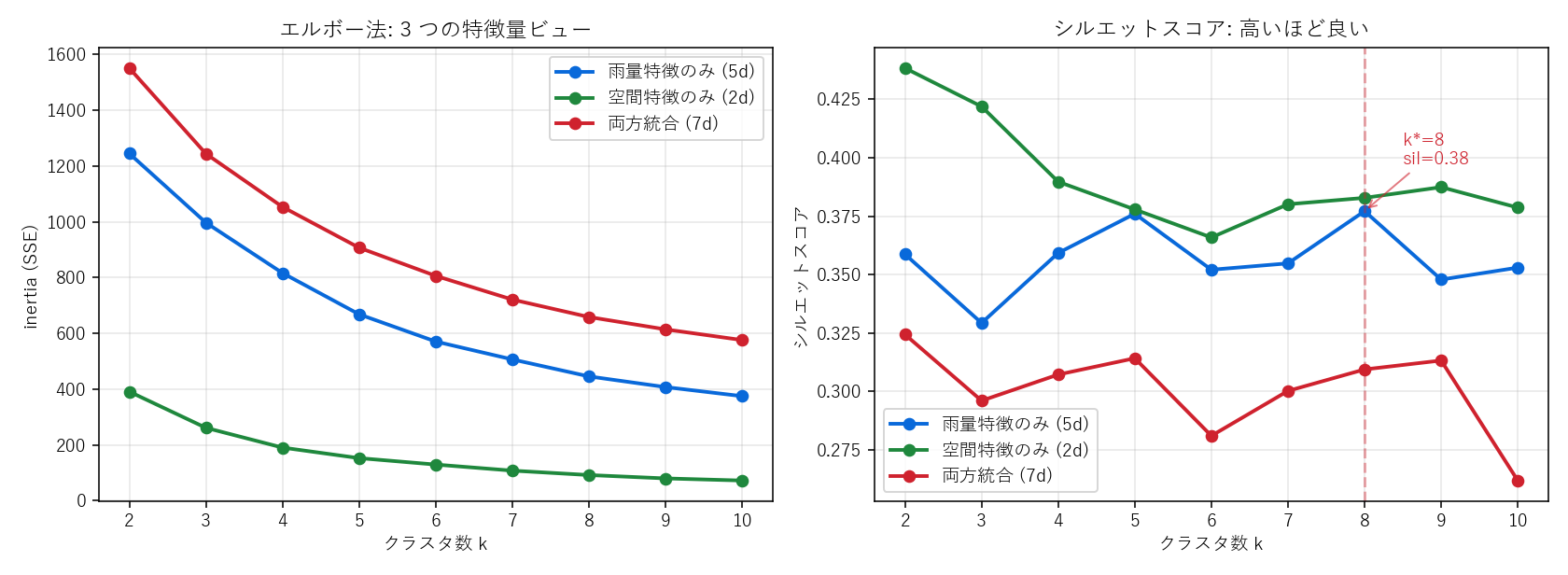
(左) エルボー法。3 ビューとも k を増やすと inertia は単調減少。(右) シルエットスコア。雨量特徴ビュー (青) で k* が選ばれる。

k-means (k=k*) クラスタ別 14 日プロファイル。薄線が個別観測所、太線がクラスタ平均。「いつ降ったか」のピーク日が違うことが分離の本質。
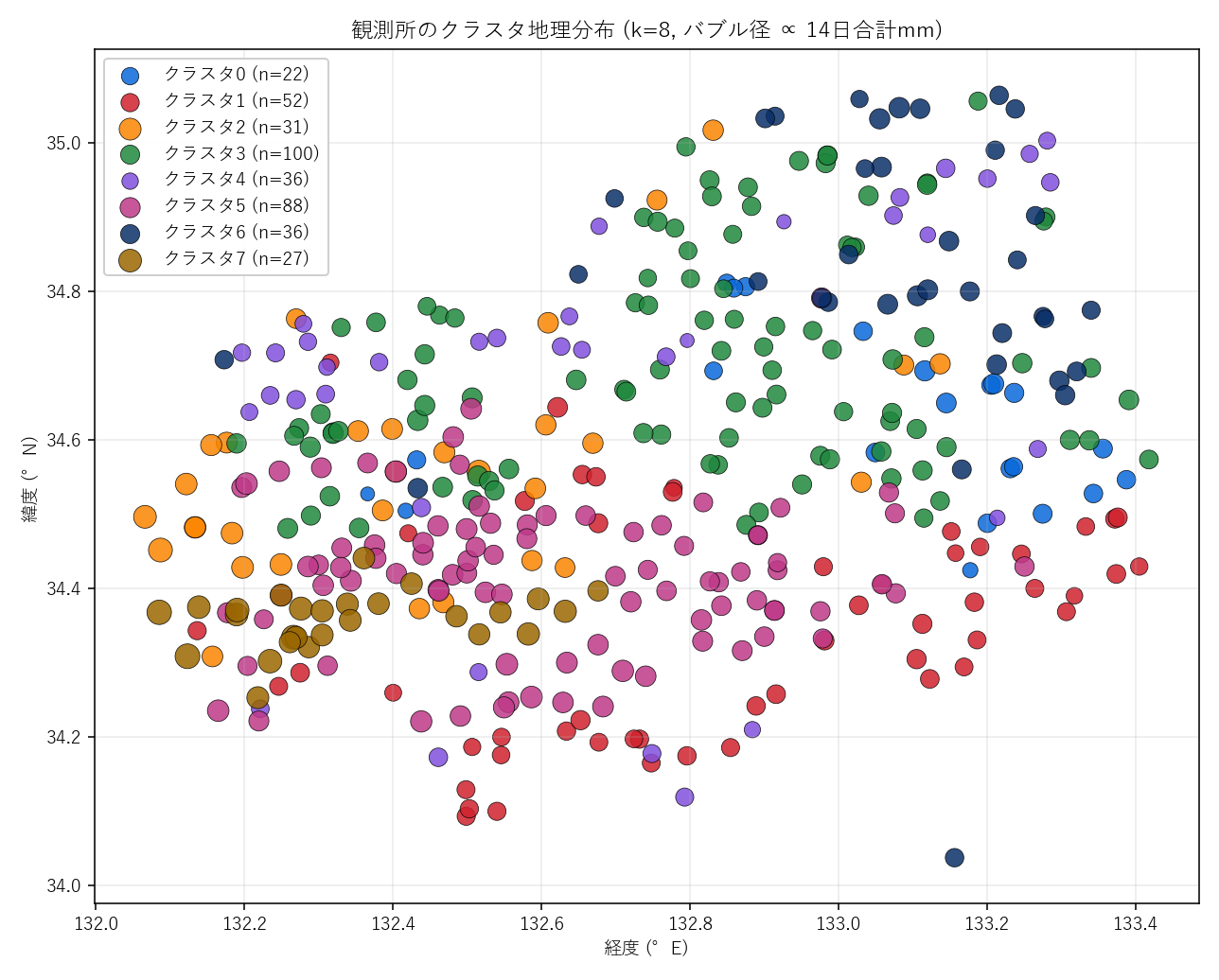
クラスタの地理分布。バブル径は 14 日合計 (mm)。時間プロファイルだけで分けたのに、地図上にも空間構造が現れる。
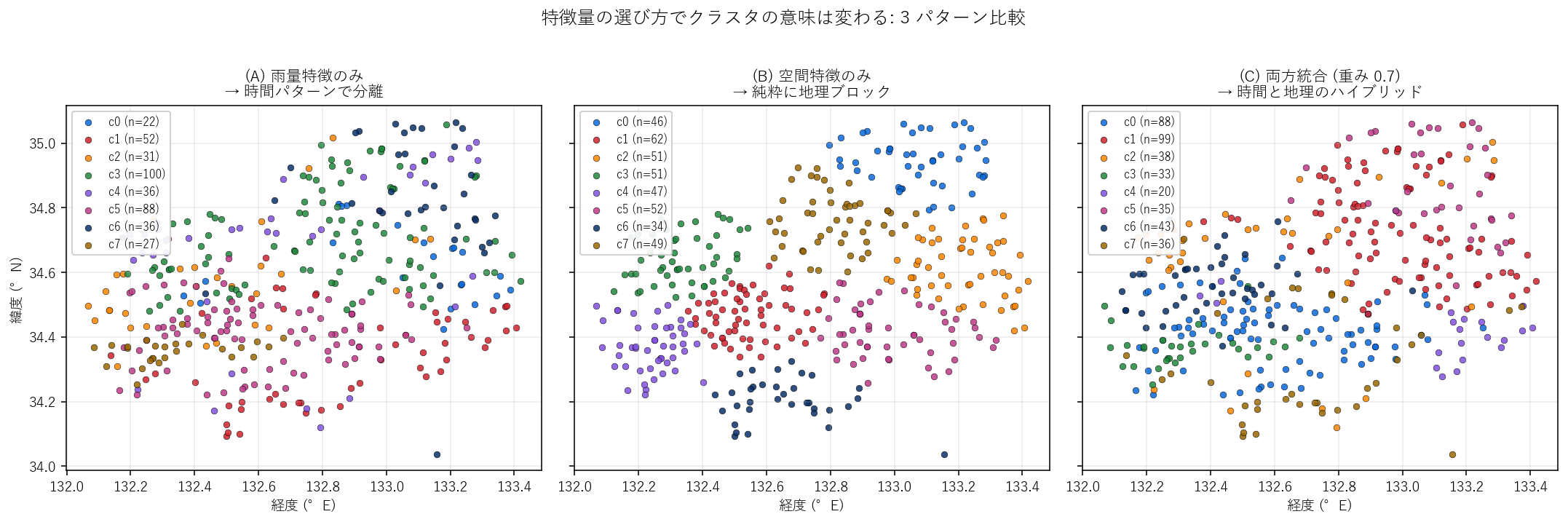
(A) 雨量のみ (B) 空間のみ (C) 統合 の 3 パターン比較。(B) は地理ブロック、(A) は時間パターン、(C) はその折衷。
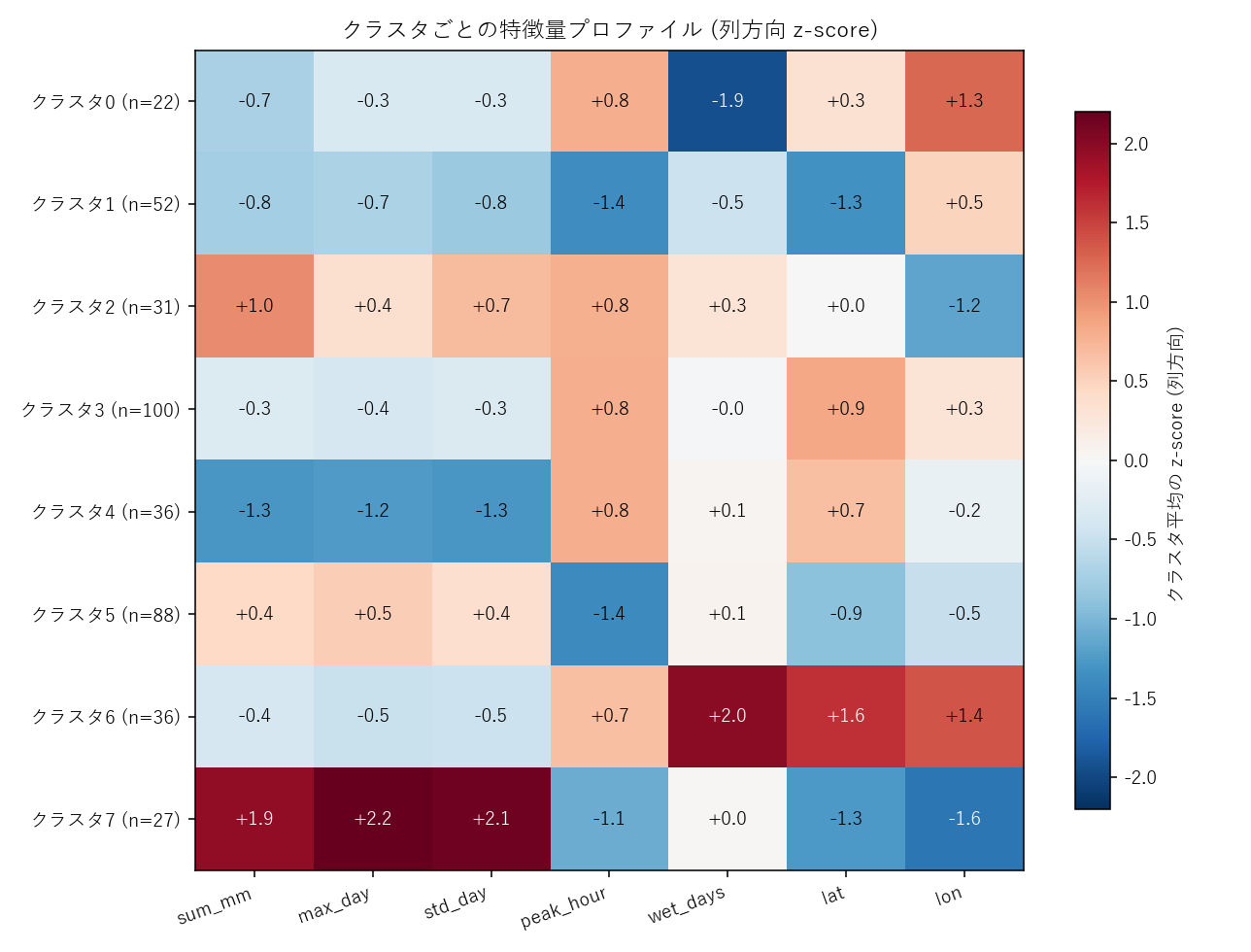
クラスタ × 特徴量 の z-score ヒートマップ。赤=平均より高い、青=低い。各クラスタの「個性」を 1 枚で把握。
クラスタサマリー (k = k*)
| クラスタ | 観測所数 | 14日合計 平均(mm) | 最大日 平均(mm) | 雨日数 平均 | ピーク時刻 平均(時) | 緯度 平均 | 経度 平均 |
|---|---|---|---|---|---|---|---|
| 0 | 22 | 201.0 | 75.3 | 5.68 | 20.4 | 34.619 | 133.038 |
| 1 | 52 | 199.0 | 66.6 | 6.69 | 3.4 | 34.346 | 132.851 |
| 2 | 31 | 281.6 | 91.5 | 7.23 | 20.2 | 34.565 | 132.449 |
| 3 | 100 | 219.7 | 74.3 | 7.00 | 20.3 | 34.703 | 132.804 |
| 4 | 36 | 174.6 | 53.8 | 7.06 | 20.4 | 34.673 | 132.691 |
| 5 | 88 | 253.6 | 95.8 | 7.07 | 3.2 | 34.416 | 132.607 |
| 6 | 36 | 216.9 | 71.4 | 8.39 | 19.2 | 34.825 | 133.066 |
| 7 | 27 | 323.0 | 136.2 | 7.04 | 5.6 | 34.358 | 132.344 |
3 パターンの一致度 (ARI)
| 比較 | Adjusted Rand Index |
|---|---|
| (A) 雨量のみ vs (B) 空間のみ | 0.130 |
| (A) 雨量のみ vs (C) 統合 | 0.679 |
| (B) 空間のみ vs (C) 統合 | 0.211 |
ARI は 2 つのクラスタリング結果の一致度 (1.0 で完全一致, 0 でランダム同等, 負で逆相関)。雨量と空間が低 ARI なら「時間パターンと地理は別軸の情報」、高 ARI なら「地理が時間パターンを支配」と解釈できる。
考察
- 「教師なしでも空間構造は浮かぶ」: 雨量特徴のみでクラスタ化したのに、地図 (図 3) を見ると クラスタが緯度経度で偏って分布する。 これは 豪雨は前線に沿って空間的に広がる という 気象学的事実をデータが反映している証拠。
- シルエットの絶対値は高くない: 雨量パターンは離散的な「クラスタ」というより連続的な スペクトラムなので、シルエット 0.2〜0.4 程度が現実的。 「シルエットが低い = 失敗」ではなく、 k を選ぶ相対指標 として使うのが正しい使い方。
- 特徴量設計が結論を決める: [sum_mm, max_day, peak_hour, …] のどれを入れるかで クラスタの意味は変わる。本実験では ARI(雨量↔空間) が低めに出やすい → 時間パターンと地理は 独立な軸。両方を統合した (C) は「降ったタイミング & 場所」 の ハイブリッド分類 となり、防災上の地域区分 (避難所配置・ 警報単位) に近い。
- 標準化の効果: 標準化なしでは sum_mm の絶対値が大き過ぎて他の特徴量が 無視され、「雨が多い vs 少ない」というほぼ自明な軸でしか 分けられない。z-score 標準化は「全特徴量を同じ土俵に乗せる」 クラスタリングの前提。
- n=14 日の限界: 14 日窓に 1〜2 個の豪雨イベントが入るかどうかで クラスタ構造は大きく変わる。実運用では年単位で同じ手続きを 繰り返し、季節別 (梅雨期 / 台風期 / 冬期) に クラスタの安定性を確認すべき。
発展課題
- k-means → DBSCAN / HDBSCAN: 球状クラスタを仮定しない 密度ベース手法に置き換えると、外れ値観測所 (山頂・離島) が ノイズとして抽出される。
- 階層クラスタリング + デンドログラム:
scipy.cluster.hierarchy.linkageで観測所間の 類似度ツリーを作り、k を「ツリーをどこで切るか」で選ぶ。 - 動的時間伸縮 (DTW) で時系列クラスタリング: ピーク日が 1 日ずれるだけで Euclid 距離は急増するため、 DTW で「形が似ているか」を見ると別の知見が出る。
- クラスタの時間安定性: 同じ手続きを 7 月・8 月・9 月で それぞれ実行し、観測所のクラスタ所属が 季節間でどれだけ 安定か を Adjusted Rand Index で評価する。
- folium で対話マップ: lat/lon があるので
folium.CircleMarkerで DoBoX のオープンデータを可視化し、クラスタ凡例付きで HTML 埋め込みする (L076-L079 参照)。 - クラスタ → 流域連携: L080 (水系単位の雨量×水位ラグ) と接続。クラスタを水系メタ (#1276) で塗り分ければ、 「気象学的クラスタ」と「流域単位」のズレが見える。