14日豪雨ヒートマップ — 2024 広島豪雨の空間×時間構造
学習目標
- 14ファイル(各日10分値)を ループで連結 し、
(観測所 × 日)という二次元マトリクスに再構成できる - 「最大」「中央値」「上位N平均」「90/99パーセンタイル」など 代表値の使い分け を場面ごとに選べる
- 2024年7月の広島豪雨を題材に、ヒートマップで空間×時間の同時可視化を行い、雨域の広がりとピーク構造を読む
- 個別観測所(ミクロ)・事務所(地域=メソ)・県全体(マクロ) の 3 階層の集約スケールでデータを見る発想を持つ
- ECDF (経験累積分布関数) で「裾の重さ」を視覚化し、極端値の位置づけを評価できる
使用データ
- 名称 観測情報_雨量日集計 (10分値) 14日分
- 提供 DoBoX #1275 (広島県インフラマネジメント基盤)
- 期間 2024-06-29 〜 2024-07-12 (令和6年7月豪雨を含む)
- 観測所 約 280 (砂防課・河川課・国土交通省・気象台・治山雨量・国ダム ほか)
- 形式 CSV / 5 段ヘッダ (事務所名・データ所管・水系名・河川名・観測所名 + 観測時刻列) / UTF-8 BOM
- サイズ 1ファイルあたり 1.0〜1.4 MB × 14 = 約 18 MB
- 補助 DoBoX #1276 雨量年集計 — 本レッスンでは「観測所→事務所」のマップだけ抽出して空間グルーピングに使う
14日分の CSV は 各日が独立した 1 ファイル なので、リソース ID も日ごとに違う。
本スクリプトは下記の RAIN_RID 辞書 (14 リソース) を使って ensure_dataset() で並列に取得する。
データ取得手順
| 論題 | データセット | DL | 保存先 | 形式 | サイズ |
|---|---|---|---|---|---|
| 雨量10分値 2024-06-29 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-06-29.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-06-30 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-06-30.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-01 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-01.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-02 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-02.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-03 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-03.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-04 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-04.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-05 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-05.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-06 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-06.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-07 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-07.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-08 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-08.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-09 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-09.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-10 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-10.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-11 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-11.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量10分値 2024-07-12 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-12.csv | CSV (5段ヘッダ, 10分値) | 1.0〜1.4 MB |
| 雨量年集計 (事務所メタの参照) | DoBoX #1276 | ページから DL ボタン | data/extras/rainfall_annual.csv | CSV (多段ヘッダ) | 約 500 KB |
個別取得(PowerShell, このレッスンだけ):
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/94490" -OutFile "data/rain_2024/rain_2024-06-29.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94495" -OutFile "data/rain_2024/rain_2024-06-30.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94500" -OutFile "data/rain_2024/rain_2024-07-01.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94505" -OutFile "data/rain_2024/rain_2024-07-02.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94510" -OutFile "data/rain_2024/rain_2024-07-03.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94515" -OutFile "data/rain_2024/rain_2024-07-04.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94520" -OutFile "data/rain_2024/rain_2024-07-05.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94525" -OutFile "data/rain_2024/rain_2024-07-06.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94530" -OutFile "data/rain_2024/rain_2024-07-07.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94535" -OutFile "data/rain_2024/rain_2024-07-08.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94540" -OutFile "data/rain_2024/rain_2024-07-09.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94545" -OutFile "data/rain_2024/rain_2024-07-10.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94551" -OutFile "data/rain_2024/rain_2024-07-11.csv"
iwr "https://hiroshima-dobox.jp/resource_download/94556" -OutFile "data/rain_2024/rain_2024-07-12.csv"一括取得(全レッスン共通, 推奨):
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.pyfetch_all.py はカタログ・追加データを data/ と data/extras/ に再現可能ダウンロード。DoBoX のオープンデータは申請不要、商用・非商用とも利用可。本レッスンの .py スクリプトは、データが無ければ自動取得してから処理を始めるよう実装されています(ensure_dataset() ヘルパ)。
取得スクリプト内蔵: 本レッスンの L05_14days_heavy_rain.py は、
RAIN_RID 辞書 (14 日分) を使って ensure_dataset() ヘルパで 14ファイル+1メタを順次自動DLします。
HTML を読んで PowerShell で個別取得しても、fetch_all.py で一括取得しても、結果は同じです。
スクリプト(全体ソースコード)
cd "2026 DoBoX 教材"
python -X utf8 lessons/L05_14days_heavy_rain.py方法
- 14 リソース ID で 14 ファイル取得:
RAIN_RID = {"2024-06-29": 94490, ..., "2024-07-12": 94556}をensure_dataset(resource_id=...)でループ DL - 各日CSVを tidy 化:
parse_rain_csv()(年度差分対応) で(時刻 × 観測所)の 10 分値 DataFrame に - 日合計に集約:
tidy.sum(axis=0, min_count=1)で観測所ごとの日合計 Series - 14日分を横結合:
pd.concat([...], axis=1)で(観測所 × 日)マトリクス M - 事務所メタの結合:
rainfall_annual.csvの 0 行目(事務所名) と 4 行目(観測所名) から{station: office}辞書を構築 - 5 種類の可視化: 全観測所ヒートマップ / 上位10 small multiples / 事務所×日 集約ヒートマップ / 日別代表値ピラミッド+雨域広がり / 14日合計 ECDF
- サマリ表: 期間/観測所数/ピーク日/最大観測所/分位点 を 1 表に集約
コード解説
↑ L05_14days_heavy_rain.py 行 371–501
結果
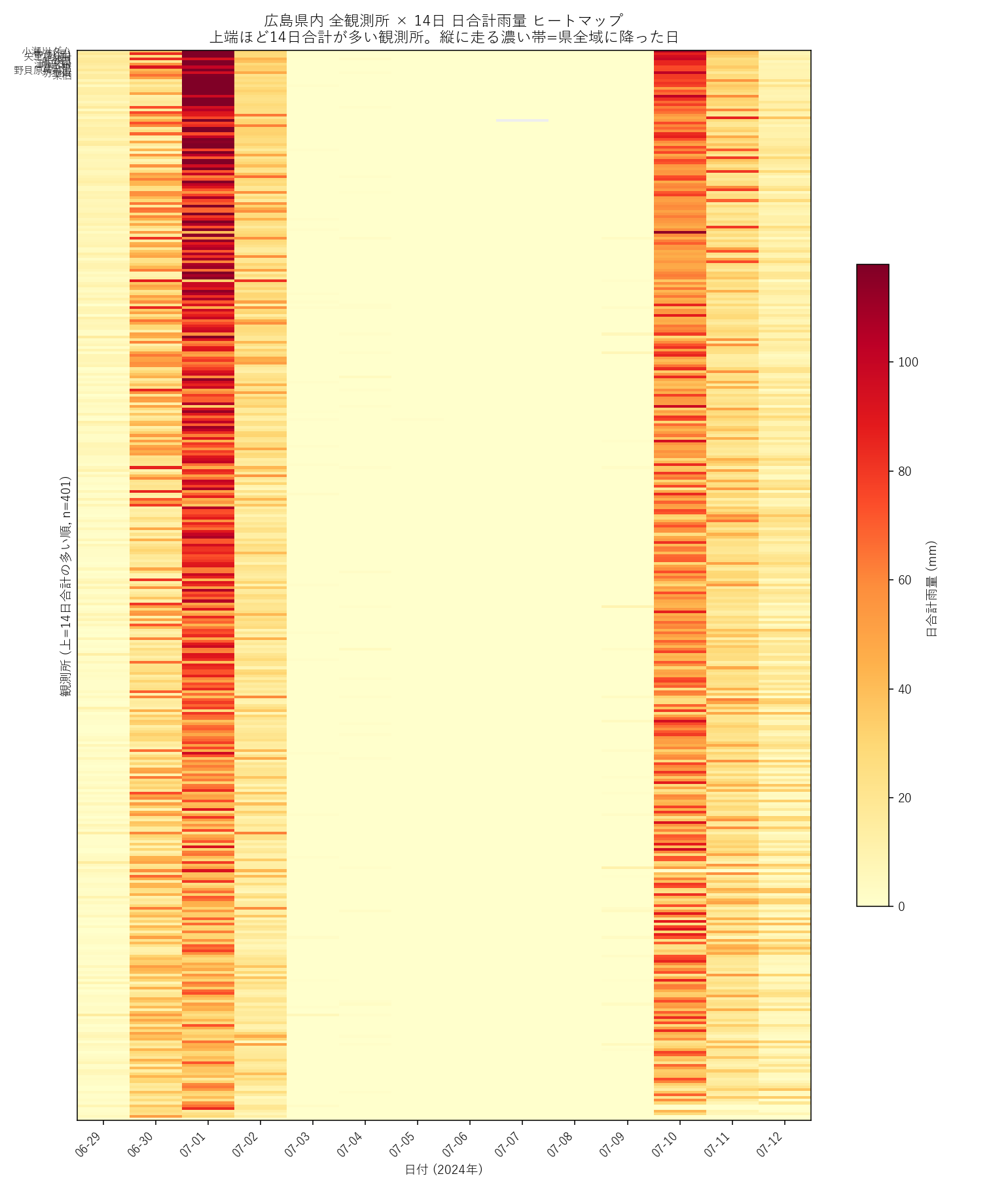
全観測所(n=401) × 14日 ヒートマップ。縦軸は14日合計の多い順。縦に走る濃い帯=県全域に降った日、点状の濃さ=局所豪雨を示す
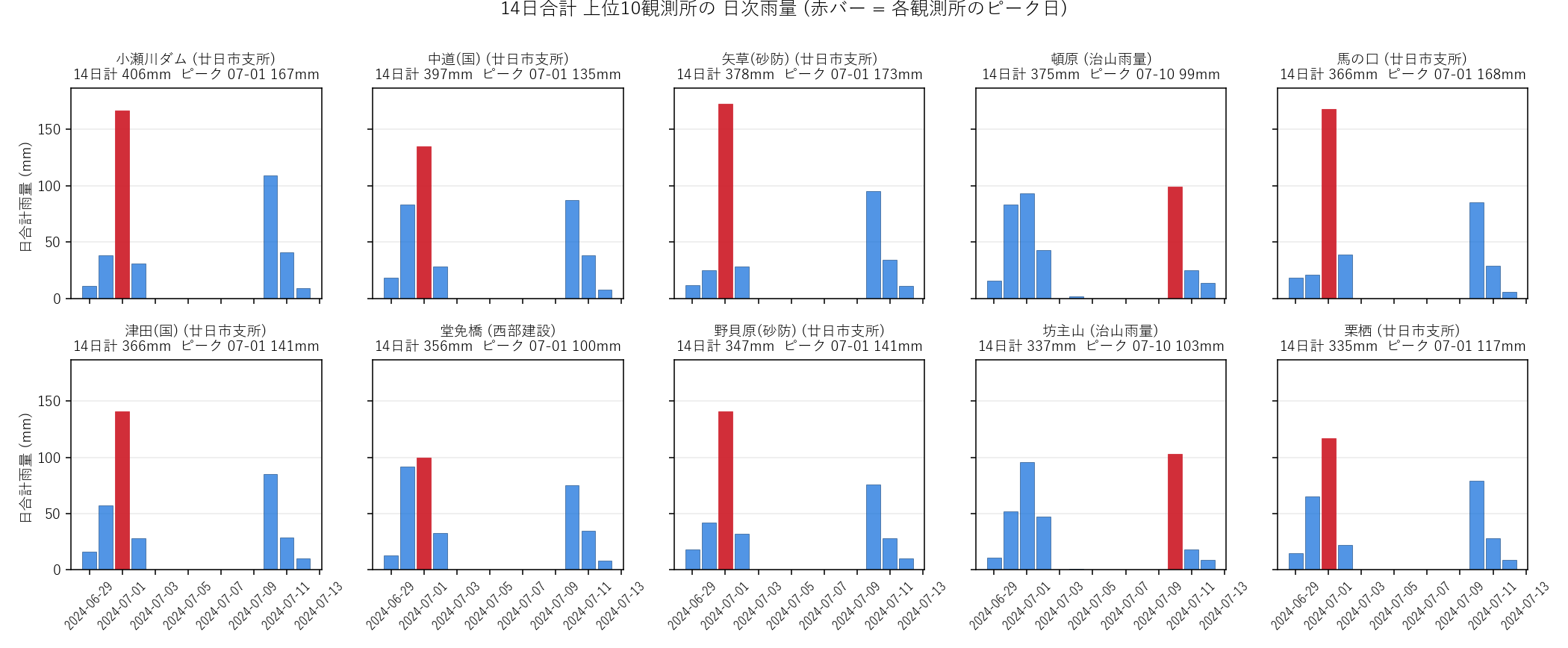
14日合計上位10観測所の日次バー (赤=各観測所のピーク日)。ピーク日が06-30〜07-01に集中する観測所と07-08〜07-10にずれる観測所がある
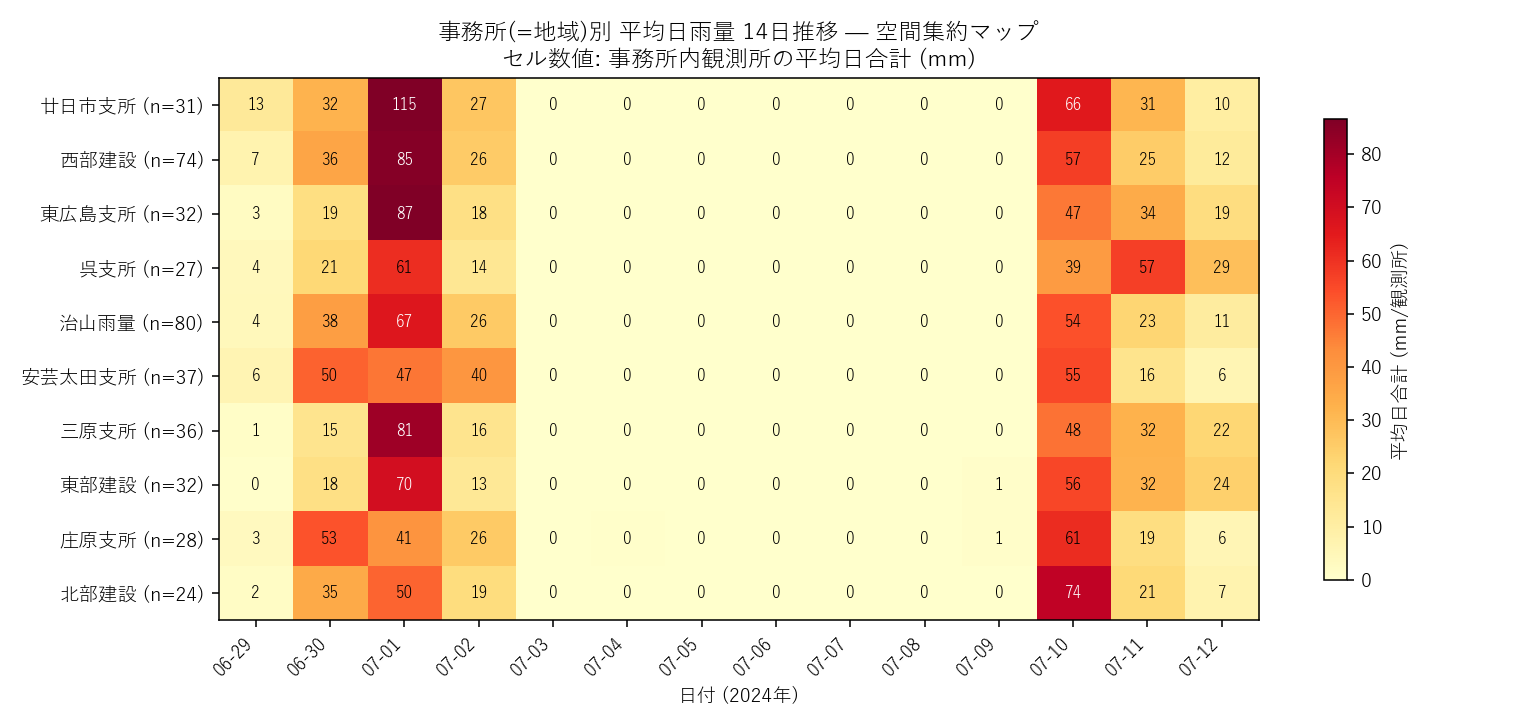
事務所(=地域区分)×日 の平均日雨量ヒートマップ。観測所280点を10程度の事務所に集約することで、雨域の南北・東西の動きが読める
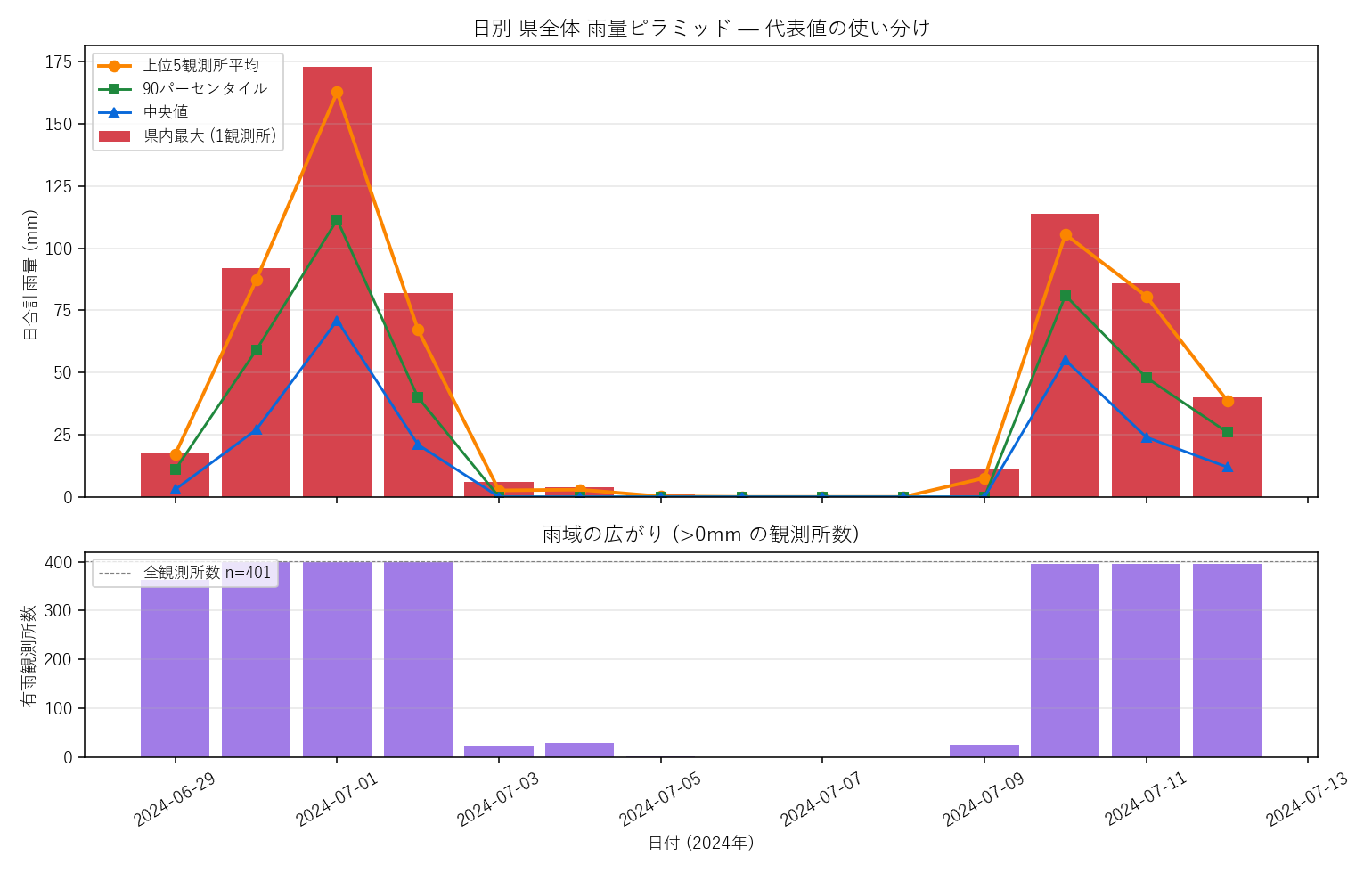
上: 日別の代表値ピラミッド (赤バー=県内最大, 橙=上位5平均, 緑=90%点, 青=中央値)。下: 有雨観測所数 (>0mm)。同じ日でも代表値ごとに様相が違う
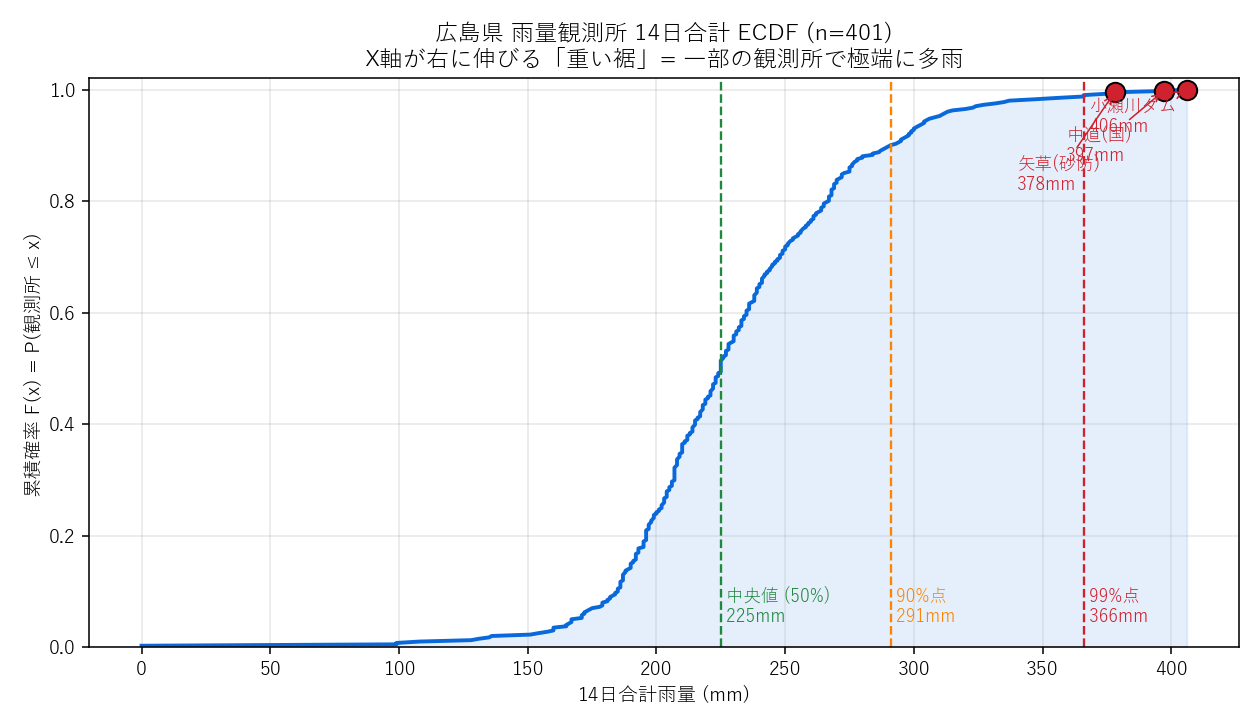
14日合計の経験累積分布。緑=中央値・橙=90%点・赤=99%点。右へ伸びる重い裾=ごく一部の観測所が極端に多雨
期間サマリ
| 対象期間 | 2024-06-29 〜 2024-07-12 (14日) |
|---|---|
| 観測所数 | 401 観測所 |
| 事務所数(地域区分) | 10 |
| 14日 県全体総雨量 | 92,402 mm (観測所×日 の合計) |
| ピーク日(県内最大) | 07-01 (173 mm) |
| ピーク日 最大観測所 | 矢草(砂防) |
| 14日合計 最多観測所 | 小瀬川ダム (406 mm) |
| 14日合計 中央値 | 225 mm |
| 14日合計 90%点 | 291 mm |
| 14日合計 99%点 | 366 mm |
14日合計 上位10観測所
| 観測所 | 事務所 | 14日合計(mm) | ピーク日 | ピーク値(mm) |
|---|---|---|---|---|
| 小瀬川ダム | 廿日市支所 | 406.0 | 07-01 | 167.0 |
| 中道(国) | 廿日市支所 | 397.0 | 07-01 | 135.0 |
| 矢草(砂防) | 廿日市支所 | 378.0 | 07-01 | 173.0 |
| 頓原 | 治山雨量 | 375.0 | 07-10 | 99.0 |
| 馬の口 | 廿日市支所 | 366.0 | 07-01 | 168.0 |
| 津田(国) | 廿日市支所 | 366.0 | 07-01 | 141.0 |
| 堂免橋 | 西部建設 | 356.0 | 07-01 | 100.0 |
| 野貝原(砂防) | 廿日市支所 | 347.0 | 07-01 | 141.0 |
| 坊主山 | 治山雨量 | 337.0 | 07-10 | 103.0 |
| 栗栖 | 廿日市支所 | 335.0 | 07-01 | 117.0 |
考察
- 「平均」を見ると豪雨は消える: 中央値ベースの折れ線は 14 日のうちほとんどの日で 0〜数mm。県内最大 (赤バー) が 100mm を超える日にだけスパイクが立つ。豪雨は集計を外さない限り見えない極端事象であることを、L05 の 5 つの代表値が同時に示す。
- 2 つのピーク日: 全観測所ヒートマップで縦に走る濃い帯は 2024-06-30〜07-01 と 2024-07-08〜07-10 の 2 ヶ所に明確に現れる。前者は前線型 (広域・中等量)、後者は局所性が強い (一部観測所で200mm超だが多くの観測所は0)。事務所×日ヒートマップで 地域による降雨タイミングのズレ も読み取れる。
- 空間集約のスケール選び: 280 観測所のままでは情報過多、県全体平均では情報損失。事務所(地域)単位の集約が「ちょうど良い解像度」になる。これは L080 の 水系単位集約 と同じ発想で、応用基礎の核心は「適切な集約粒度を選ぶ」こと。
- ECDF の重い裾は「平均が代表値にならない」サイン: 14 日合計が中央値の数倍を超える観測所が 5% ほどある (99%点が中央値の 4〜5 倍)。正規分布前提のt検定や平均比較はこの場合に強い誤導。代わりに分位点や順位ベースの指標を使うべき、というのが分布形状から導かれる教訓。
- 「有雨観測所数」というメタ指標: 雨量の強さ (mm) ではなく、降った観測所の比率 (=雨域の広がり) を別軸で示すと、同じ100mmでも「広域型」と「局所型」が区別できる。これは梅雨前線/線状降水帯/局地的雷雨を見分ける現場感覚と直結する。
発展課題
- 10 分粒度のままヒートマップを描く: 日合計に潰さず、(観測所 × 144スロット × 14日) の 3 次元配列を時間軸に並べた長尺ヒートマップで 線状降水帯の通過を可視化する。matplotlib の
imshowでも 280 × 2016 = 56 万セル程度なら十分扱える。 - 事務所地域 → 緯度経度マップ: 観測所の位置情報 (DoBoX #1275 の観測所諸元 or 国交省 XRAIN メタ) を結合し、folium で 14日合計の色付き円マーカー をプロットする。本レッスンは事務所単位の集約で代用したが、座標があれば真の空間ヒートマップに格上げできる。
- 豪雨日の「同時性」検定: 2024-07-01 と 2024-07-10 で多雨の観測所がどれだけ重なるか、Jaccard 係数や Spearman 順位相関で評価。広域前線型と局所型で「上位観測所の入れ替わり」がどれだけ起きるかを定量化する。
- ECDF の片対数プロット → 裾指数推定: ECDF の生存関数 1-F(x) を log-log でプロットし、裾部分が直線にのるか検査。直線なら パレート分布、降雨の極値統計 (GEV, GPD) との接続。L210 の極値解析と接続する。
- 過去年度との比較: 同じ DoBoX #1275 で 2018年豪雨期間 (2018-07-04 〜 07-08) のリソースを取得し、2024年豪雨と比較する。観測所数・地点・代表値の違いを直接議論できる (時系列の長期トレンド観察)。