雨量CSV — データ前処理の解剖 (tidy 化)
学習目標
- 観測現場系の 多段ヘッダ × ワイド CSV を tidy data へ整形できる
- ヘッダ行を「位置」ではなく 「内容 (10分雨量を含む)」 で動的検出できる
- 観測所メタ (事務所 / 水系 / 河川) を 別 DataFrame に分離 し、階層構造を可視化できる
- 欠測パターンを 観測所×時刻ヒートマップ で見抜ける
- フラグ列 (16進数) を bit 単位に分解 して、各 bit の意味を頻度から推測できる
- 整形プロセスを 「品質指標」 で要約できる (raw shape, tidy shape, 欠測率, ユニーク観測所数)
使用データ
- 名称 観測情報_雨量日集計(10分値)
- 出典 DoBoX dataset #1275 / resource_id=94500(2024-07-01分)
- 形状 約 150 行 × 1605 列(401観測所 × 4列構造 + 時刻列)
- 4 列構造 各観測所に
10分雨量[mm] / フラグ / 累計雨量[mm] / フラグ - 5段ヘッダ 事務所名 / データ所管 / 水系名 / 河川名 / 観測所番号 / 観測所名 (+ 観測時刻ヘッダ)
データ取得手順
| 論題 | データセット | DL | 保存先 | 形式 | サイズ |
|---|---|---|---|---|---|
| 雨量10分値 2024-07-01 | DoBoX #1275 | 直DL | data/rain_2024/rain_2024-07-01.csv | CSV (5段ヘッダ, 1605列, UTF-8 BOM) | 約 1.8 MB |
個別取得(PowerShell, このレッスンだけ):
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/94500" -OutFile "data/rain_2024/rain_2024-07-01.csv"一括取得(全レッスン共通, 推奨):
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.pyfetch_all.py はカタログ・追加データを data/ と data/extras/ に再現可能ダウンロード。DoBoX のオープンデータは申請不要、商用・非商用とも利用可。本レッスンの .py スクリプトは、データが無ければ自動取得してから処理を始めるよう実装されています(ensure_dataset() ヘルパ)。
スクリプト(全体ソースコード)
cd "2026 DoBoX 教材"
python -X utf8 lessons/L04_tidy_rainfall.py方法
- header=None で全部「データ」として読込: 多段ヘッダがある CSV は素直に
read_csvせず、まず生表として確保 - ヘッダ位置の動的検出: 各行の "10分雨量" 出現件数を数え、最大の行をヘッダとする (位置で取らず内容で取る)
- 観測所メタの抽出: ヘッダより上の行を
meta DataFrameに分離 (事務所/所管/水系/河川/番号/観測所)。観測所ごとの4列繰り返しの中で 10分雨量列のみを残す - 値部分の数値化と tidy 化: 10分雨量の列だけ抜き、観測所名を列名に、時刻を index に
- 完備性チェック: 観測所×時刻 の欠測ヒートマップ (黒=NaN) で、観測停止 / センサ故障 / 欠落を可視化
- フラグ列の解読: 0x... を整数に変換し、bit ごとに立っている件数を集計 → 各 bit が「観測あり/欠測/異常」のどれかを推測
- 整形品質指標: raw shape, tidy shape, 欠測率, ユニーク観測所数 をサマリ表に
コード解説
↑ L04_tidy_rainfall.py 行 19–495
結果
① 生 CSV のスナップショット (先頭8行 × 先頭7列)
| 事務所名 | 西部建設 | 西部建設 | ||||
| データ所管 | 砂防課 | 気象台 | ||||
| 水系名 | 太田川 | 太田川 | ||||
| 河川名 | 天満川 | 京橋川 | ||||
| 観測所番号 | 80 | 7437 | ||||
| 観測所名 | 江波 | 広島(気) | ||||
| 観測時刻 | 10分雨量[mm] | フラグ | 累計雨量[mm] | フラグ | 10分雨量[mm] | フラグ |
| 2024/07/01 00:00 | 0.0 | 0x00000000 | 16.0 | 0x00010000 | 0.5 | 0x00000000 |
5 段ヘッダ + 観測時刻ヘッダ。各観測所は 4 列を占有 (10分雨量/フラグ/累計/フラグ)。空セル (NaN) が観測所間の繰り返しに見える。
② ヘッダ位置の動的検出スキャン
| row | first_cell | n_10分雨量 | is_観測所名行 | is_河川名行 |
|---|---|---|---|---|
| 0 | 事務所名 | 0 | False | False |
| 1 | データ所管 | 0 | False | False |
| 2 | 水系名 | 0 | False | False |
| 3 | 河川名 | 0 | False | True |
| 4 | 観測所番号 | 0 | False | False |
| 5 | 観測所名 | 0 | True | False |
| 6 | 観測時刻 | 401 | False | False |
| 7 | 2024/07/01 00:00 | 0 | False | False |
| 8 | 2024/07/01 00:10 | 0 | False | False |
| 9 | 2024/07/01 00:20 | 0 | False | False |
| 10 | 2024/07/01 00:30 | 0 | False | False |
| 11 | 2024/07/01 00:40 | 0 | False | False |
| 12 | 2024/07/01 00:50 | 0 | False | False |
| 13 | 2024/07/01 01:00 | 0 | False | False |
| 14 | 2024/07/01 01:10 | 0 | False | False |
"10分雨量" 出現件数が最大の行 = ヘッダ行。 "観測所名" で始まる行 = 観測所名行。位置で取らず内容で取るので、 2023 年式 (5 段ヘッダ) でも 2024 年式 (6 段ヘッダ) でも壊れない。
③ tidy DataFrame (観測所×時刻, 先頭6行 × 先頭6観測所)
| 江波 | 広島(気) | 広島(国) | 牛田早稲田 | 中山新町 | 温品(砂防) | |
|---|---|---|---|---|---|---|
| datetime | ||||||
| 2024-07-01 00:00 | 0.0 | 0.5 | 0.0 | 0.0 | 1.0 | 1.0 |
| 2024-07-01 00:10 | 1.0 | 1.5 | 2.0 | 1.0 | 1.0 | 0.0 |
| 2024-07-01 00:20 | 0.0 | 0.5 | 0.0 | 1.0 | 0.0 | 1.0 |
| 2024-07-01 00:30 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2024-07-01 00:40 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2024-07-01 00:50 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
shape: 144 時刻 × 401 観測所。 1 行 = 1 時刻、1 列 = 1 観測所、値 = 10 分雨量 (mm)。
④ 観測所メタ DataFrame (先頭8件)
| office | owner | system | river | sid | station |
|---|---|---|---|---|---|
| 西部建設 | 砂防課 | 太田川 | 天満川 | 80 | 江波 |
| 西部建設 | 気象台 | 太田川 | 京橋川 | 7437 | 広島(気) |
| 西部建設 | 国土交通省 | 太田川 | 京橋川 | 13 | 広島(国) |
| 西部建設 | 砂防課 | 太田川 | 二又川 | 86 | 牛田早稲田 |
| 西部建設 | 砂防課 | 太田川 | 中山川 | 85 | 中山新町 |
| 西部建設 | 国土交通省 | 太田川 | 戸坂川(矢口川) | 65 | 温品(砂防) |
| 西部建設 | 砂防課 | 太田川 | 小河原川 | 84 | 福木 |
| 西部建設 | 河川課 | 太田川 | 京橋川 | 1 | 西部建設 |
事務所 → 水系 → 河川 → 観測所 という 4 段の階層構造。観測所メタを別 DataFrame に切り出すと、 水系単位の集約 (L080) や河川単位の地図 (L02) と連携できる。
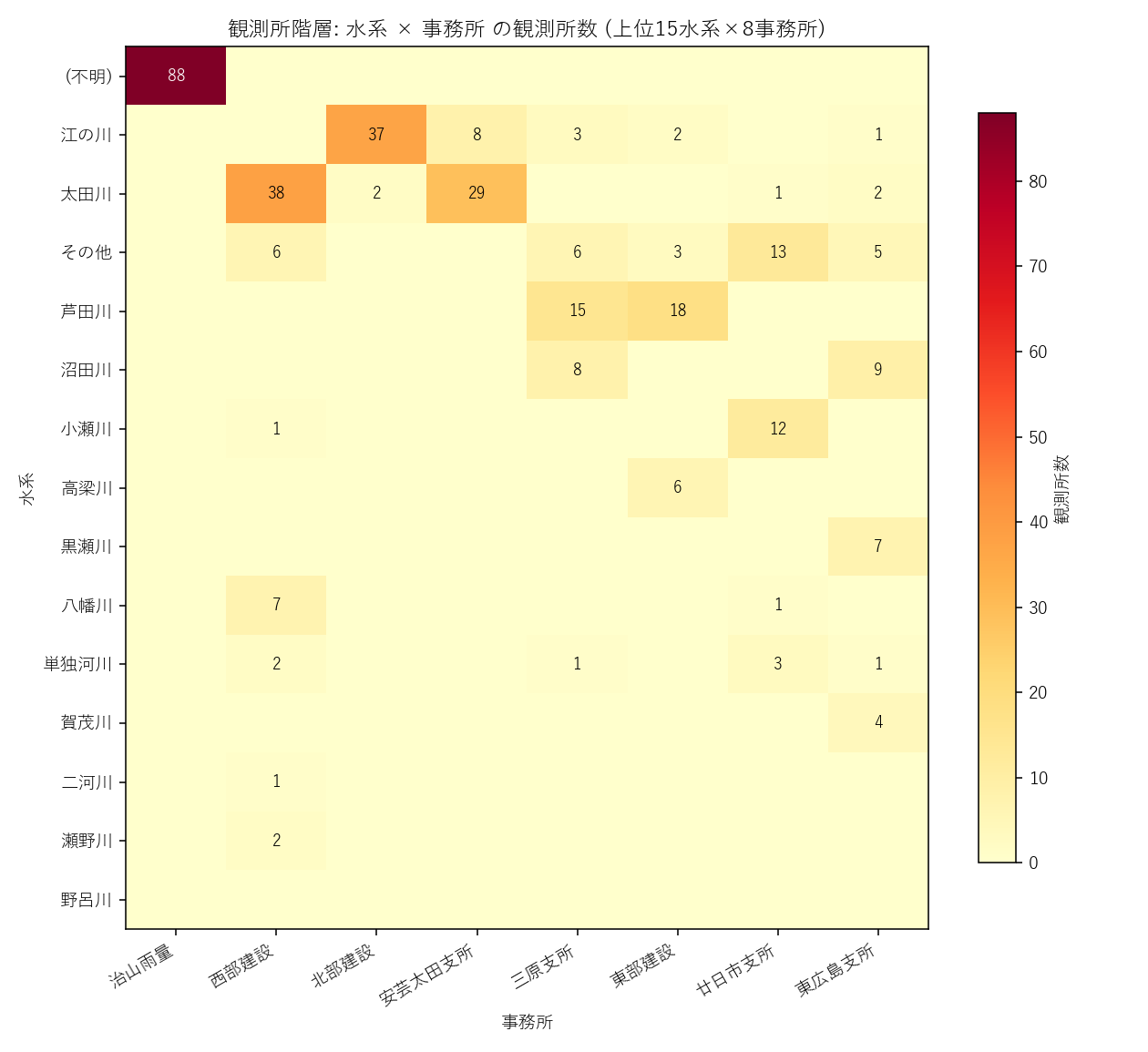
観測所階層: 水系 × 事務所 の観測所数ヒートマップ。同じ水系内に複数の事務所が観測網を持つ重層的な体制が見える
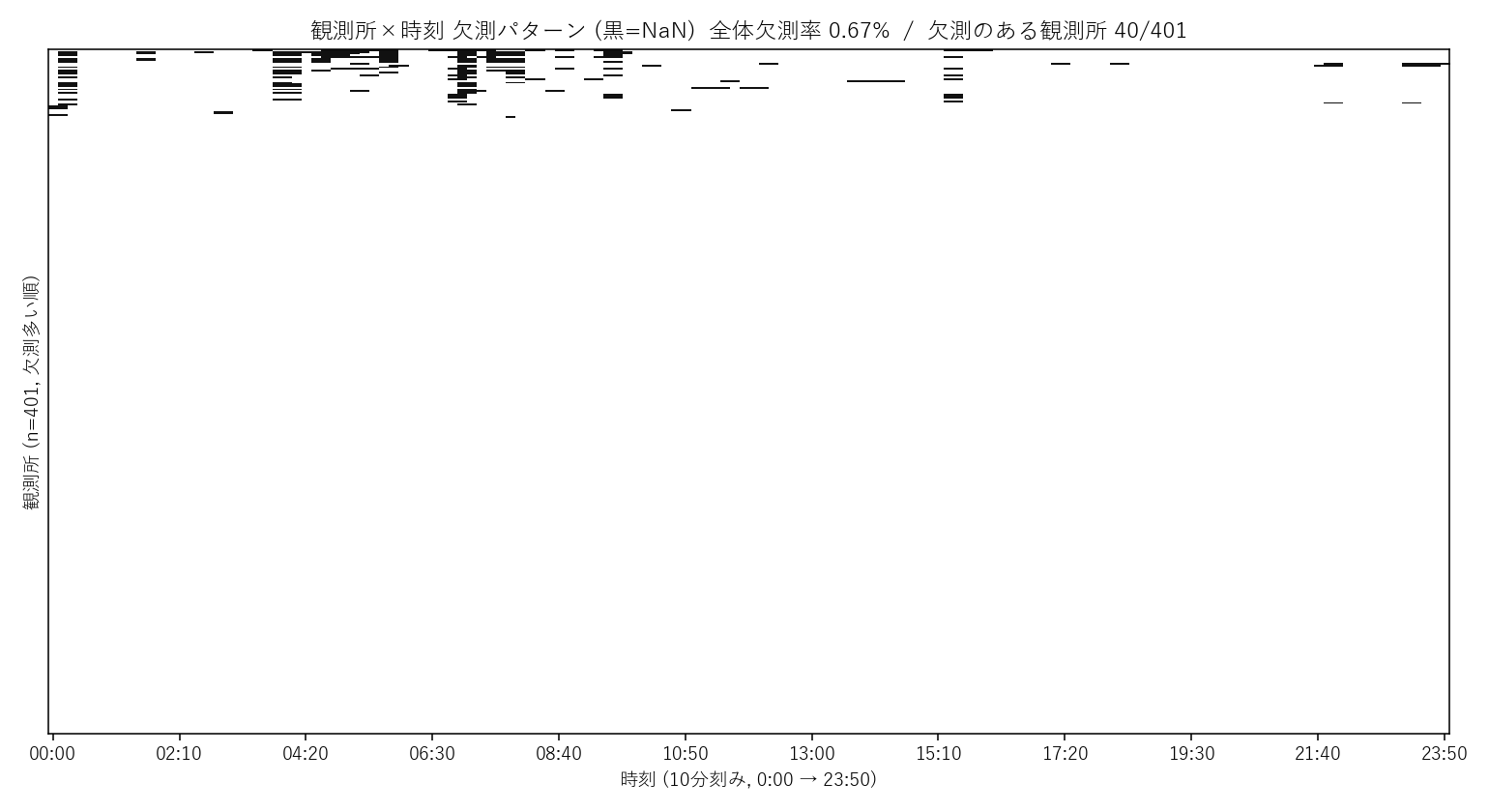
観測所×時刻 の欠測パターン (黒=NaN)。1 日通して欠測している観測所と、部分的に欠測する観測所がある。横筋が出ているのは「観測停止 (センサ故障)」のサイン
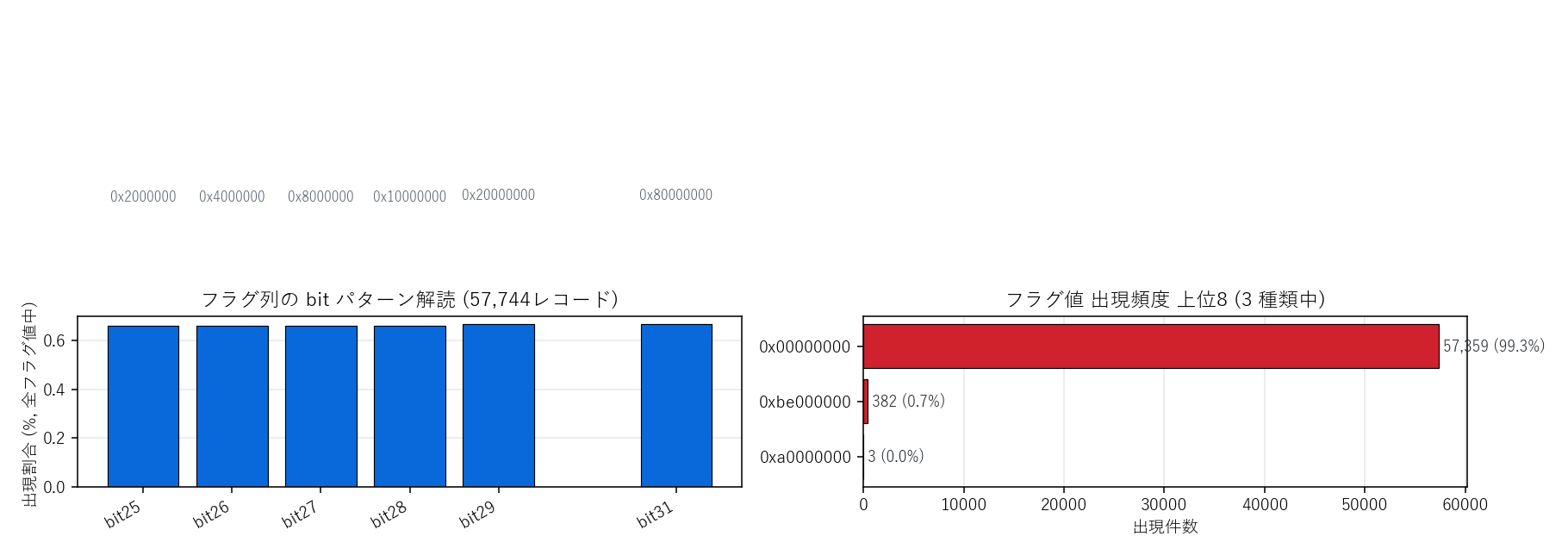
フラグ列の解読。(左) 各 bit が立っている割合 — 大半が 0x00000000 で全 bit=0 (=正常観測)。立つ bit はごく一部のレコードのみで、欠測/異常状態に対応すると推測できる。(右) フラグ値別の出現頻度 上位8
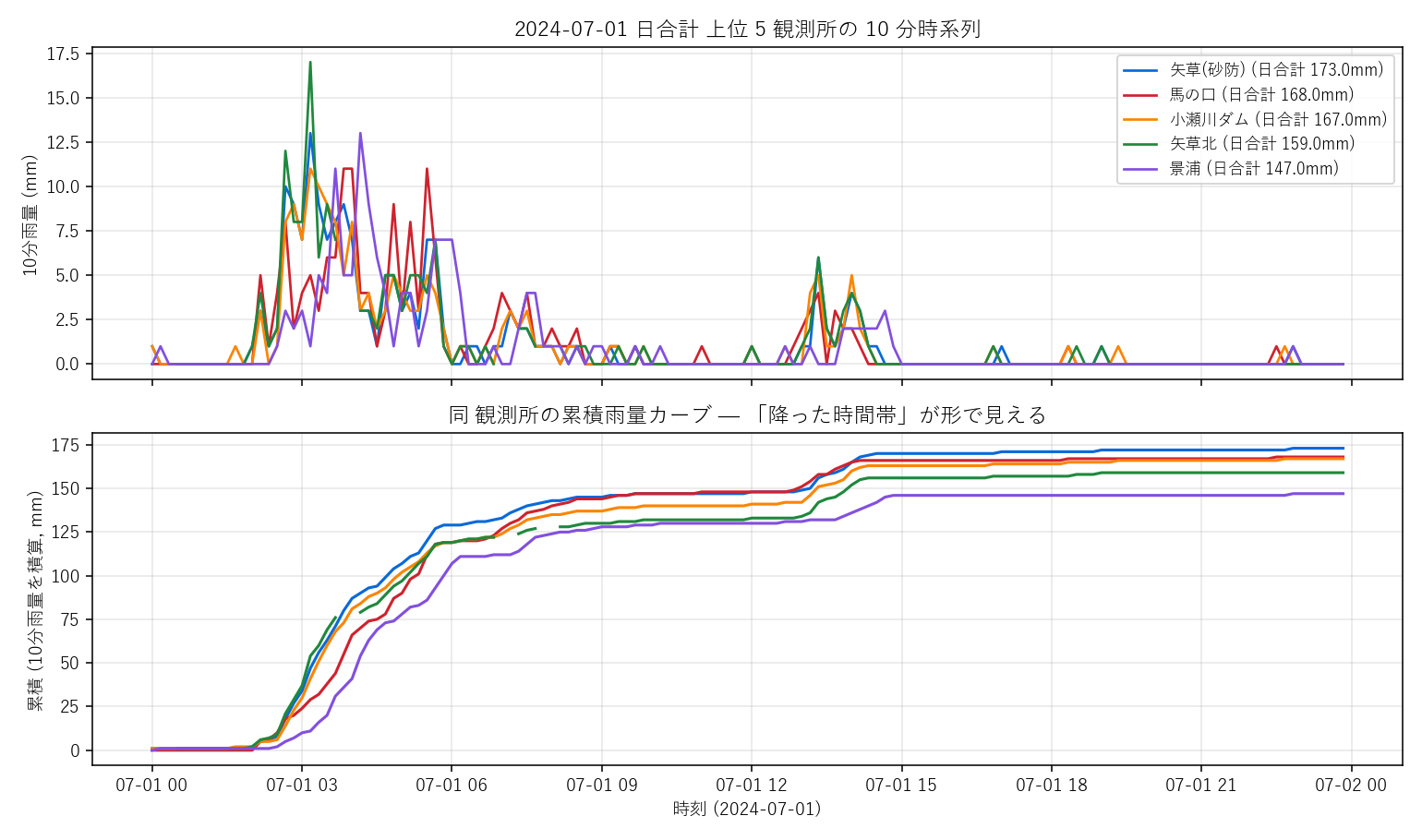
日合計上位5観測所の10分雨量 (上) と累積雨量 (下)。tidy DataFrame からは 1 行で <code>tidy.cumsum()</code> と書けて即座に可視化できる
⑤ 整形品質サマリ
| 項目 | 値 |
|---|---|
| 生 CSV shape | 151 × 1605 |
| 生 CSV 列数の内訳 | 1 (時刻) + 1604 (= 401 観測所 × 4 列) |
| ヘッダ行の動的検出 | row=6 で '10分雨量' を発見 |
| 観測所名行の検出 | row=5 |
| メタ行 (事務所/所管/水系/河川/番号/観測所) | row 0〜5 |
| tidy 後 shape | 144 時刻 × 401 観測所 |
| ユニーク観測所数 (重複名連番化前) | 393 → 連番化後 401 |
| 水系数 / 事務所数 / 河川数 | 19 / 10 / 138 |
| セル全体の欠測率 | 0.667% |
| 欠測のある観測所数 | 40 / 401 |
| フラグ列のユニーク値数 | 3 |
| フラグ最多値 | 0x00000000 (57,359件) |
考察
- 「位置で取らず内容で取る」が前処理の心得: ヘッダ行の動的検出 (10分雨量を含む行を探す) は、年度違い・仕様変更にも壊れない。2023年式は5段ヘッダ、2024年式は6段ヘッダと実際に違う。
iloc[5, :]でハードコードしたら 1 年でデータ更新時に止まる。 - 観測所メタは別 DataFrame に切り出す: 事務所 / 水系 / 河川 / 番号 / 観測所名 を tidy に並べた値の脇に置くのは tidy の原則違反 (1セル1値)。値は
(時刻, 観測所)の二次元、メタは(観測所, 属性)の二次元、と 2 つの DataFrame に分けて結合キーで繋ぐのが正解。 - 欠測は「ある」前提で扱う: 全 401 観測所のうち欠測のある観測所が一定数あり、横筋として現れる = センサ故障で 1 日欠測。tidy にすると
tidy.isna().mean()で即座に可視化できる。 - フラグ列は bit 単位に分解: 10分雨量側のフラグは
0x00000000(全 bit=0, 正常観測) が圧倒的で、たまに0xbe000000等の上位 bit 系が立つ (異常/補正中)。一方 累計雨量側のフラグは0x00010000(bit16) が常時立つ — これは「累計型データ」を示すマーカーと推測できる。仕様書を読まなくても出現パターンから役割を推測できるのがデータ駆動の前処理。 - 整形品質指標を残す: raw shape → tidy shape の変化、欠測率、ユニーク観測所数 を「再現可能な品質票」として残しておくと、後日「データが変わった」時にすぐ気付ける。前処理は 「やった」より「やったことを記録した」が大事。
発展課題
- 14日分を結合した縦長 tidy:
data/rain_2024/*.csv全14ファイルをparse_rain_csvで読み込み、pd.concatで時系列を 14 日分に伸ばす。L080 と同じ前処理スタイル。 - 累計雨量との突合:
tidy.cumsum()と CSV 内の累計雨量列を観測所ごとに比べて、仕様書なしで「累計雨量 = 当日 0:00 からの積算」を検証する。 - フラグ列の意味推定 → ラベル化: bit ごとの頻度から「観測ビット (常時1)」「欠測ビット (値が NaN の時のみ1)」を統計的に推定し、
flag_meaning列を tidy に追加した拡張版を作る。 - 観測所メタを使った空間集約: meta DataFrame を観測所名で結合して、水系別・河川別の日合計を算出。L080 のクロス相関分析の入力になる。
- ヘッダ仕様の自動診断レポート: 任意の DoBoX 系現場 CSV を投げると「ヘッダ何段か」「メタ列の意味推定」「データ開始行」を出力する 汎用パーサジェネレータを実装する。