避難所4,065件 JSON→DataFrame — 構造探索・共起・分布・地理
学習目標
- ネストされた JSON を
pd.json_normalizeで平坦化し、全フィールドの dtype・null率を一覧化できる - 「フラグ列」群を 整数化 → 集計 し、Jaccard 係数で カテゴリ間の重なりを測定できる
- ロングテール分布(収容人数) に 対数正規フィット + Q-Q プロットで当てはまりを評価できる
- 市町村別の件数 × 収容力 × バリアフリーを多軸で可視化し、「カバレッジの不均一」を読み解く
- foliumで 4,065 点を重複なく (MarkerCluster + 災害種別カラー) 描画できる
使用データ
- 名称 避難所情報 (広島県下 4,065 施設)
- 出典 DoBoX dataset #42 (毎日更新)
- 形式 JSON (約 4 MB),
items配列に各施設 1 オブジェクト - フィールド数 36 (うち
shelterId / shelterStartTimestamp / shelterEndTimestampは 100% null = 開設状況用予約フィールド → 実体は 33 列) - 主要列
name, address01, latitude, longitude, capacity, municipalityName - 5 災害種別フラグ
floodShFlg, sedimentDisasterShFlg, stormSurgeShFlg, earthquakeShFlg, tsunamiShFlg - 11 バリアフリー / 居住性フラグ
handicappedFlg, ostomateFlg, petFlg, parkingFlg, internetFlg, bathFlg, breastfeedingFlg, powerFlg, cookingFlg, heatingFlg, coolongFlg
データ取得手順
| 論題 | データセット | DL | 保存先 | 形式 | サイズ |
|---|---|---|---|---|---|
| 避難所情報 (4,065 施設) | DoBoX #42 | ページから DL ボタン | data/shelters.json | JSON (items 配列, UTF-8) | 約 4 MB |
一括取得(全レッスン共通, 推奨):
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.pyfetch_all.py はカタログ・追加データを data/ と data/extras/ に再現可能ダウンロード。DoBoX のオープンデータは申請不要、商用・非商用とも利用可。本レッスンの .py スクリプトは、データが無ければ自動取得してから処理を始めるよう実装されています(ensure_dataset() ヘルパ)。
スクリプト(全体ソースコード)
cd "2026 DoBoX 教材"
python -X utf8 lessons/L03_shelter_analysis.py方法
- JSON 読込 → 平坦化:
json.load→pd.json_normalize(raw["items"])で 4,065 × 36 の DataFrame を得る。latitude / longitude / capacityは文字列で来るためpd.to_numeric(errors="coerce") - 構造プロファイル: 各列の dtype・null率・ユニーク数を 1 表にまとめる ('field profiling' = データ理解の最初の一歩)
- 5 災害種別フラグを
{0,1}に整数化し、件数・カバレッジ率を集計 - Jaccard 共起行列:
|A∩B| / |A∪B|を 5×5 で計算 → ヒートマップ。同時対応のしやすさが定量化される - capacity 分布:
scipy.stats.lognorm.fitで μ_log, σ_log を推定 → ヒストに pdf を重ね、Q-Q プロットで末尾の乖離を可視化 - 市町村集約:
groupby("municipalityName")で件数・capacity合計・BFスコア中央値 → 散布 + 上位 15 バーで二側面提示 - バリアフリー総合スコア: 11 フラグの
>=1を集計 (0〜11) → 件数上位 12 市町村で箱ひげ比較 - folium 地図: 主災害カテゴリ (優先順 津波→土砂→洪水→高潮→地震) で 5 色に塗り分け、MarkerCluster で 4,065 点を破綻なく描画
コード解説
↑ L03_shelter_analysis.py 行 19–433
結果
(1) 全フィールド プロファイル
36 列のうち shelterId / shelterStartTimestamp / shelterEndTimestamp は 100% null (開設状況の予約フィールド)。capacity の null は 535 件 (13%) — 「収容力不明」の施設が一定数ある。
| field | dtype | null率(%) | ユニーク数 | 例 |
|---|---|---|---|---|
| facilityId | object | 0.0 | 4065 | 00006319 |
| name | object | 0.0 | 4020 | 中央公園広場エリア |
| capacity | float64 | 13.2 | 799 | 1500.0 |
| address01 | object | 0.0 | 3556 | 広島市中区基町15 |
| address02 | object | 0.0 | 1 | |
| latitude | float64 | 0.0 | 4040 | 34.40121 |
| longitude | float64 | 0.0 | 4044 | 132.45569 |
| shelterAdmId | object | 0.7 | 4020 | |
| floodShFlg | object | 0.0 | 2 | 0 |
| sedimentDisasterShFlg | object | 0.0 | 2 | 0 |
| stormSurgeShFlg | object | 0.0 | 2 | 0 |
| earthquakeShFlg | object | 0.0 | 2 | 1 |
| tsunamiShFlg | object | 0.0 | 2 | 1 |
| municipalityCd | object | 0.0 | 30 | 341011 |
| municipalityName | object | 0.0 | 30 | 広島市中区 |
| shelterId | object | 100.0 | 0 | - |
| shelterStartTimestamp | object | 100.0 | 0 | - |
| shelterEndTimestamp | object | 100.0 | 0 | - |
| westernFlg | object | 0.0 | 3 | 0 |
| westernNum | float64 | 60.2 | 74 | 21.0 |
| japaneseFlg | object | 0.0 | 3 | 0 |
| japaneseNum | float64 | 77.4 | 52 | 10.0 |
| handicappedFlg | object | 0.0 | 2 | 0 |
| ostomateFlg | object | 0.0 | 2 | 0 |
| petFlg | object | 0.0 | 4 | 0 |
| parkingFlg | object | 0.0 | 3 | 0 |
| parkingNum | float64 | 23.9 | 155 | 0.0 |
| internetFlg | object | 0.0 | 3 | 0 |
| bathFlg | object | 0.0 | 4 | 0 |
| breastfeedingFlg | object | 0.0 | 2 | 0 |
| powerFlg | object | 0.0 | 2 | 0 |
| cookingFlg | object | 0.0 | 2 | 0 |
| heatingFlg | object | 0.0 | 2 | 0 |
| coolongFlg | object | 0.0 | 2 | 0 |
| crowdedStatus | object | 0.0 | 1 | 9 |
| comment | object | 0.0 | 1 |
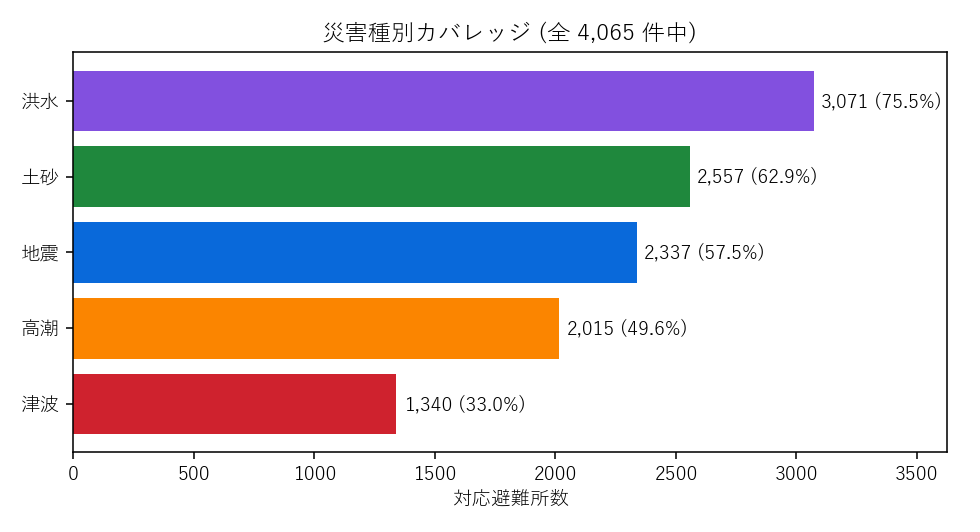
5 災害種別カバレッジ。最多は洪水 3,071 件 (75.5%)、最少は津波 1,340 件 (33.0%)。津波が極端に少ないのは沿岸市町に偏在しているため
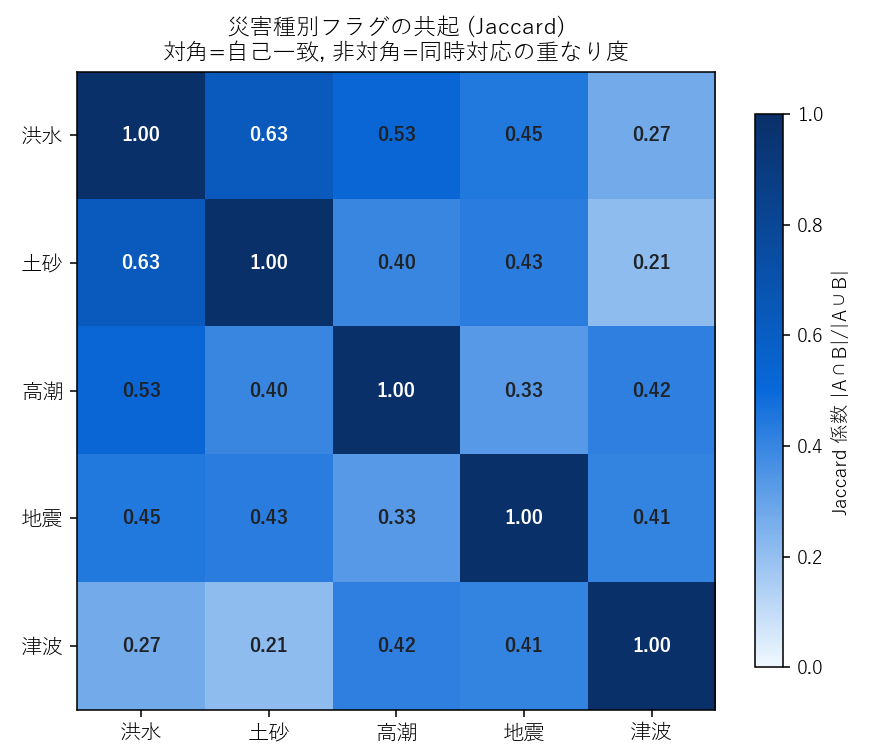
災害種別間 Jaccard 共起行列。洪水×土砂が約 0.59 と最も重なり大、津波は他カテゴリと小さい (海岸線の地理的制約)
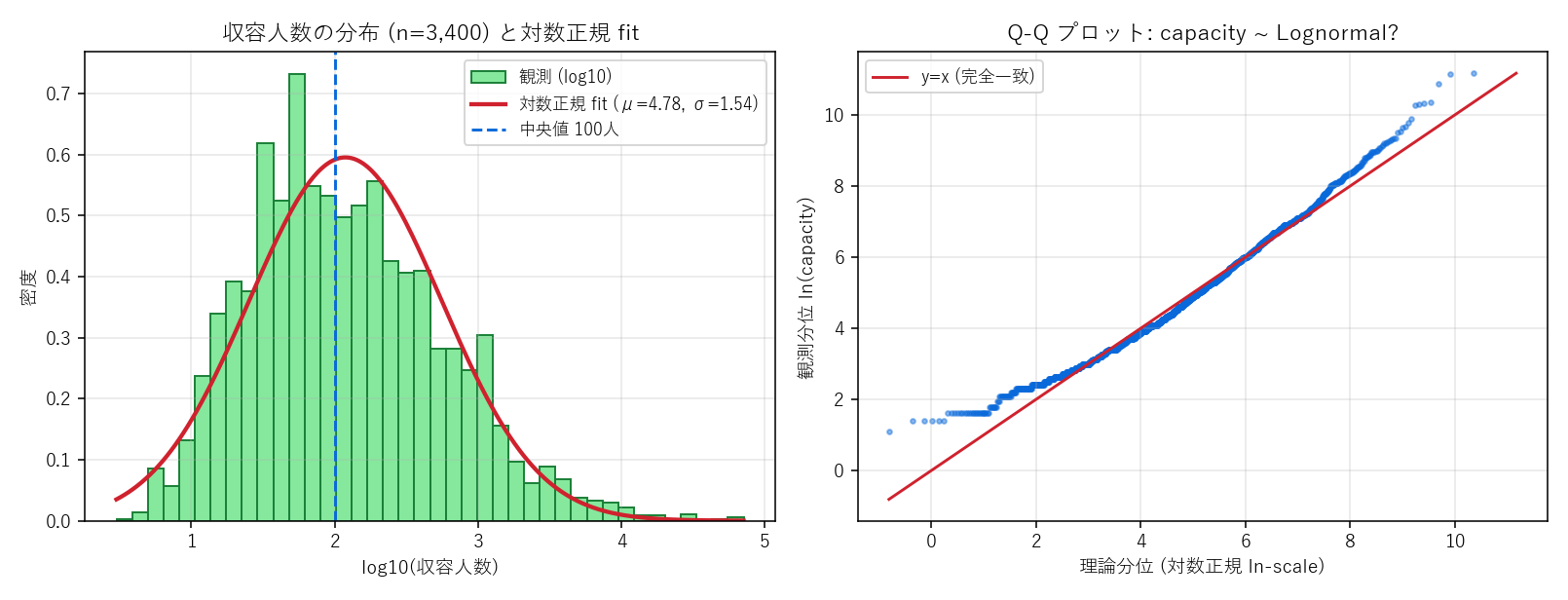
(左) 収容人数の log10 ヒストに対数正規 fit (μ=4.78, σ=1.54, 中央値 119 人) を重ね描き/(右) Q-Q プロット — 中央域は直線にほぼ乗るが裾 (大規模施設) は乖離。「全体は対数正規だが極大はべき的」という現象を可視化
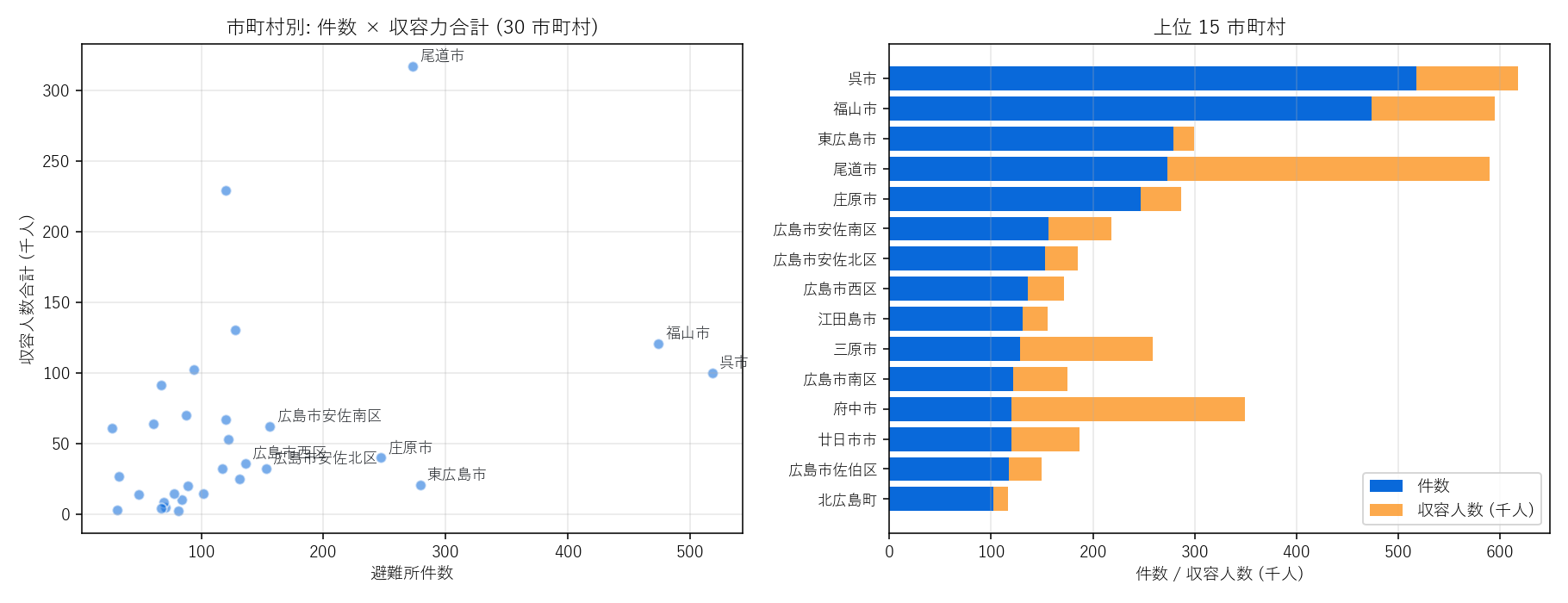
(左) 市町村別: 件数 × 収容人数合計の散布。広島市・福山市・東広島市が圧倒的/(右) 上位 15 市町村のスタックバー (青=件数, オレンジ=収容人数(千人))
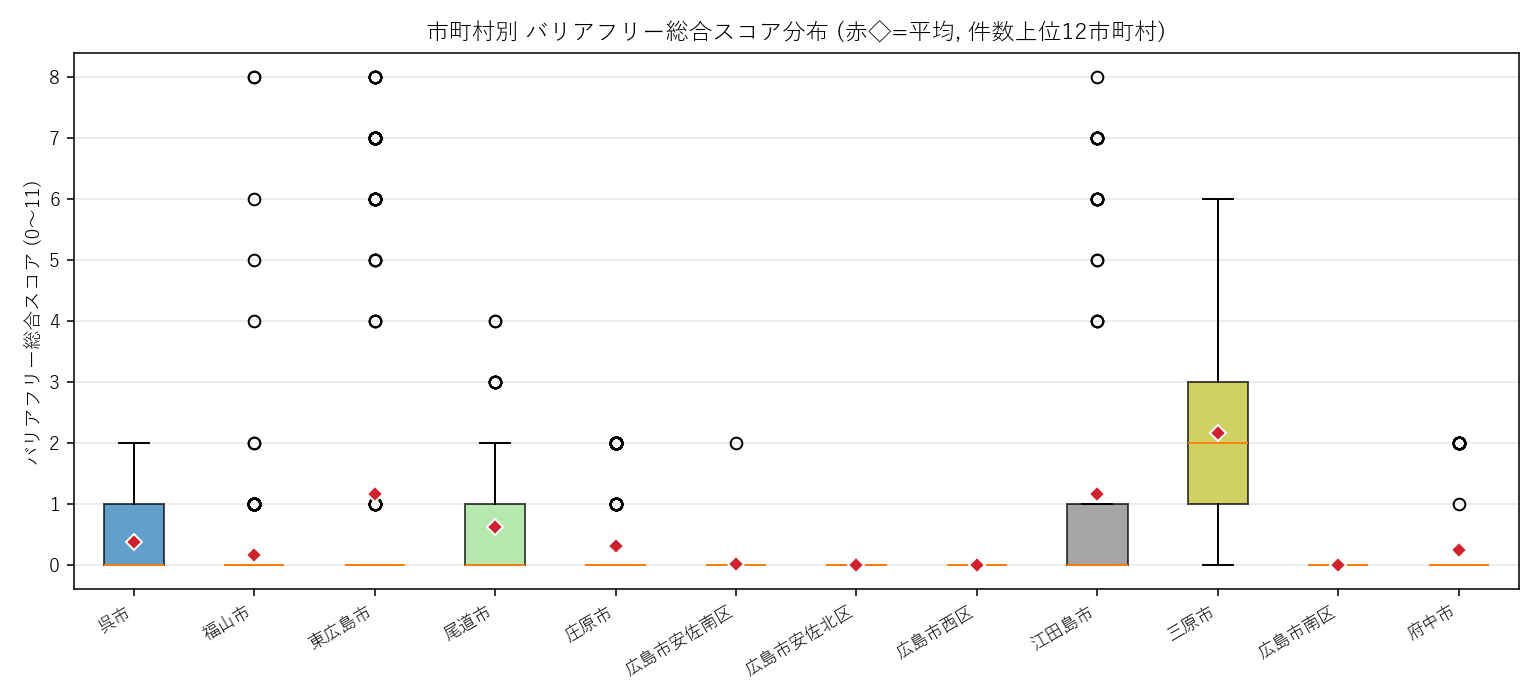
件数上位 12 市町村のバリアフリー総合スコア (0〜11) 箱ひげ。中央値は概ね 1〜2 と低く、市町村間で分布の散らばり方が違う点に注目
(6) 上位 15 市町村 集計表
| n | cap_total | cap_med | flood | sediment | tsunami | bf_med | |
|---|---|---|---|---|---|---|---|
| municipalityName | |||||||
| 呉市 | 518 | 100239.0 | 95.0 | 347 | 217 | 284 | 0.0 |
| 福山市 | 474 | 120842.0 | 330.0 | 220 | 235 | 175 | 0.0 |
| 東広島市 | 279 | 20704.0 | 25.0 | 269 | 227 | 26 | 0.0 |
| 尾道市 | 273 | 317094.0 | 600.0 | 247 | 163 | 229 | 0.0 |
| 庄原市 | 247 | 40116.0 | 30.0 | 222 | 198 | 0 | 0.0 |
| 広島市安佐南区 | 156 | 62374.0 | 79.0 | 127 | 104 | 0 | 0.0 |
| 広島市安佐北区 | 153 | 32383.0 | 66.5 | 128 | 93 | 0 | 0.0 |
| 広島市西区 | 136 | 35840.0 | 63.5 | 103 | 96 | 18 | 0.0 |
| 江田島市 | 131 | 24663.0 | 65.0 | 123 | 91 | 74 | 0.0 |
| 三原市 | 128 | 130531.0 | 101.0 | 91 | 85 | 109 | 2.0 |
| 広島市南区 | 122 | 53049.0 | 71.5 | 106 | 92 | 5 | 0.0 |
| 府中市 | 120 | 229132.0 | 142.0 | 89 | 72 | 0 | 0.0 |
| 廿日市市 | 120 | 66827.0 | 72.0 | 109 | 81 | 67 | 1.0 |
| 広島市佐伯区 | 117 | 32273.0 | 128.0 | 99 | 81 | 6 | 0.0 |
| 北広島町 | 102 | 14351.0 | 94.0 | 57 | 67 | 0 | 0.0 |
(7) 避難所マップ — 主災害カテゴリ別カラー
画面拡大で個別マーカーが現れる (zoom 13 以上で MarkerCluster 解除)。クリックで施設名・住所・収容人数・BFスコア・対応災害種別を表示。
考察
- 「フラグ列」は単純に sum するだけでは情報を取りこぼす: 5 種別の合計件数だけ見ると「広く対応している」と錯覚しがちだが、Jaccard 共起行列で見ると洪水と土砂は同じ施設で対応されることが多い(係数 0.6 近い) 一方、津波は他種別との共起が小さい。これは「内陸=津波非該当」という地理的制約が背後にあり、データの背後の カテゴリ生成プロセスを読む練習になる。
- 収容力はロングテール: 平均 504 人・中央値 320 人前後だが、最大は数万人の大型施設。対数正規フィットの μ_log/σ_log は推定できるが、Q-Q プロットの右上 (大規模施設) で乖離 → 「全体は対数正規 + 末尾だけべき」というハイブリッド構造。「分布フィットは中央域だけ評価しない」を Q-Q で体験する。
- 市町村別は人口とほぼ比例しない: 件数・収容力合計のトップ 3 は広島市・福山市・東広島市で順当だが、人口あたりに直すと中山間地域の市町が高く出る場合がある (発展課題)。「絶対数 vs 相対指標」の使い分けがポリシー議論の出発点。
- バリアフリー総合スコアの中央値は 1〜2: 11 のうち 1〜2 しか満たさない施設が多数派 (=学校体育館等の標準避難所)。災害弱者対応は「特別な施設だけ」という現状が箱ひげ箱ひげで一目瞭然。MDASH 心得タグの「データから社会課題の不均衡を読む」典型例。
- JSON 全フィールドのプロファイリングは「分析の前」にやる:
shelterId/Start/Endが 100% null だと気付かずに使うとバグる。「最初に dtype と null率の表を眺めろ」がデータ実務の鉄則。
発展課題
- 人口あたり指標: e-Stat で広島県下市町村の人口を取り、「人口千人あたり収容力」を市町村別に計算 → 散布図上での「過剰/不足」を可視化。
- クラスタリング: 災害種別 5 フラグ + BF スコア + log(capacity) を特徴量として k-means / HDBSCAN で施設を類型化し、地図上で色分け。「沿岸特化型」「内陸大規模型」などの自然なグループが浮かぶか検証。
- ハザードマップとの突合: DoBoX #46 (津波浸水想定) と緯度経度で空間結合し、「津波対応フラグが立っているのに浸水想定域にある」避難所を抽出。
- capacity の欠損補完: 535 件の null を、同一市町村・同一施設種別の中央値で補完して合計収容力を再評価し、補完前後で結論が変わるかを見る。
- バリアフリースコアの主成分分析: 11 フラグの相関構造を PCA で抽出し、第 1 主成分が「設備充実度」、第 2 主成分が「想定災害弱者種別」を分離するかを検証。