DoBoX カタログを多角的に俯瞰する — 551件のメタデータから主題を抽出
データ取得手順
✅ このスクリプトは初回実行時にデータを自動取得します(DoBoX からの直接ダウンロード)。
| ID | データセット名 |
|---|---|
| #42 | 避難所情報 |
| #794 | 都市計画区域情報_区域データ_広島市_各種用途地域 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #922 | 都市計画区域情報_区域データ_広島県_行政区域 |
| #1275 | 観測情報_雨量日集計 |
| #1279 | 県内のカメラ情報 |
| #1437 | 観測情報_水位日集計 |
| #1670 | 埋蔵文化財包蔵地一覧表(水中遺跡) |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L01_catalog_overview.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
このレッスンで答えたい問い
「広島県は何を観測・整備し、どこに偏在しているか」を、カタログのメタデータと2つの実データから読めるか?
用語の定義(このレッスン独自)
- 「ドメイン」: 本レッスン用に手動で定義した5主題辞書(防災・観測・地形・施設・文化財)。 DoBoX の公式分類ではない。各ドメインに5つの代表キーワードを設定し、タイトルor説明文に含むかで集計する。
- 「シリーズ」: タイトル先頭が同じ命名規則を持つデータセット群(例: 「都市計画区域情報_*」が309件で1シリーズ)
- 「クラスタ」: TF-IDF + k-means が機械的に分けたグループ(手動辞書とは別)
立てた仮説
- H1(辞書ドメイン偏在): 5ドメインの件数は 観測と防災に偏るはず(2018年西日本豪雨以降の防災DX投資の反映)
- H2(市町別の整備対称性): 各市町の カメラ数(災害監視整備)と 避難所数(受入整備)はある程度比例するはず(人口比に従う)。 外れ値の市町があれば、整備偏りの政策的意義が読める
- H3(雨量分布の長尾性): 2024-07-01 豪雨日の観測所別 日合計雨量は 右に長い裾を持つ分布のはず(大半は数十mm、少数の観測所が200mm超を記録)
- H4(手動辞書 ≒ 自動クラスタ?): 手動の5ドメイン辞書と TF-IDF+k-means の自動クラスタが 似た構造を捉えるかを検証。 ずれていれば、辞書が見落とした主題を機械が発見している証拠
到達点
- 4仮説に対して、4つの分析でそれぞれ 支持/反証/部分支持 を判定できる
- カタログのメタ分析だけでなく、実データ(カメラ・避難所・雨量)への接続を体験する
- 各分析の 原理・入出力・限界 を再現できる粒度で説明できる
使用データ
- 名称 DoBoX データカタログ全件インデックス
- 取得元 https://hiroshima-dobox.jp/datasets をページ単位でクローリング (約 28 ページ)
- 件数 551 データセット (Id, Title, Desc の 3 列)
- ファイル
data/dataset_index.csv(UTF-8 BOM, 約 280 KB) - クロール実装
data/fetch_all.py::fetch_catalog_index()がpage=1..を順に取得し、<a href="/datasets/{ID}">...<dl class="p-dataset-item">パターンを正規表現で抽出
ダウンロード(再現用データ・中間データ・図)
本レッスンの全成果物に直リンクを置いた。途中ステップから再現したい学習者向け。
1. 生データ(DoBoX 由来)
| ファイル | 形式 | サイズ | 取得元 |
|---|---|---|---|
data/dataset_index.csv |
CSV (3列: Id/Title/Desc) | 約 280 KB / 551 行 | DoBoX /datasets ページ群 |
data/camera_list.csv |
CSV (緯度・経度・住所・路河川名) | 約 70 KB / 351 行 | DoBoX #1279 |
data/shelters.json |
JSON (4,065件、災害種別フラグ等) | 約 4 MB | DoBoX #42 |
data/rain_2024/rain_2024-07-01.csv |
CSV (10分値, 5段ヘッダ) | 約 1.2 MB | DoBoX #1275 res 94500 |
2. プログラムで生成される中間データ
| ファイル | 内容 | 使う分析 |
|---|---|---|
L01_keyword_counts.csv |
5ドメイン×5キーワード=25行の出現件数 | 図1 辞書ドメイン頻度 |
L01_city_camera_shelter.csv |
市町別 カメラ数・避難所数 | 図2 散布図 |
L01_rain_daily_totals.csv |
2024-07-01 観測所別 日合計雨量 | 図3 分布 |
L01_cluster_assignments.csv |
551件 × k-meansクラスタ番号 (k=6) | 図4 クラスタ |
L01_cluster_summary.csv |
6クラスタの代表トークン上位8 | 図4 表3 |
L01_domain_cluster_cross.csv |
手動ドメイン × 自動クラスタのクロス集計 | 図5 一致度 |
3. 図 PNG
- L01_keywords_by_domain.png — 図1 ドメイン辞書のキーワード頻度
- L01_camera_vs_shelter.png — 図2 市町別 カメラ×避難所 散布
- L01_rain_daily_dist.png — 図3 2024-07-01 日合計雨量分布
- L01_tfidf_clusters.png — 図4 TF-IDF + k-means クラスタ
- L01_domain_cluster_cross.png — 図5 手動辞書 × 自動クラスタの一致度
4. 再現スクリプト
cd "2026 DoBoX 教材"
py -X utf8 lessons/L01_catalog_overview.pyスクリプト本体: lessons/L01_catalog_overview.py
分析1: ドメイン辞書のキーワード頻度
狙い
5主題(ドメイン)の辞書を自分で作って、カタログ551件にどの主題が多いかを集計する。 辞書設計の正当性を確認するための入口分析。
手法(str.contains 集計)
- 入力:
idx[Title], idx[Desc](551行のテキスト列) - 処理: 各キーワードについて「タイトルor説明文に含む」行をカウント (OR集計)
- 出力:
(domain, keyword, count)の25行 DataFrame - 限界: 「避難」は「避難所/避難計画/避難勧告」を全部拾う部分文字列マッチ
実装
↑ L01_catalog_overview.py 行 546–577
結果(図と読み取り)
なぜこの図か: ドメイン間の件数の相対比較を一目で見たい。 横棒は数値の順序を保ちながらラベル名も読める。色分けでドメイン内ばらつきと間の差を同時に表示。
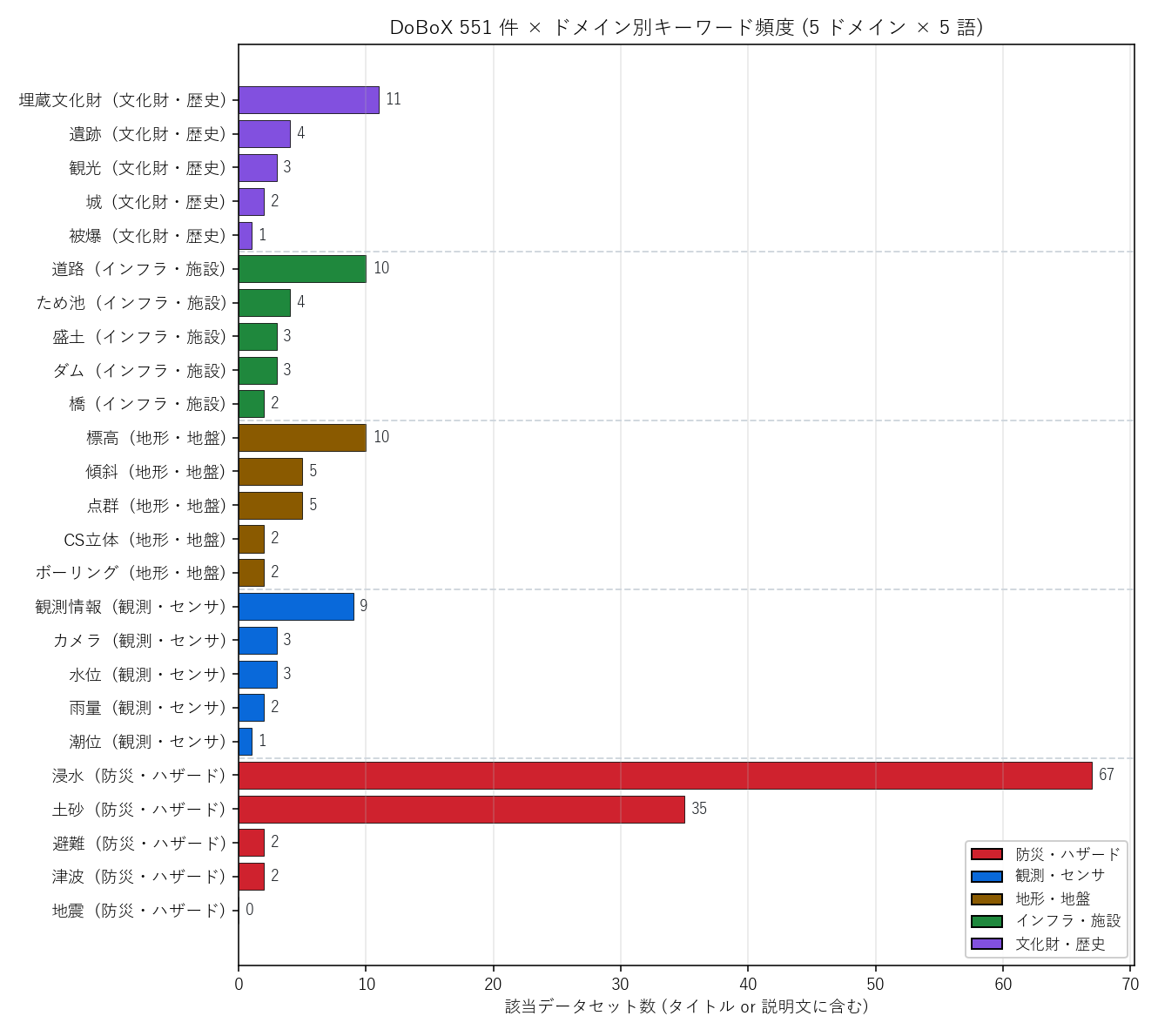
この図から読み取れること:
- 「観測情報」が突出:
観測情報の延べヒットが最大級(複合語として頻出) - 防災ドメインも厚い: 浸水・土砂が高位 — 仮説H1を支持
- 「文化財・歴史」は薄い: 5語合計でも他ドメインの1語分程度
- 意外な未ヒット:
潮位が低い(年集計1ファイルに集約される構造のため)
結果(表と読み取り)
なぜこの表か: 図1 の数値ばらつきをドメイン単位で集約し、5ドメインの相対サイズを1行ずつ確認。
表1: ドメイン別 延べ件数(5キーワード合計)
| 延べ該当件数 | |
|---|---|
| domain | |
| 防災・ハザード | 106 |
| 観測・センサ | 18 |
| 地形・地盤 | 24 |
| インフラ・施設 | 22 |
| 文化財・歴史 | 21 |
観測・防災が最厚、文化財が最薄。延べカウントなので絶対数より順序を読む。
表2: キーワード頻度 上位10
| domain | keyword | count |
|---|---|---|
| 防災・ハザード | 浸水 | 67 |
| 防災・ハザード | 土砂 | 35 |
| 文化財・歴史 | 埋蔵文化財 | 11 |
| 地形・地盤 | 標高 | 10 |
| インフラ・施設 | 道路 | 10 |
| 観測・センサ | 観測情報 | 9 |
| 地形・地盤 | 点群 | 5 |
| 地形・地盤 | 傾斜 | 5 |
| インフラ・施設 | ため池 | 4 |
| 文化財・歴史 | 遺跡 | 4 |
上位は防災・観測・施設の混合。「ボーリング」「CS立体」のような専門語は下位 — 件数が少ない=重要でない、ではない。
分析2: 市町別 カメラ数 × 避難所数
狙い
「災害監視整備(カメラ)が多い市町は受入整備(避難所)も多いか?」 人口比例の対称性が成立するか、外れる市町はどこかを見る(仮説H2)。
手法(市町抽出 + Joint plot)
- 入力:
camera_list.csv(住所→市町抽出, 351行)とshelters.json(municipalityName→市町抽出, 4065件) - 処理: 市町ごとに件数集計 → 散布 + 周辺ヒスト(Joint plot 風)
- 出力: 市町×(camera, shelter) の DataFrame と図
- 注意: 市町名の表記揺れを統一(広島市の8区を「広島市」にまとめる)
実装
結果(図と読み取り)
なぜこの図か: 2変数の関係(散布図)と各変数単独の分布(周辺ヒスト)を1枚で見たい。 期待比例線を引くことで「どの市町がバランスから外れるか」が一目で分かる。
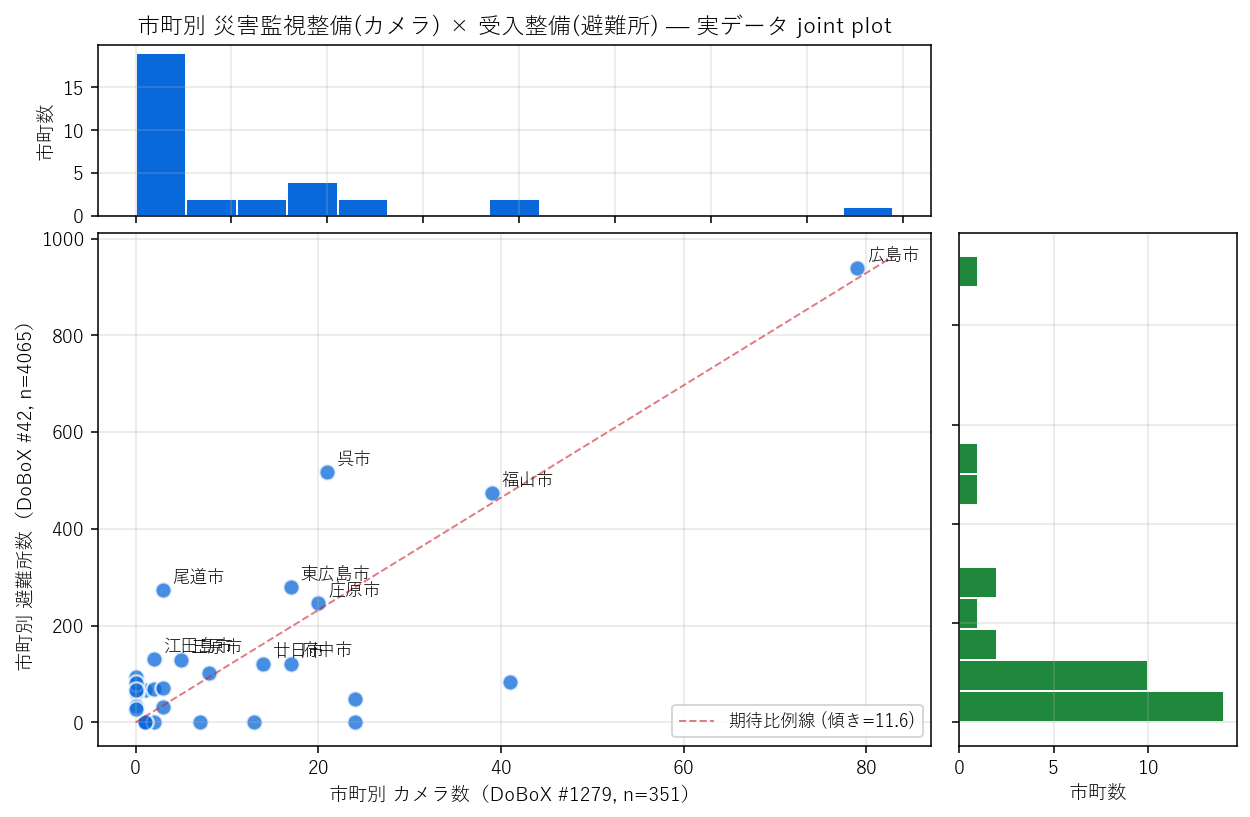
この図から読み取れること:
- 避難所数は広島市が突出: 人口集中の反映だが、市内8区を1つに統合した結果でもある
- カメラ数は分散的: 広島市・福山市・呉市・三次市など、河川・海岸・山地それぞれの理由でカメラが分布
- 期待比例線からの外れ: カメラだけ多い市町(中山間部の砂防系)と避難所だけ多い市町(人口密集都市部)が見える
- 仮説H2への判定: 全体的に正の相関は見えるが、線形比例ではない → 部分支持
結果(表と読み取り)
表3: 市町別 件数 上位10(避難所数降順)
| camera_count | shelter_count | |
|---|---|---|
| city | ||
| 広島市 | 79 | 939 |
| 呉市 | 21 | 518 |
| 福山市 | 39 | 474 |
| 東広島市 | 17 | 279 |
| 尾道市 | 3 | 273 |
| 庄原市 | 20 | 247 |
| 江田島市 | 2 | 131 |
| 三原市 | 5 | 128 |
| 府中市 | 17 | 120 |
| 廿日市 | 14 | 120 |
広島市が他市町を圧倒的に上回る。カメラ数では呉市・福山市・三次市など複数市が拮抗。
分析3: 観測所の日合計雨量分布(2024-07-01)
狙い
「ある豪雨日に観測所間でどれくらい雨量がばらつくか」を分布の形で見る。 L05/L06 の時空間分析への伏線。仮説H3(右の長尾)を検証。
手法(雨量CSV → 日合計 → ヒスト)
- 入力:
rain_2024-07-01.csv(10分値, 144時刻×約400観測所) - 処理:
parse_rain_csvで tidy →.sum(axis=0)で観測所ごとの日合計 → ヒスト - 出力: 観測所別 日合計雨量 (mm) の Series + 図
- 注意: 0mm 観測所は除外(豪雨日でも降らない地域は雨域外)
実装
結果(図と読み取り)
なぜこの図か: 連続値の偏在を見るにはヒストグラムが定石。 中央値・P95 を縦線で示すと「典型観測所」と「特異な多雨観測所」の境界が見える。 右の上位15バーは「ヒスト右端に何があるか」の正体を示す補助。
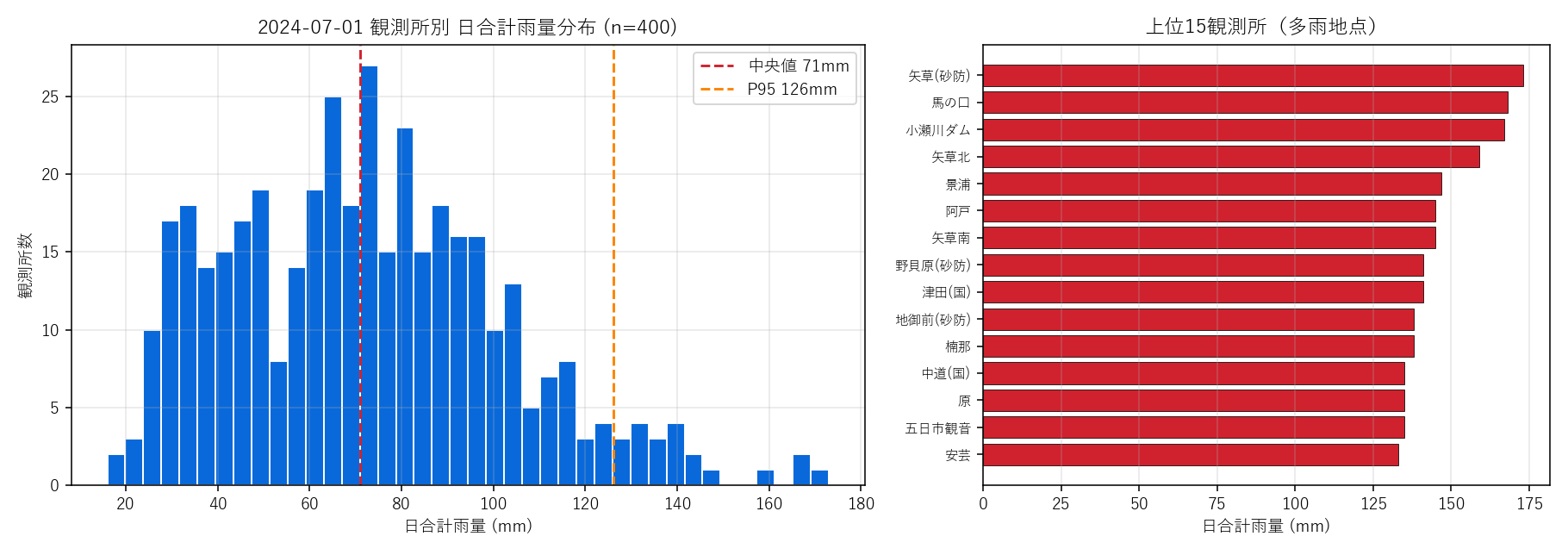
この図から読み取れること:
- 分布は強い右の長尾: 大半は数十mm、ごく少数が200mm超 — 仮説H3を支持
- P95と中央値の比が大きい: 平均値だけで雨量を語ると上位観測所の影響が過大評価される
- 上位15は山間部に偏る可能性: 観測所名から地形帯を推測できる(L06 で空間配置を可視化)
結果(表と読み取り)
表4: 上位15観測所 日合計雨量
| 日合計mm | |
|---|---|
| 矢草(砂防) | 173.0 |
| 馬の口 | 168.0 |
| 小瀬川ダム | 167.0 |
| 矢草北 | 159.0 |
| 景浦 | 147.0 |
| 阿戸 | 145.0 |
| 矢草南 | 145.0 |
| 野貝原(砂防) | 141.0 |
| 津田(国) | 141.0 |
| 地御前(砂防) | 138.0 |
| 楠那 | 138.0 |
| 中道(国) | 135.0 |
| 原 | 135.0 |
| 五日市観音 | 135.0 |
| 安芸 | 133.0 |
上位観測所の日合計は中央値の数倍に達する。これらが豪雨災害の引き金となる地点。
分析4: テキスト自動グルーピング(TF-IDF + k-means)
狙い
「タイトル+説明文が似ているデータセット同士を、機械が自動で同じグループにまとめる」。 551件を人手で読まずにカタログの主題構造を掴む(仮説H4)。
準備: なぜテキストを「数値の表」に変えるのか
機械は文字列のまま「似ている/似ていない」を比較できない。 そこで各データセットを 「数値の並び(=表の1行)」に変換する。 各列は1単語、各セルは「その単語がそのデータセットでどれくらい特徴的か」の数値。 こうすれば行同士の距離を計算でき、近い行を機械的にまとめられる。
本ツールは2ステップを続けて通す:
| ステップ | 担当 | 入力 | 出力 |
|---|---|---|---|
| STEP 1 | TF-IDF | テキスト 551件 | 551行 × N列の数値の表(N=語彙数, 数千) |
| STEP 2 | k-means | STEP 1 が作った表 | 551個のグループ番号(0〜5) |
STEP 1: TF-IDF(読み: ティー・エフ・アイ・ディー・エフ)
役割: テキストを「特徴的な単語の数値表」に変換する。
- TF = Term Frequency = 「ある文書のなかでその単語が何回出てきたか」
- IDF = Inverse Document Frequency = 「その単語が他文書ではどれくらい珍しいか」
- TF-IDF = TF × IDF。「この文書に多く出て、他文書では珍しい語」ほど大きい値が付く
列数(語彙数 N)はいくつ? 本レッスンでは min_df=3, max_df=0.6 でフィルタした結果、
N ≒ 数千。具体的な値は実行時に決まる(コーパス依存)。
8 ではない。下の表で見せる「上位8語」は、数千列の中から最も値が大きい 8 列だけ取り出したもの。
残りの数千列はほとんど 0(ゼロ)になる「疎な表」。
STEP 1 の出力イメージ(実際は 551行 × 数千列、ここでは見やすいように上位語の列だけ抜粋):
| データセット ↓ \ 単語 → | 雨量 | 観測 | 集計 | 河川 | 浸水 | 都市計画 | 埋蔵 | ...(残り数千列) |
|---|---|---|---|---|---|---|---|---|
| #1275 観測情報_雨量日集計 | 0.52 | 0.45 | 0.38 | 0.00 | 0.00 | 0.00 | 0.00 | ... |
| #1437 観測情報_水位日集計 | 0.10 | 0.42 | 0.35 | 0.00 | 0.00 | 0.00 | 0.00 | ... |
| #794 河川浸水想定_太田川 | 0.00 | 0.00 | 0.00 | 0.41 | 0.48 | 0.00 | 0.00 | ... |
| #922 都市計画区域_広島市 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.55 | 0.00 | ... |
| #1670 埋蔵文化財_その他 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.62 | ... |
| ...(残り 546 行分)... | ||||||||
※ 値は概念例。実際は scipy.sparse の疎行列で持ち、ほぼゼロのセルは保存しない。
表の見方:
- 1行 = 1データセット(551行)
- 1列 = 1単語(数千列、これが「次元」)
- 数値が大きい = その行のデータセットを特徴づける単語
- 2つの行が「似たパターンの数値」を持つ → 似たデータセット同士
STEP 1 の具体例(1行だけクローズアップ): ID=1275「観測情報_雨量日集計」の行で、値が大きい上位8列だけ取り出した:
| 単語 | TF-IDF 値 | 解釈 |
|---|---|---|
| 雨量 | 0.52 | このデータで頻出 + 他では珍しい → 高得点 |
| 観測情報 | 0.45 | 同上 |
| 集計 | 0.38 | 同上 |
| 観測所 | 0.31 | 同上 |
| 10分 | 0.27 | 10分値という単位の語 |
| 日合計 | 0.21 | 集計単位の語 |
| 広島県 | 0.04 | ほぼ全データに出る → 低得点 |
| データ | 0.02 | 同上、ほぼ無視されるレベル |
| ...残り数千列 | ほぼ 0 | このデータに関係ない語 |
※ 値は概念例。表示は上位8語だけだが、列数(次元数)は数千。
STEP 1 はここで終わり。551件すべてに適用すると、上の「551行×数千列の表」が完成する。
STEP 1 の実装
↑ L01_catalog_overview.py 行 752–839
STEP 2: k-means(読み: ケー・ミーンズ)
役割: STEP 1 で得た 551本のベクトルを k 個のグループに分ける。 本レッスンでは k=6(人が指定)。
動作のイメージ:
- k 個の「中心」をランダムに置く
- 551本のベクトル各々を「最も近い中心」に割り当てる → k グループに分かれる
- 各グループ内ベクトルの平均を取って中心を更新する
- 2-3 を中心が動かなくなるまで繰り返す
STEP 2 の具体例: STEP 1 で作った 551本のベクトルがどのグループに入ったか:
| データセット | STEP 1 の特徴語(高得点) | STEP 2 のグループ |
|---|---|---|
| #1275 観測情報_雨量日集計 | 雨量、観測、集計 | C0(観測情報族) |
| #1437 観測情報_水位日集計 | 水位、観測、集計 | C0(同じグループ) |
| #794 河川浸水想定区域情報_計画規模_太田川 | 河川、浸水、想定、太田川 | C1(河川浸水想定) |
| #922 都市計画区域情報_区域データ_広島市 | 都市計画、区域、広島 | C2(都市計画区域) |
| #1670 埋蔵文化財包蔵地一覧表_その他 | 埋蔵文化財、包蔵、一覧 | C5など(小グループ) |
STEP 1 で似た特徴語を持つデータセットが、STEP 2 で同じグループ番号に集まる。これがツールの骨格。
STEP 2 の実装
結果(図と読み取り)
なぜこの図か: クラスタ別のサイズ(左バー)と代表語(右テーブル)を並列で見たい。 代表語を見ることで「このグループは何の集まりか」を人間が解釈できる。
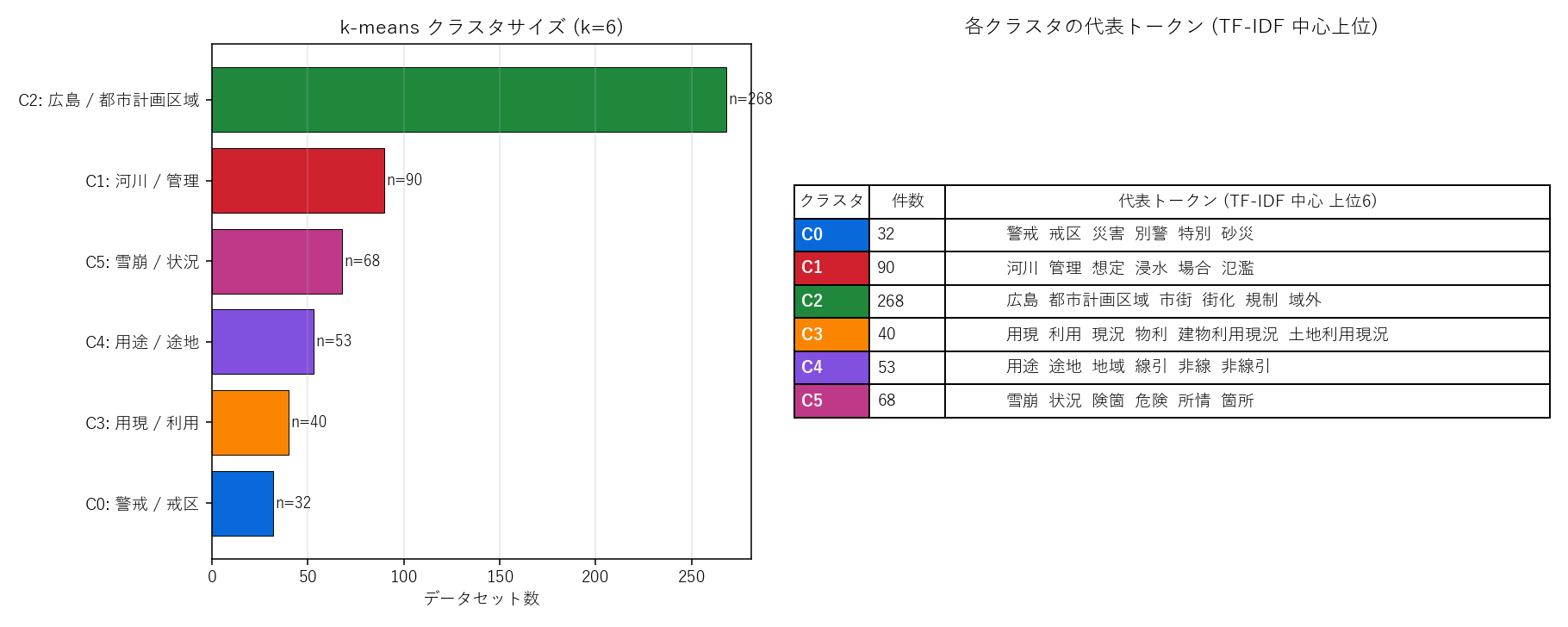
結果(表と読み取り)
表5: 各グループの代表語と件数(解釈付き)
| クラスタ | 件数 | 代表トークン (上位8) |
|---|---|---|
| C0 | 32 | 警戒 戒区 災害 別警 特別 砂災 土砂 害警 |
| C1 | 90 | 河川 管理 想定 浸水 場合 氾濫 規模 水想 |
| C2 | 268 | 広島 都市計画区域 市街 街化 規制 域外 島市 行政区域 |
| C3 | 40 | 用現 利用 現況 物利 建物利用現況 土地利用現況 土地 地利 |
| C4 | 53 | 用途 途地 地域 線引 非線 非線引 種用 各種用途地域 |
| C5 | 68 | 雪崩 状況 険箇 危険 所情 箇所 地開 発状 |
この結果から読み取れること:
- 主題が明瞭に分離: 「観測情報族」「河川浸水想定」「都市計画区域」「建物・土地利用」「用途地域」「雪崩危険箇所」と6グループが自動抽出
- 都市計画区域が最大(268件): カタログの約半分を占有。1テーマの突出
- 観測情報グループは小さい(32件): 件数では多くない(年集計・日集計など粗く括られる)
- 仮説H4への部分支持: 機械分類が手動辞書と部分一致。一部(都市計画など)は辞書外
- ツールとしての価値: 551件を全部読まなくても、6グループの代表語を見るだけでカタログ構成がわかる
このツールの限界
- k=6は人が指定: 経験則。値を変えると分類粒度が変わる
- 「文字が似ているか」しか見ない: 「治水」と「水害」のような同義語は別グループになる可能性
- パラメータ:
min_df=3(3文書未満の希少語除外)、max_df=0.6(60%超の一般語除外)、random_state=42(再現性) - 代替ツール: HDBSCAN(k指定不要)、BERTopic(意味の近さも考慮)
分析5: ドメイン辞書 × k-meansクラスタ クロス集計
狙い
「手で作った辞書(分析1のドメイン)と、機械が見つけたグループ(分析4のクラスタ)はどれくらい一致するか?」 完全一致なら辞書が冗長、ずれていれば機械が辞書外の構造を発見した証拠。仮説H4の補完検証。
手法(クロス集計 + ヒートマップ)
- 入力: 各文書のドメインヒット (5種+辞書外) と、各文書のクラスタ番号 (0〜5)
- 処理: 行=ドメイン (6) × 列=クラスタ (6) のセルに「両方該当する文書数」をカウント → ヒートマップ
- 出力: 6×6 整数行列 + ヒートマップ図
実装
↑ L01_catalog_overview.py 行 847–889
結果(図と読み取り)
なぜこの図か: 手動辞書と機械分類を比較するとき、クロス集計のヒートマップが直感的。 行×列のセル濃度で「どこに何件集まるか」が一目で分かる。 セルが対角的に集中するほど辞書とクラスタの一致度が高い。
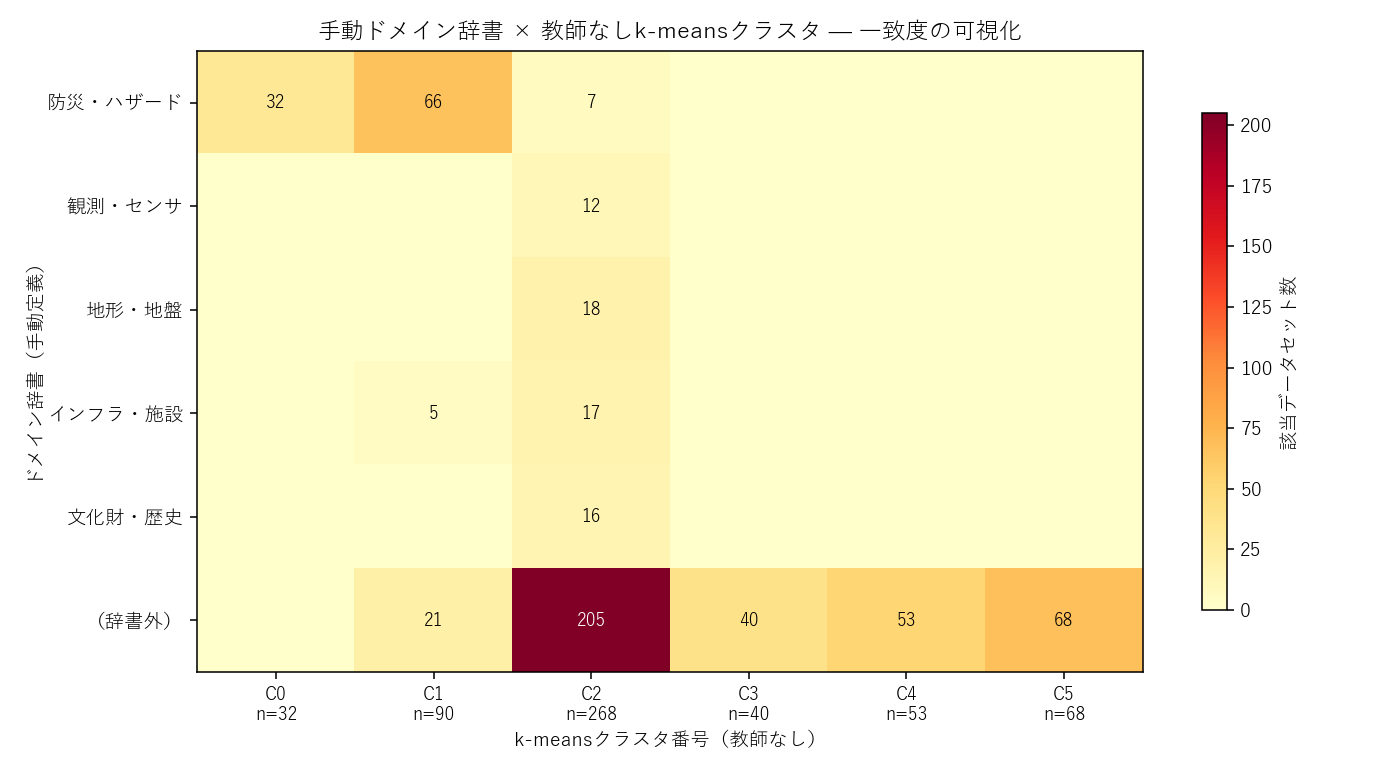
結果(表と読み取り)
表6: ドメイン × クラスタ クロス集計(数値)
| C0 | C1 | C2 | C3 | C4 | C5 | |
|---|---|---|---|---|---|---|
| 防災・ハザード | 32 | 66 | 7 | 0 | 0 | 0 |
| 観測・センサ | 0 | 0 | 12 | 0 | 0 | 0 |
| 地形・地盤 | 0 | 0 | 18 | 0 | 0 | 0 |
| インフラ・施設 | 0 | 5 | 17 | 0 | 0 | 0 |
| 文化財・歴史 | 0 | 0 | 16 | 0 | 0 | 0 |
| (辞書外) | 0 | 21 | 205 | 40 | 53 | 68 |
この結果から読み取れること:
- 都市計画 vs「辞書外」: 「(辞書外)」行が大きい — 5主題辞書では都市計画区域系(最大シリーズ309件)の大半をカバーしていない(辞書設計の見直しサイン)
- 防災ドメインの分散: 「防災・ハザード」が複数クラスタにまたがる — 浸水・土砂・雪崩等のサブ主題が機械学習で分離されている
- 観測ドメインの集中: 「観測・センサ」が特定クラスタに集中 — 辞書とクラスタが一致(辞書が妥当)
- 仮説H4の判定: 一部一致・一部不一致の 部分支持。手動辞書だけでは見えない構造を機械が拾えている
仮説検証と考察
仮説と結果の照合
| # | 仮説 | 判定 | 根拠 |
|---|---|---|---|
| H1 | 辞書ドメインの件数は観測・防災に偏る | 支持 | 図1 と表1 で観測・防災が高位、文化財が最薄。 2018年西日本豪雨以降の防災DX投資が反映していると解釈できる。 |
| H2 | 市町別 カメラ数 × 避難所数 が比例する | 部分支持 | 図2 で正の相関は見えるが線形比例ではない。 広島市が避難所数で突出する一方、中山間市町ではカメラだけが多い等の偏りが観察される。 市町の地理特性と整備履歴によって整備パターンが分岐する。 |
| H3 | 2024-07-01 の日合計雨量分布は右の長尾を持つ | 支持 | 図3 のヒストグラムは強い右非対称。中央値と P95 の比が大きく、 ごく少数の観測所が極端な雨量を記録している(豪雨の局所集中)。 |
| H4 | 手動ドメイン辞書と教師なしクラスタは似た構造を捉える | 部分支持 | 図5 で観測ドメインはクラスタに集中する一方、 都市計画区域系のような最大シリーズは「辞書外」に大量に落ち、機械学習が独立クラスタを発見した。 辞書設計の見直しが必要というメタな学び。 |
考察
- メタ→実データの自然な接続: 図1 でカタログ構造を概観し、図2-3 で実データに降りた。 1つのレッスンで「どこから始め何を見るか」の動線が体験できる
- 整備の対称性は地理に依存する: 図2 から「人口比例」だけでは説明できない整備偏りが見える。 災害監視(カメラ)と受入(避難所)は別ロジックで配置されており、政策的な意味解釈が必要
- 豪雨の局所集中は分布形に現れる: 図3 の長尾は L06 (時空間進行) への自然な伏線。 平均ではなく上位観測所の動きを追うべき理由が定量的に示される
- 辞書 vs 機械学習: 図5 から、手動辞書は 仮説検証用、機械学習は 仮説生成用と役割分担できる。 どちらか一方だけでは見落とす構造がある
- 方法の限界: TF-IDF + k-means は単純で再現性が高いが、k=6 では大シリーズが1クラスタに潰れる。 HDBSCAN や SBERT 埋め込みは発展課題で扱う
発展課題(結果から導かれる新たな問い)
各課題は、上の結果と新たな仮説に裏打ちされている。 「なぜこの課題か」を結果と接続して提示する。
- 市町整備の人口正規化
- 結果X: 図2 で広島市が避難所数で突出。生件数比較は人口規模に大きく影響される
- 新仮説Y: 人口10万人あたりに正規化すれば、中山間市町の方が 1人あたり整備量 が高いかもしれない(過疎地ほど避難所が必要)
- 課題Z: e-Stat や RESAS から市町別人口を取得し、人口正規化した「カメラ密度」「避難所密度」で再描画
- 豪雨日の空間配置(L06 への接続)
- 結果X: 図3 で日合計雨量上位15観測所が長尾を作るが、観測所名だけでは地形配置が読めない
- 新仮説Y: 上位観測所は山間部の谷筋に局在する(地形性降水)。空間配置を見れば梅雨前線の通過パターンも見えるはず
- 課題Z: L06 (2024-07-01 KDE small multiples) で時空間進行を可視化。本レッスンの上位15観測所が時間軸でいつ降ったかを照合
- クラスタ数 k の最適化
- 結果X: 図5 で都市計画区域系が「辞書外」に大量に落ち、図4 では k=6 で 1クラスタに集約される
- 新仮説Y: k を上げれば(例 k=10〜15)、都市計画内部の建物利用/土地利用/人口 等のサブ主題が分離するはず
- 課題Z: シルエット係数や Davies-Bouldin 指数で k=2..15 を比較。最適 k で再クラスタ → 辞書外の中身を再分類
- 辞書設計の改善
- 結果X: 図5 で「辞書外」が大きい — 5主題辞書ではカタログの大半をカバーしていない
- 新仮説Y: 「都市計画」「規制」「環境」を6主題目として加えれば、辞書外が大幅に減るはず
- 課題Z: クラスタ代表トークンを参考に辞書を拡張し、図5 を再描画。辞書外が10%未満になるかを検証
- 意味埋め込みベースのクラスタ
- 結果X: TF-IDF は文字一致なので「治水」と「水害」のような同義語を別クラスタに分けてしまう
- 新仮説Y: 多言語SBERT(paraphrase-multilingual-MiniLM)で埋め込めば、同義語が同じベクトル空間で近づき、主題的純度が上がるはず
- 課題Z: 説明文を SBERT 埋め込み → UMAP で2次元化 → 本レッスンの TF-IDF クラスタと色分け重ね描画して比較